溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Spyfari怎么用的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
Spyfari
用javascrip編寫爬蟲規則,
可視化的爬蟲軟件。
我拿它,對著名的p站爬取了一些數據,
在這里我們先回顧下爬蟲爬取數據的步驟:
1、通過瀏覽器查看網站結構,提取出需要獲取數據所在的標簽,這里跟各種element的節點打交道,需要解釋網頁標簽,用到類選擇、id選擇、父節點、子節點、正則表達式等等。如果是用python有相應的庫,比如BeautifulSoup;
2、處理自動登錄,驗證碼等。
3、獲取到數據,或者url,數據存入本地或者數據庫
4、根據url再次爬取其他數據,或者根據url下載文件(包括圖片、視頻、文本、網頁等等)。
大致是這么個過程。
有2個事情比較頭疼:
1、注冊登錄賬號才能訪問
2、各種驗證碼
登錄的話獲取登錄后的cookie,以后每次爬取的時候,模擬即可。
但是驗證碼的話,如果碰到變態的驗證碼,就哭吧。。。
像下面這種:

反正我是沒辦法攻破。。
不過用上Spyfari,人工點擊下,這是很容易的事。
下次再登錄,登錄狀態已經保存了,哈。
除非每一步都要驗證碼,這種情況不太可能發生吧,畢竟犧牲了用戶體驗哈。
