溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
開源消息中間件Kafka在華泰證券的探索與實踐是怎樣的,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
Kafka 作為開源消息中間件的重要分支,在券商領域會有怎樣的應用場景?下面從華泰證券的應用現狀出發,介紹了 Kafka 在華泰證券的大規模實踐經驗。
1. 引言
Apache Kafka 發源于 LinkedIn,于 2011 年成為 Apache 的孵化項目,隨后于 2012 年成為 Apache 的頂級項目之一。按照官方定義,Kafka 是一個分布式流平臺,具備流數據的發布及訂閱(與消息隊列或企業級消息系統類似)能力、容錯方式的流數據存儲能力以及流數據的實時處理能力。
Kafka 的優勢在于:
1.可靠性:具有分區機制、副本機制和容錯機制的分布式消息系統。
2.可擴展性:消息系統支持集群規模的熱擴展。
3.高性能:在數據發布和訂閱過程中都能保證數據的高吞吐量。即便在 TB 級數據存儲的情況下,仍然能保證穩定的性能。
目前,Kafka 在互聯網、金融、傳統行業等各種類型公司內部廣泛使用,已成為全球范圍內實時數據傳輸和處理領域的事實標準。
2. 基本原理及概念
一個典型的 Kafka 集群中包含:(1)若干 Producer,用于生產數據;(2)若干 Broker,構成集群吞吐數據;(3)若干 Consumer 消費數據;(4)一個 Zookeeper 集群,進行全局控制和管理。
Kafka 的拓撲結構如下圖所示:
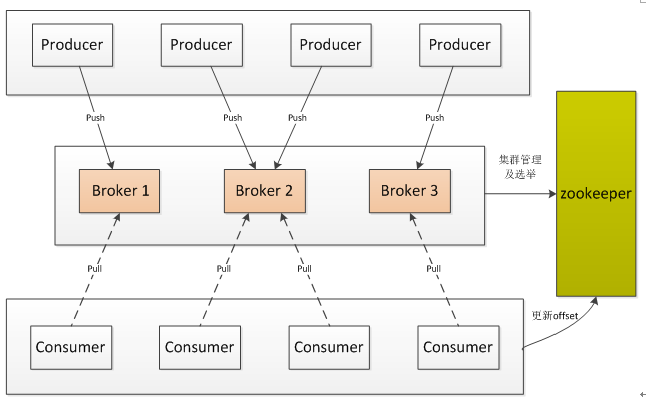
圖1 kafka 架構圖
Kafka 通過 Zookeeper 管理集群配置、選舉 leader,以及在 Consumer Group 發生變化時進行再平衡(rebalance)。Producer 使用 push 模式將消息發布到 broker,Consumer 使用 pull 模式從 broker 訂閱并消費消息并更新消費的偏移量值(offset)。
基本概念:
? Broker(代理):Kafka 集群的服務器節點稱為 broker。
? Topic(主題):在 Kafka 中,使用一個類別屬性來劃分數據的所屬類,劃分數據的這個類稱為 topic。一個主題可以有零個、一個或多個消費者去訂閱寫到這個主題里面的數據。
? Partition(分區):主題中的數據分割為一個或多個 partition,分區是一個有序、不變序列的記錄集合,通過不斷追加形成結構化的日志。
? Producer(生產者):數據的發布者,該角色將消息發布到 Kafka 的 topic 中。生產者負責選擇哪個記錄分配到指定主題的哪個分區中。
? Consumer(消費者):從 broker 中讀取數據,消費者可以消費多個 topic 中的數據。
? Consumer Group(消費者組):每個 consumer 都屬于一個特定的 group 組,一個 group 組可以包含多個 consumer,但一個組中只會有一個 consumer 消費數據。
主題和分區:
Topic 的本質就是一個目錄,由一些 Partition Logs(分區日志)組成,其組織結構如下圖所示。每個 Partition 中的消息都是有序的,生產的消息被不斷追加到 Partition log 上,其中的每一個消息都被賦予了一個唯一的 offset 值。
