溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“HashMap和Hashtable的區別是什么”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“HashMap和Hashtable的區別是什么”這篇文章吧。
1.兩者最主要的區別在于Hashtable是線程安全,而HashMap則非線程安全
Hashtable的實現方法里面都添加了synchronized關鍵字來確保線程同步,因此相對而言HashMap性能會高一些,我們平時使用時若無特殊需求建議使用HashMap,在多線程環境下若使用HashMap需要使用Collections.synchronizedMap()方法來獲取一個線程安全的集合(Collections.synchronizedMap()實現原理是Collections定義了一個SynchronizedMap的內部類,這個類實現了Map接口,在調用方法時使用synchronized來保證線程同步,當然了實際上操作的還是我們傳入的HashMap實例,簡單的說就是Collections.synchronizedMap()方法幫我們在操作HashMap時自動添加了synchronized來實現線程同步,類似的其它Collections.synchronizedXX方法也是類似原理)
2.HashMap可以使用null作為key,而Hashtable則不允許null作為key
雖說HashMap支持null值作為key,不過建議還是盡量避免這樣使用,因為一旦不小心使用了,若因此引發一些問題,排查起來很是費事
HashMap以null作為key時,總是存儲在table數組的第一個節點上
3.HashMap是對Map接口的實現,HashTable實現了Map接口和Dictionary抽象類
4.HashMap的初始容量為16,Hashtable初始容量為11,兩者的填充因子默認都是0.75
HashMap擴容時是當前容量翻倍即:capacity*2,Hashtable擴容時是容量翻倍+1即:capacity*2+1
5.兩者計算hash的方法不同
Hashtable計算hash是直接使用key的hashcode對table數組的長度直接進行取模
int hash = key.hashCode();int index = (hash & 0x7FFFFFFF) % tab.length;
HashMap計算hash對key的hashcode進行了二次hash,以獲得更好的散列值,然后對table數組長度取摸

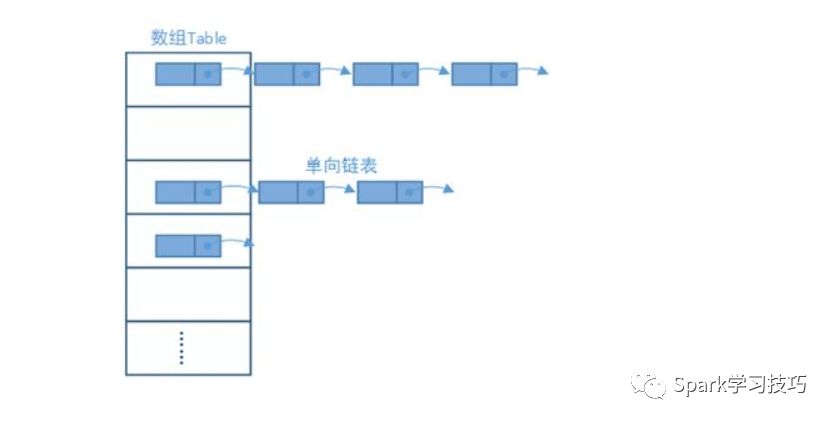
6.HashMap和Hashtable的底層實現都是數組+鏈表結構實現
除開HashMap和Hashtable外,還有一個hash集合HashSet,有所區別的是HashSet不是key value結構,僅僅是存儲不重復的元素,相當于簡化版的HashMap,只是包含HashMap中的key而已
通過查看源碼也證實了這一點,HashSet內部就是使用HashMap實現,只不過HashSet里面的Ha11shMap所有的value都是同一個Object而已,因此HashSet也是非線程安全的,至于HashSet和Hashtable的區別,HashSet就是個簡化的HashMap的,所以你懂的
下面是HashSet幾個主要方法的實現

HashMap和Hashtable的底層實現都是數組+鏈表結構實現的,這點上完全一致
添加、刪除、獲取元素時都是先計算hash,根據hash和table.length計算index也就是table數組的下標,然后進行相應操作,下面以HashMap為例說明下它的簡單實現

HashMap的創建
HashMap默認初始化時會創建一個默認容量為16的Entry數組,默認加載因子為0.75,同時設置臨界值為16*0.75

put方法
HashMap會對null值key進行特殊處理,總是放到table[0]位置
put過程是先計算hash然后通過hash與table.length取摸計算index值,然后將key放到table[index]位置,當table[index]已存在其它元素時,會在table[index]位置形成一個鏈表,將新添加的元素放在table[index],原來的元素通過Entry的next進行鏈接,這樣以鏈表形式解決hash沖突問題,當元素數量達到臨界值(capactiy*factor)時,則進行擴容,是table數組長度變為table.length*2

get方法
同樣當key為null時會進行特殊處理,在table[0]的鏈表上查找key為null的元素
get的過程是先計算hash然后通過hash與table.length取摸計算index值,然后遍歷table[index]上的鏈表,直到找到key,然后返回

