溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關基于Spark Mllib文本分類的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
基于Spark Mllib的文本分類
文本分類是一個典型的機器學習問題,其主要目標是通過對已有語料庫文本數據訓練得到分類模型,進而對新文本進行類別標簽的預測。這在很多領域都有現實的應用場景,如新聞網站的新聞自動分類,垃圾郵件檢測,非法信息過濾等。本文將通過訓練一個手機短信樣本數據集來實現新數據樣本的分類,進而檢測其是否為垃圾消息,基本步驟是:首先將文本句子轉化成單詞數組,進而使用 Word2Vec 工具將單詞數組轉化成一個 K 維向量,最后通過訓練 K 維向量樣本數據得到一個前饋神經網絡模型,以此來實現文本的類別標簽預測。本文案例實現上采用 Spark ML 中的詞向量化工具 Word2Vec 和多層感知器分類器 (Multiple Layer Perceptron Classifier)
Word2Vec簡介
Word2Vec 是一個用來將詞表示為數值型向量的工具,其基本思想是將文本中的詞映射成一個 K 維數值向量 (K 通常作為算法的超參數),這樣文本中的所有詞就組成一個 K 維向量空間,這樣我們可以通過計算向量間的歐氏距離或者余弦相似度得到文本語義的相似度。Word2Vec 采用的是 Distributed representation 的詞向量表示方式,這種表達方式不僅可以有效控制詞向量的維度,避免維數災難 (相對于 one-hot representation),而且可以保證意思相近的詞在向量空間中的距離較近。
Word2Vec 實現上有兩種模型 CBOW (Continuous Bag of Words, 連續詞袋模型) 和 Skip-Gram,簡單概括一下區別就是:CBOW 是根據語境預測目標單詞,Skip-Gram 根據當前單詞預測語境。Spark 的實現采用的是 Skip-Gram 模型 。假設我們有 N 個待訓練的單詞序列樣本,記作 w1,w2...wn, Skip-Gram 模型的訓練目標是最大化平均對數似然,即
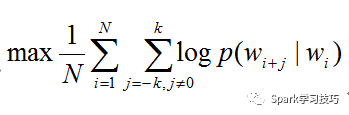
其中 N 是詞個數,K 是詞上下文的窗口大小。Skip-Gram 模型中一定上下文窗口內的詞兩兩之間都會計算概率,并且通常情況下,上下文窗口越大所能涵蓋的詞組合情況就越全面,這樣可以帶來更加精確的結果,但是缺點是也會增加訓練時間。
在 Skip-Gram 模型里,每個單詞都關聯兩個向量,分別表示詞向量和上下文向量。也正是因為如此,Word2Vec 較之傳統的 LDA(Latent Dirichlet Allocation) 過程,可以表達更加豐富和準確的語義信息。
Spark 的 Word2Vec 實現提供以下主要可調參數:
inputCol , 源數據 DataFrame 中存儲文本詞數組列的名稱。
outputCol, 經過處理的數值型特征向量存儲列名稱。
vectorSize, 目標數值向量的維度大小,默認是 100。
windowSize, 上下文窗口大小,默認是 5。
numPartitions, 訓練數據的分區數,默認是 1。
maxIter,算法求最大迭代次數,小于或等于分區數。默認是 1.
minCount, 只有當某個詞出現的次數大于或者等于 minCount 時,才會被包含到詞匯表里,否則會被忽略掉。
stepSize,優化算法的每一次迭代的學習速率。默認值是 0.025.
這些參數都可以在構造 Word2Vec 實例的時候通過 setXXX 方法設置。
多層感知器
多層感知器 (MLP, Multilayer Perceptron) 是一種多層的前饋神經網絡模型,所謂前饋型神經網絡,指其從輸入層開始只接收前一層的輸入,并把計算結果輸出到后一層,并不會給前一層有所反饋,整個過程可以使用有向無環圖來表示。該類型的神經網絡由三層組成,分別是輸入層 (Input Layer),一個或多個隱層 (Hidden Layer),輸出層 (Output Layer),如圖所示:

