溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關GBDT和XGBoost的區別是什么,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
1 傳統GBDT以CART作為基分類器,xgboost還支持線性分類器,這個時候xgboost相當于帶L1和L2正則化項的邏輯斯蒂回歸(分類問題)或者線性回歸(回歸問題)。
2 傳統GBDT在優化時只用到一階導數信息,xgboost則對代價函數進行了二階泰勒展開,同時用到了一階和二階導數。順便提一下,xgboost工具支持自定義代價函數,只要函數可一階和二階求導。
3 xgboost在代價函數里加入了正則項,用于控制模型的復雜度。正則項里包含了樹的葉子節點個數、每個葉子節點上輸出的score的L2模的平方和。從Bias-variance tradeoff角度來講,正則項降低了模型的variance,使學習出來的模型更加簡單,防止過擬合,這也是xgboost優于傳統GBDT的一個特性。(關于這個點,接下來詳細解釋)
4 Shrinkage(縮減),相當于學習速率(xgboost中的eta)。xgboost在進行完一次迭代后,會將葉子節點的權重乘上該系數,主要是為了削弱每棵樹的影響,讓后面有更大的學習空間。實際應用中,一般把eta設置得小一點,然后迭代次數設置得大一點。(補充:傳統GBDT的實現也有學習速率)
5 列抽樣(column subsampling)即特征抽樣。xgboost借鑒了隨機森林的做法,支持列抽樣,不僅能降低過擬合,還能減少計算,這也是xgboost異于傳統gbdt的一個特性。
6 對缺失值的處理。對于特征的值有缺失的樣本,xgboost可以自動學習出它的分裂方向。
7 xgboost工具支持并行。boosting不是一種串行的結構嗎?怎么并行的?注意xgboost的并行不是tree粒度的并行,xgboost也是一次迭代完才能進行下一次迭代的(第t次迭代的代價函數里包含了前面t-1次迭代的預測值)。xgboost的并行是在特征粒度上的。
我們知道,決策樹的學習最耗時的一個步驟就是對特征的值進行排序(因為要確定最佳分割點),xgboost在訓練之前,預先對數據進行了排序,然后保存為block結構,后面的迭代中重復地使用這個結構,大大減小計算量。這個block結構也使得并行成為了可能,在進行節點的分裂時,需要計算每個特征的增益,最終選增益最大的那個特征去做分裂,那么各個特征的增益計算就可以開多線程進行。
可并行的近似直方圖算法。樹節點在進行分裂時,我們需要計算每個特征的每個分割點對應的增益,即用貪心法枚舉所有可能的分割點。當數據無法一次載入內存或者在分布式情況下,貪心算法效率就會變得很低,所以xgboost還提出了一種可并行的近似直方圖算法,用于高效地生成候選的分割點。
補充
xgboost/gbdt在調參時為什么樹的深度很少就能達到很高的精度?用xgboost/gbdt在在調參的時候把樹的最大深度調成6就有很高的精度了。但是用DecisionTree/RandomForest的時候需要把樹的深度調到15或更高。用RandomForest所需要的樹的深度和DecisionTree一樣我能理解,因為它是用bagging的方法把DecisionTree組合在一起,相當于做了多次DecisionTree一樣。但是xgboost/gbdt僅僅用梯度上升法就能用6個節點的深度達到很高的預測精度,使我驚訝到懷疑它是黑科技了。請問下xgboost/gbdt是怎么做到的?它的節點和一般的DecisionTree不同嗎?
這是一個非常好的問題,題主對各算法的學習非常細致透徹,問的問題也關系到這兩個算法的本質。這個問題其實并不是一個很簡單的問題,我嘗試用我淺薄的機器學習知識對這個問題進行回答。
?
一句話的解釋,來自周志華老師的機器學習教科書( 機器學習-周志華):Boosting主要關注降低偏差,因此Boosting能基于泛化性能相當弱的學習器構建出很強的集成;Bagging主要關注降低方差,因此它在不剪枝的決策樹、神經網絡等學習器上效用更為明顯。
隨機森林(random forest)和GBDT都是屬于集成學習(ensemble learning)的范疇。集成學習下有兩個重要的策略Bagging和Boosting。
Bagging算法是這樣做的:每個分類器都隨機從原樣本中做有放回的采樣,然后分別在這些采樣后的樣本上訓練分類器,然后再把這些分類器組合起來。簡單的多數投票一般就可以。其代表算法是隨機森林。Boosting的意思是這樣,他通過迭代地訓練一系列的分類器,每個分類器采用的樣本分布都和上一輪的學習結果有關。其代表算法是AdaBoost, GBDT。
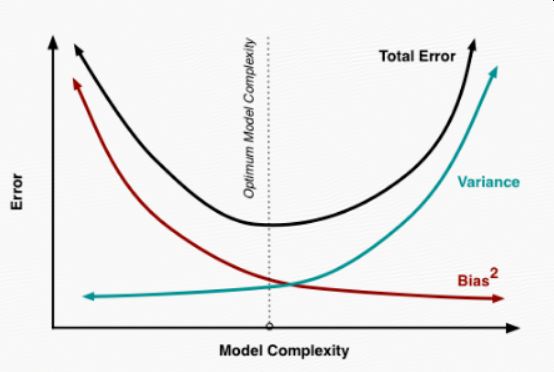
其實就機器學習算法來說,其泛化誤差可以分解為兩部分,偏差(bias)和方差(variance)。這個可由下圖的式子導出(這里用到了概率論公式D(X)=E(X^2)-[E(X)]^2)。偏差指的是算法的期望預測與真實預測之間的偏差程度,反應了模型本身的擬合能力;方差度量了同等大小的訓練集的變動導致學習性能的變化,刻畫了數據擾動所導致的影響。這個有點兒繞,不過你一定知道過擬合。
如下圖所示,當模型越復雜時,擬合的程度就越高,模型的訓練偏差就越小。但此時如果換一組數據可能模型的變化就會很大,即模型的方差很大。所以模型過于復雜的時候會導致過擬合。
以上就是GBDT和XGBoost的區別是什么,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