remove方法
remove方法和put get類似,計算hash,計算index,然后遍歷查找,將找到的元素從table[index]鏈表移除

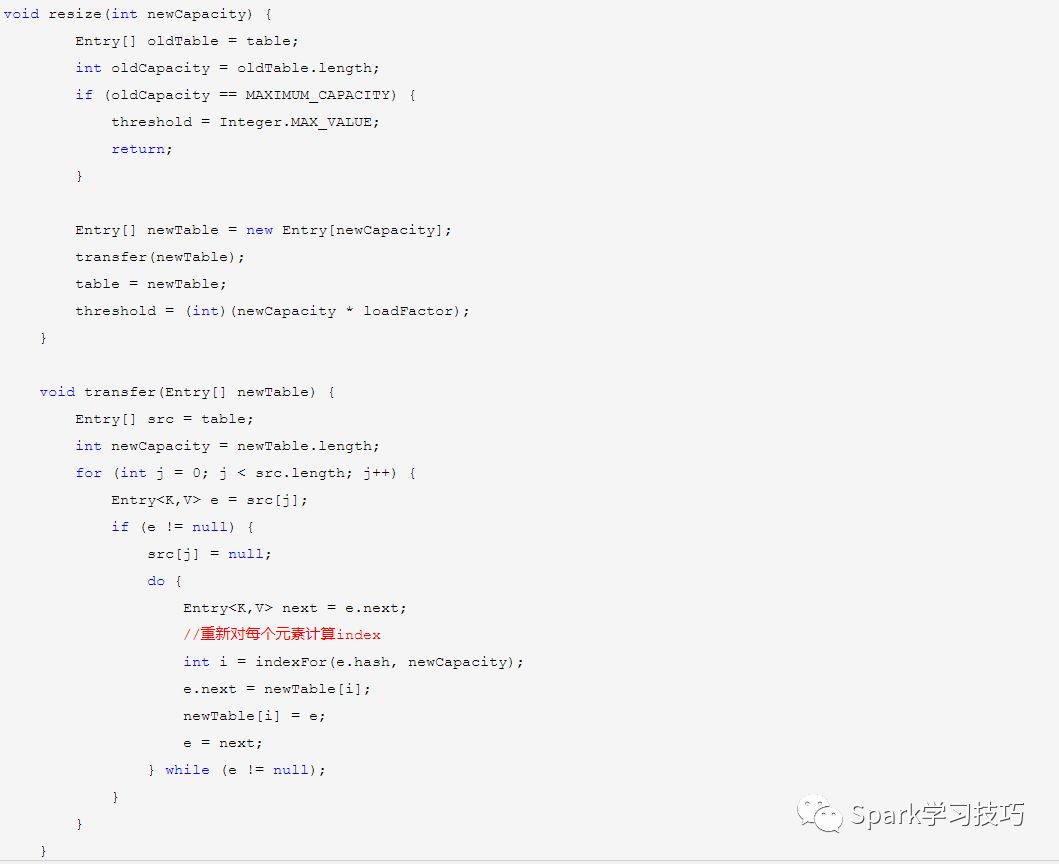
resize方法
resize方法在hashmap中并沒有公開,這個方法實現了非常重要的hashmap擴容,具體過程為:先創建一個容量為table.length*2的新table,修改臨界值,然后把table里面元素計算hash值并使用hash與table.length*2重新計算index放入到新的table里面
這里需要注意下是用每個元素的hash全部重新計算index,而不是簡單的把原table對應index位置元素簡單的移動到新table對應位置
clear()方法
clear方法非常簡單,就是遍歷table然后把每個位置置為null,同時修改元素個數為0
需要注意的是clear方法只會清楚里面的元素,并不會重置capactiy
containsKey和containsValue
containsKey方法是先計算hash然后使用hash和table.length取摸得到index值,遍歷table[index]元素查找是否包含key相同的值
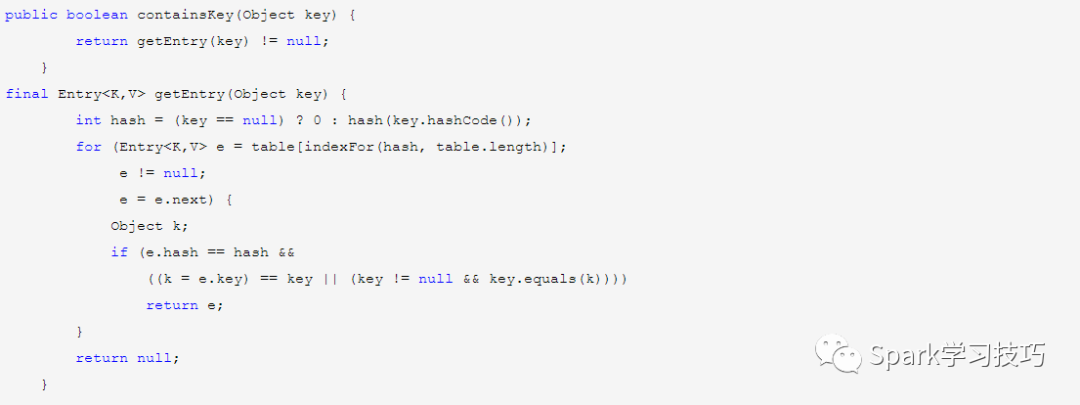
containsValue方法就比較粗暴了,就是直接遍歷所有元素直到找到value,由此可見HashMap的containsValue方法本質上和普通數組和list的contains方法沒什么區別,你別指望它會像containsKey那么高效

hash和indexFor
indexFor中的h & (length-1)就相當于h%length,用于計算index也就是在table數組中的下標
hash方法是對hashcode進行二次散列,以獲得更好的散列值
為了更好理解這里我們可以把這兩個方法簡化為 int index= key.hashCode()/table.length,以put中的方法為例可以這樣替換


以上是“HashMap和Hashtable的區別是什么”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