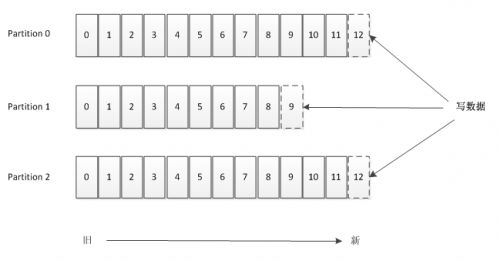
圖 2 Kafka分區數據存儲示意圖
對于傳統的 message queue 而言,一般會刪除已經被消費的消息,Kafka 集群會保存所有的消息,不管消息有沒有被消費。Kafka 提供兩種策略刪除舊數據:(1)基于時間;(2)基于 Partition 文件大小。只有過期的數據才會被自動清除以釋放磁盤空間。
Kafka 需要維持的元數據只有“已消費消息在 Partition 中的 offset 值”,Consumer 每消費一個消息,offset 就會加 1。其實消息的狀態完全是由 Consumer 控制的,Consumer 可以跟蹤和重設這個 offset 值,這樣 Consumer 就可以讀取任意位置的消息。
數據備份機制:
Kafka 允許用戶為每個 topic 設置副本數量,副本數量決定了有幾個 broker 來存放寫入的數據。如果你的副本數量設置為 3,那么一份數據就會被存放在 3 臺不同的機器上,那么就允許有 2 個機器失敗。一般推薦副本數量至少為 2,這樣就可以保證增減、重啟機器時不會影響到數據消費。如果對數據持久化有更高的要求,可以把副本數量設置為 3 或者更多。
核心api:
Producer API:允許應用去推送一個流記錄到一個或多個 kafka 主題上。
Consumer API:允許應用去訂閱一個或多個主題,并處理流數據。ConsumerAPI包含 high levelAPI和 Sample api 兩套。使用 high levelAPI時,同一 Topic 的一條消息只能被同一個 Consumer Group 內的一個 Consumer 消費,但多個 Consumer Group 可同時消費這一消息。與之相對的 Sampleapi 是一個底層的 API,完全無狀態的,每次請求都需要指定 offset 值。
Streams API:允許應用作為一個流處理器,消費來自一個或多個主題的輸入流,或生產一個輸出流到一個或多個輸出主題,并可以有效地將輸入流轉換為輸出流。
其它 Kafka 的特性將在下面華泰證券的使用示例中進一步介紹。
3. Kafka在華泰證券背景介紹及建設現狀
長期以來,華泰證券的系統建設依賴于服務廠商,廠商之間技術方案的差異性造成了系統之間的異構化,各種類型的系統架構長期存在,在消息中間件領域尤是如此。如短信平臺使用 IBMMQ,CRM 系統使用 ESB 架構,自營業務使用 Oracletuxedo 架構,柜臺系統使用恒生 MessageCenter 架構等。隨著華泰證券自主研發的大規模投入,迫切需要改變這種煙囪式的系統建設方式,以統一化的服務化平臺架構來建設系統。
2015 年,我們通過對 Kafka、ActiveMQ 及 RabbitMQ 等開源消息中間件進行全面的測試對比,最終從性能及高可用方面考慮,選擇 Kafka 作為了公司級消息中間件,經過兩年多的探索和實踐,Kafka 平臺已承接大量重要生產業務系統,支撐了全公司業務的高速發展,積累了大量的生產實踐經驗。
經過將近三年的建設發展,目前在華泰證券內部已分別建設 0.9.0 和 0.10.1 版本的 Kafka 集群,總體集群數量 20 余臺。
目前華泰內部 kafka 已為行情計算、交易回報、量化分析等核心系統提供穩定服務,同時涵蓋了日志、數據分析等諸多運維領域的應用,日均消息吞吐量達 2.3TB,峰值流量超 4.8Gb/s,TOPIC 數量 190 余個,服務 30 個以上應用系統。
4. 實踐經驗
(1)高可用雙活架構