這就是可視化的優點,各種網站都可以爬取。
我今天先把p站的各個排行榜上的信息爬下來了,還下了圖片~
喜歡二次元的朋友應該會喜歡看吧~~



p站的一些排行榜,我都保存為一個個的json文件了,每天都更新排名,看來可以定時去爬取了。
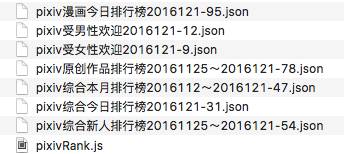
上面那個pixivRank.js是爬取的代碼,我會打包進spyfari里的,作為例子。
初次接觸可以直接在spyfari里打開,運行下,體驗下爬取數據的樂趣。
下面是我爬取的數據存放的格式:
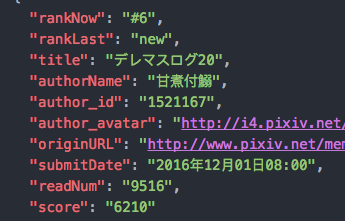
主要爬取了名次、作者、圖片url、還有投稿日期;
這個頁面是異步加載的,需要不斷的滑動到頁面最底端才能獲取得到數據,但是對于spyfari來說,這個還算是很容易的,畢竟是可視化的爬蟲工具,哈,可以做到完全模擬人工操作,過程還是可見的。
其中,投稿日期是異步獲取的,需要模擬鼠標點擊,然后獲取數據。
Spyfari處理異步加載的內容很容易。
這是今天修完Spyfari的一些bug之后,測試代碼下載的圖片。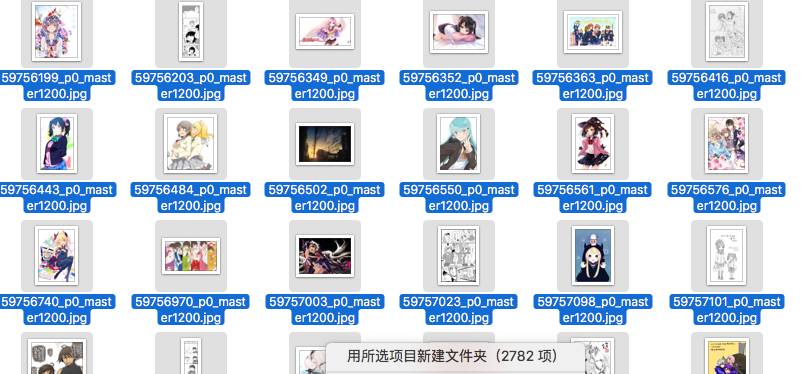
下面看看工作頁面吧~