Spark ML 在 1.5 版本后提供一個使用 BP(反向傳播,Back Propagation) 算法訓練的多層感知器實現,BP 算法的學習目的是對網絡的連接權值進行調整,使得調整后的網絡對任一輸入都能得到所期望的輸出。BP 算法名稱里的反向傳播指的是該算法在訓練網絡的過程中逐層反向傳遞誤差,逐一修改神經元間的連接權值,以使網絡對輸入信息經過計算后所得到的輸出能達到期望的誤差。Spark 的多層感知器隱層神經元使用 sigmoid 函數作為激活函數,輸出層使用的是 softmax 函數。
Spark 的多層感知器分類器 (MultilayerPerceptronClassifer) 支持以下可調參數:
featuresCol:輸入數據 DataFrame 中指標特征列的名稱。
labelCol:輸入數據 DataFrame 中標簽列的名稱。
layers:這個參數是一個整型數組類型,第一個元素需要和特征向量的維度相等,最后一個元素需要訓練數據的標簽取值個數相等,如 2 分類問題就寫 2。中間的元素有多少個就代表神經網絡有多少個隱層,元素的取值代表了該層的神經元的個數。例如val layers = Array[Int](100,6,5,2)。
maxIter:優化算法求解的最大迭代次數。默認值是 100。
predictionCol:預測結果的列名稱。
tol:優化算法迭代求解過程的收斂閥值。默認值是 1e-4。不能為負數。
blockSize:該參數被前饋網絡訓練器用來將訓練樣本數據的每個分區都按照 blockSize 大小分成不同組,并且每個組內的每個樣本都會被疊加成一個向量,以便于在各種優化算法間傳遞。該參數的推薦值是 10-1000,默認值是 128。
算法的返回是一個 MultilayerPerceptronClassificationModel 類實例。
目標數據集預覽
在引言部分,筆者已經簡要介紹過了本文的主要任務,即通過訓練一個多層感知器分類模型來預測新的短信是否為垃圾短信。在這里我們使用的目標數據集是來自 UCI 的 SMS Spam Collection 數據集,該數據集結構非常簡單,只有兩列,第一列是短信的標簽 ,第二列是短信內容,兩列之間用制表符 (tab) 分隔。雖然 UCI 的數據集是可以拿來免費使用的,但在這里筆者依然嚴正聲明該數據集的版權屬于 UCI 及其原始貢獻者。

數據集下載鏈接:http://archive.ics.uci.edu/ml/datasets/SMS+Spam+Collection
案例分析與實現
在處理文本短信息分類預測問題的過程中,筆者首先是將原始文本數據按照 8:2 的比例分成訓練和測試數據集。整個過程分為下面幾個步驟
從本地讀取原始數據集,并創建一個 DataFrame。
使用 StringIndexer 將原始的文本標簽 (“Ham”或者“Spam”) 轉化成數值型的表型,以便 Spark ML 處理。
使用 Word2Vec 將短信文本轉化成數值型詞向量。
使用 MultilayerPerceptronClassifier 訓練一個多層感知器模型。
使用 LabelConverter 將預測結果的數值標簽轉化成原始的文本標簽。
最后在測試數據集上測試模型的預測精確度。
算法的具體實現如下:
1, 首先導入包
import org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.MultilayerPerceptronClassifier
import org.apache.spark.ml.evaluation.MulticlassClassificationEvaluator
import org.apache.spark.ml.feature.{IndexToString, StringIndexer, Word2Vec}
2, 創建 集并分詞
val parsedRDD = sc.textFile("file:///opt/datas/SMSSpamCollection").map(_.split(" ")).map(eachRow => {
(eachRow(0),eachRow(1).split(" "))
})
val msgDF = spark.createDataFrame(parsedRDD).toDF("label","message")
3, 將標簽轉化為索引值
val labelIndexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel").fit(msgDF)
4, 創建Word2Vec,分詞向量大小100
final val VECTOR_SIZE = 100
val word2Vec = new Word2Vec().setInputCol("message").setOutputCol("features").setVectorSize(VECTOR_SIZE).setMinCount(1)
5, 創建多層感知器
輸入層VECTOR_SIZE個,中間層兩層分別是6,,5個神經元,輸出層2個
val layers = Array[Int](VECTOR_SIZE,6,5,2)
val mlpc = new MultilayerPerceptronClassifier().setLayers(layers).setBlockSize(512).setSeed(1234L).setMaxIter(128).setFeaturesCol("features").setLabelCol("indexedLabel").setPredictionCol("prediction")
6, 將索引轉換為原有標簽
val labelConverter = new IndexToString().setInputCol("prediction").setOutputCol("predictedLabel").setLabels(labelIndexer.labels)
7, 數據集分割
val Array(trainingData, testData) = msgDF.randomSplit(Array(0.8, 0.2))
8, 創建pipeline并訓練數據
val pipeline = new Pipeline().setStages(Array(labelIndexer,word2Vec,mlpc,labelConverter))
val model = pipeline.fit(trainingData)
val predictionResultDF = model.transform(testData)
//below 2 lines are for debug use
predictionResultDF.printSchema
predictionResultDF.select("message","label","predictedLabel").show(30)
9, 評估訓練結果
val evaluator = new MulticlassClassificationEvaluator().setLabelCol("indexedLabel").setPredictionCol("prediction").setMetricName("precision")
val predictionAccuracy = evaluator.evaluate(predictionResultDF)
println("Testing Accuracy is %2.4f".format(predictionAccuracy * 100) + "%")

關于“基于Spark Mllib文本分類的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