如圖 3 所示,Kafka 高可用特性依賴于 zookeeper 來實現,由于 zookeeper 的 paxos 算法特性,故 zookeeper 采用同城三中心部署方式,保證 zookeeper 本身高可用,通常其中兩個數據中心部署偶數臺機器,另一數據中心部署單臺機器。
Kafkabroker 跨數據中心兩節點部署,所有 topic 的 partition 保證在兩中心都有副本。如果單數據中心出現問題,另一個中心能自動進行接管,業務系統可以無感知切換。
由于Kafka的高帶寬需求,主機采用萬兆網卡,并且在網卡做 bond0 以保證網卡高可用,跨數據中心之間的網絡通信采用獨立的萬兆波分通道。
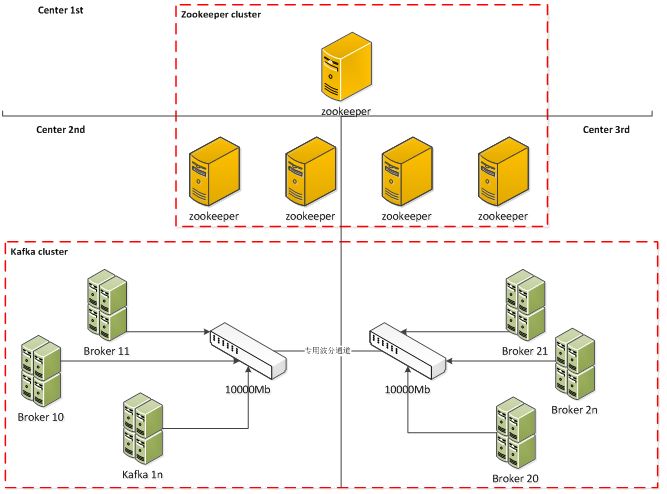
圖 3 KAFKA 平臺部署架構圖
(2)參數調優
? 首先我們在 JVM 層面做了很多嘗試。對 Kafka 服務啟動參數進行調優,使用 G1 回收器。kafka 內存配置一般選擇 64G,其中 16G 給 Kafka 應用本身,剩余內存全部用于操作系統本身的 page cache.
? 此外為了保證核心系統的達到最佳的讀寫效果,我們采用 SSD 硬盤,并做了 raid5 冗余,來保證硬盤的高效 IO 讀寫能力。
? 其次我們通過調整 broker 的 num.io.threads,num.network.threads, num.replica.fetchers 等參數來保證集群之間快速復制和吞吐。
(3)數據一致性保證
Kafka 有自己一套獨特的消息傳輸保障機制(at least once)。當 producer 向 broker 發送消息時,由于副本機制(replication)的存在,一旦這條消息被 broker 確認,它將不會丟失。但如果 producer 發送數據給 broker 后,遇到網絡問題而造成通信中斷,那 producer 就無法判斷該條消息是否已經被確認。這時 producer 可以重試,確保消息已經被 broker 確認,為了保證消息的可靠性,我們要求業務做到:
? 保證發送端成功
當 producer 向 leader 發送數據時,可以通過 request.required.acks 參數來設置數據可靠性的級別:
1(默認) | leader 已成功收到的數據并得到確認后發送下一條 message。如果 leader 宕機,則會丟失數據。 |
0 | 送端無需等待來自 broker 的確認而繼續發送下一批消息。這種情況下數據傳輸效率最高,但是數據可靠性確是最低的。 |
-1(ALL) | 發送端需要等待 ISR 列表中所有列表都確認接收數據后才算一次發送完成,可靠性最高。 |
? 保證消費者消費成功(at least once)
我們要求消費者關閉自動提交(enable.auto.commit:false),同時當消費者每次 poll 處理完業務邏輯后必須完成手動同步提交(commitSync),如果消費者在消費過程中發生 crash,下次啟動時依然會從之前的位置開始消費,從而保證每次提交的內容都能被消費。
? 消息去重
考慮到 producer,broker,consumer 之間都有可能造成消息重復,所以我們要求接收端需要支持消息去重的功能,最好借助業務消息本身的冪等性來做。其中有些大數據組件,如 hbase,elasticsearch 天然就支持冪等操作。
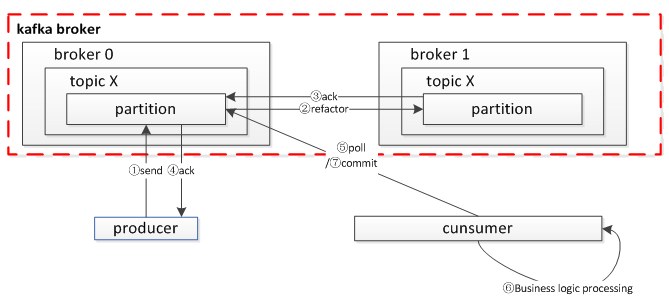
圖 4Kafka 消息可靠性機制
場景事例:行情數據 hbase 存儲