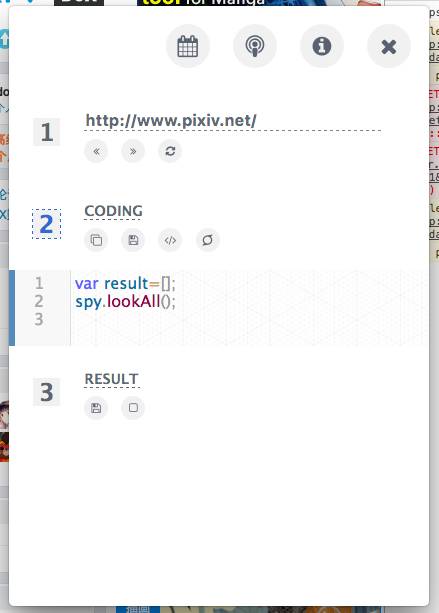
最上面一欄是:
定時任務、云端代碼共享、操作指引、關閉spyfari。
都還沒有進一步開發,待我下禮拜繼續完善。
接下來是:
1、需要爬取數據的網址控制,調用的是我精簡的chrome瀏覽器,畢竟爬取數據第一步是分析網頁結構啊,要方便的調試代碼,還要方便定位標簽。
2、編寫爬取代碼的地方,我集成了一個編輯器。簡單好用,在右側瀏覽器調試好代碼,直接拷過來,保存在本地或者打開本地已有的爬取代碼。
代碼編寫完后,直接點擊運行按鈕。
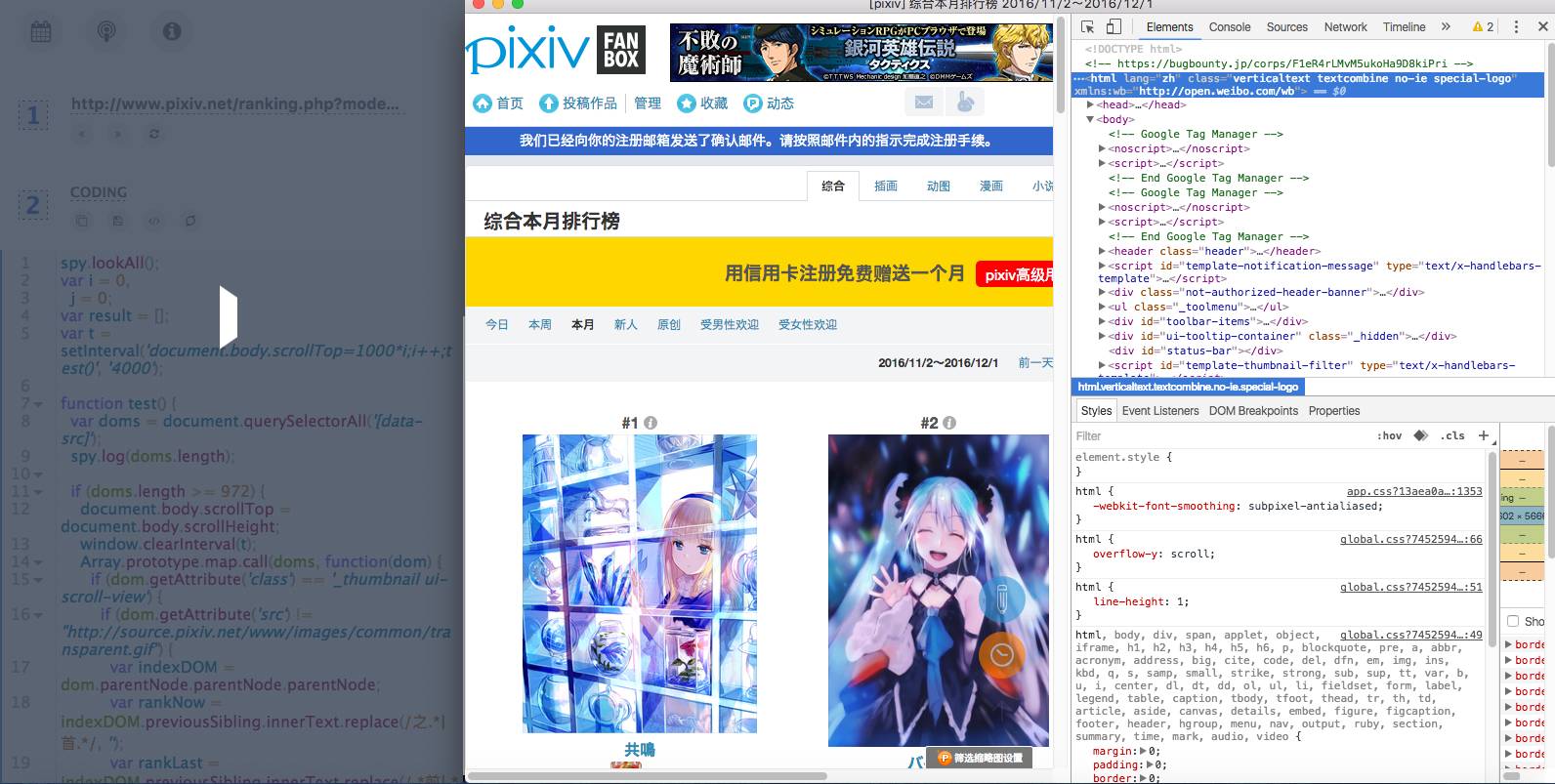
愉快的工作起來了,右邊還可以實時看到運行的情況,包括一些模擬登錄啊,模擬鼠標點擊、滑動動作啊~一目了然。
3、是一些爬取的結果輸出,還有log的輸出,我整合了一些api,方便使用。
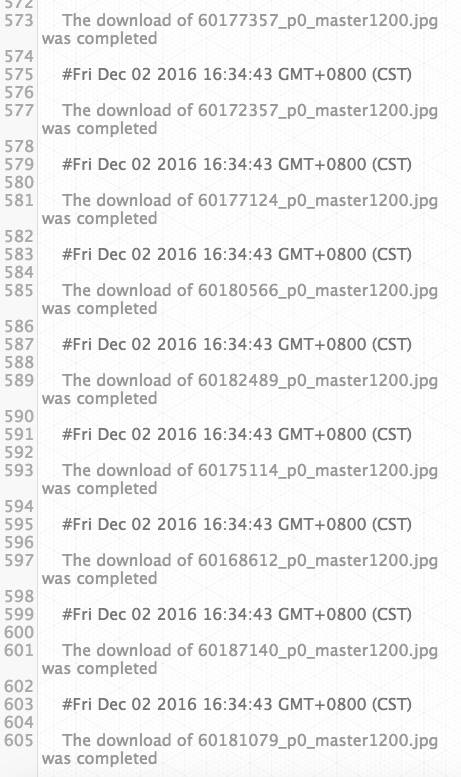
如果有下載動作,比如下載圖片,也會自動得打印出來。后續會再完善進度提示的功能。
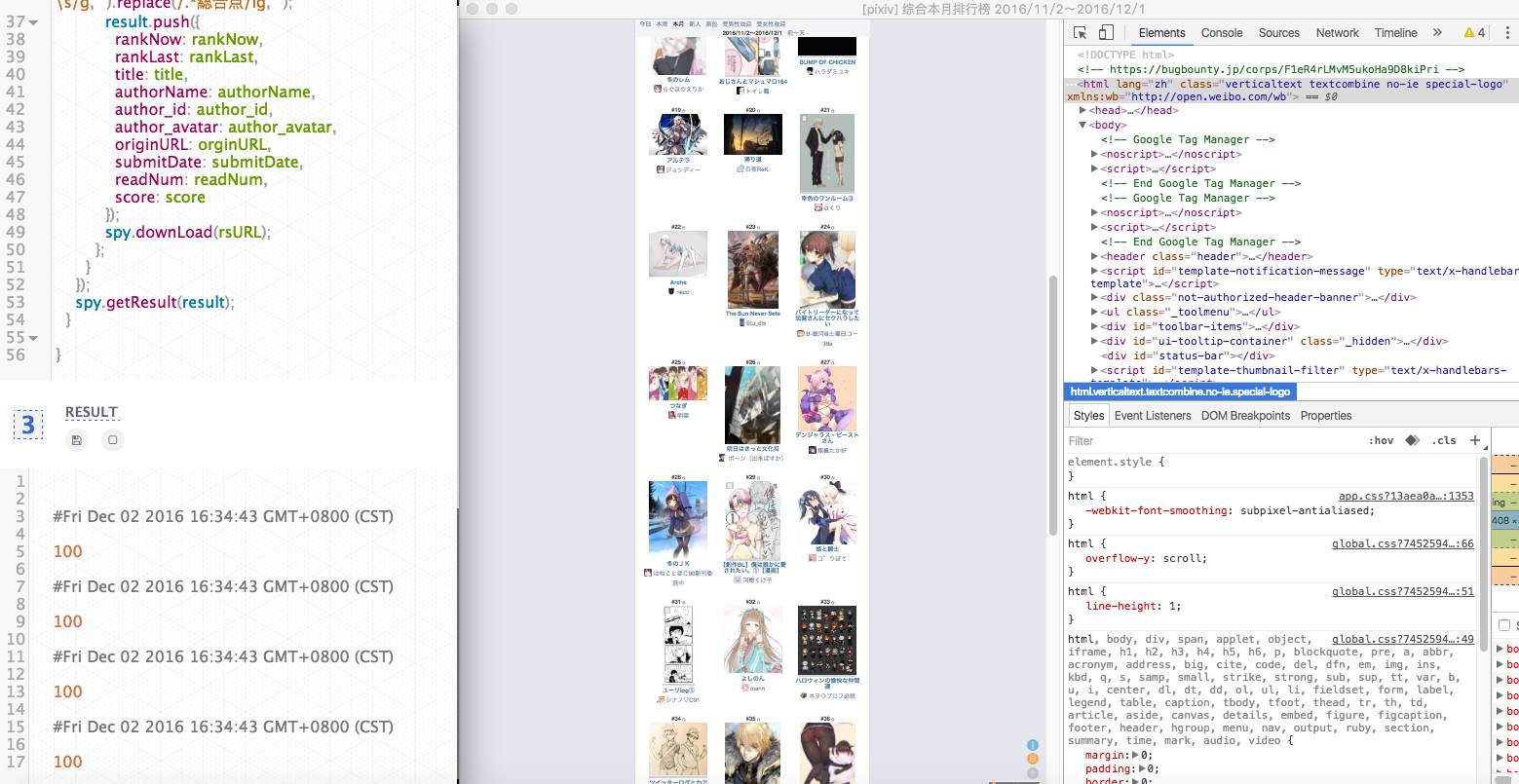
下面這張圖是下載的信息輸出:
感謝各位的閱讀!關于“Spyfari怎么用”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