在華泰內部使用 kafka 來緩存一段時間的行情數據,并做相應處理為了保證 kafka 中數據的完整性,發送端API參數配置:
props.put(“acks”, “all”); |
為了防止某條發送影響后續的消息發送,采用帶異步回調的模式發送
 在接收端,啟動專門的消費者拉取 kafka 數據存入 hbase。hbase 的 rowkey 的設計主要包括 SecurityId(股票id)和 timestamp(行情數據時間)。消費線程從 kafka 拉取數據后反序列化,然后批量插入 hbase,只有插入成功后才往 kafka 中持久化 offset。這樣的好處是,如果在中間任意一個階段發生報錯,程序恢復后都會從上一次持久化 offset 的位置開始消費數據,而不會造成數據丟失。如果中途有重復消費的數據,則插入 hbase 的 rowkey 是相同的,數據只會覆蓋不會重復,最終達到數據一致。
在接收端,啟動專門的消費者拉取 kafka 數據存入 hbase。hbase 的 rowkey 的設計主要包括 SecurityId(股票id)和 timestamp(行情數據時間)。消費線程從 kafka 拉取數據后反序列化,然后批量插入 hbase,只有插入成功后才往 kafka 中持久化 offset。這樣的好處是,如果在中間任意一個階段發生報錯,程序恢復后都會從上一次持久化 offset 的位置開始消費數據,而不會造成數據丟失。如果中途有重復消費的數據,則插入 hbase 的 rowkey 是相同的,數據只會覆蓋不會重復,最終達到數據一致。
所以,從根本上說,kafka 上的數據傳輸也是數據最終一致性的典型場景。
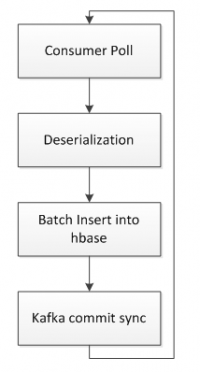
圖 5hbase 持久化邏輯
(4)ACL安全
目前華泰內部通過配置 allow.everyone.if.no.acl.found 參數(:true)讓 Kafka 集群同時具備ACL和非ACL的能力,避免資源的浪費。我們選用 SASL 作為 Kafka 鑒權方式,因為 SASL 雖然簡單,但已滿足需求,而 Kerberos 使用過重,過度復雜組件會給 Kafka 帶來更多不確定的因素,如示例所示,根據部門劃分來分配用戶。
示例:
KafkaServer {
org.apache.kafka.common.security.plain.PlainLoginModule required
ser_dep1=“ password 1”
user_dep2=“ password 2”
user_dep3=“ password 3”;
};
服務啟動后,通過 Kafka 的 command line 接口,配置基于用戶、ip、topic、groupid 等的 acl 權限來保證各業務之間的隔離。
5.未來規劃
隨著業務的不斷發展,Kafka 在華泰證券內部已成為核心組件。未來重點進行 PaaS 平臺建設,建立分級保障和ACL權限管控,對重點業務進行獨立管理。
目前 Kafka 的 topic 一般只有 2 個副本,在某些特殊場景下存在數據丟失的風險,未來我們會通過升級擴容,基于業務的重要程度提升副本數,強化集群的高可用性。
后續我們還會深入研究 Kafka1.0,與 KafkaStreaming、KQL、Storm、Spark、Flink 等流式計算引擎相結合,依托 Kafka 打造公司級流式計算平臺。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





