溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“flume的使用方法是什么”,在日常操作中,相信很多人在flume的使用方法是什么問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”flume的使用方法是什么”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
  - Chukwa(Apache)
  - Scribe(Facebook)
  - Fluentd:Fluentd 使用 C/Ruby 開發,使用 JSON 文件來統一日 志數據。
  - Logstash(著名的開源數據棧 ELK(ElasticSearch,Logstash,Kibana)中的那個 L)
  - Flume(Apache):開源,高可靠,高擴展,容易管理,支持客戶擴展的數據采集系統。
首先看一下hadoop業務的整體開發流程: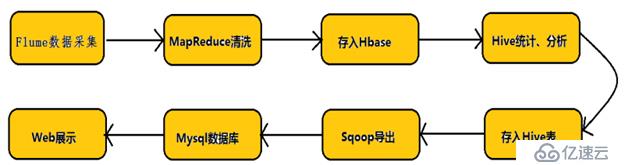
數據采集---數據清洗etl(數據抽取,轉換,裝載)---數據存儲---數據計算分析---數據展現
其中數據采集是所有數據系統必不可少的,沒有數據一切都是空談。
那數據采集系統的特征又是什么呢?
  - 構建應用系統和分析系統的橋梁,并將他們之間進行解耦(web---hadoop) 支持實時的在線分析系統和類似于hadoop之類的離線分析系統
  - 具有高可擴展性,即:當數據增加時,可以通過增加節點進行水平擴展。
  - Apache Flume是一個分布式、可靠、和高可用的海量日志采集、聚合和傳輸的系統。和sqooq同屬于數據采集系統組件,但是sqoop用來采集關系型數據庫數據。而flume用來采集流動性數據。
  - Flume 名字來源于原始的近乎實時的日志數據采集工具,現在被廣泛用于任何流事件數 據的采集,它支持從很多數據源聚合數據到 HDFS。
  - 一般的采集需求,通過對 flume 的簡單配置即可實現。Flume 針對特殊場景也具備良好 的自定義擴展能力,因此,flume 可以適用于大部分的日常數據采集場景
  - Flume 的優勢:可橫向擴展、延展性、可靠性
接下來以一個很簡單的場景為例,將weserver的日志收集到hdfs中。
NG架構: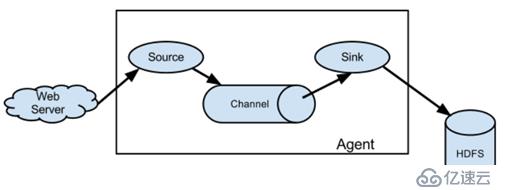
應用系統(web server)---flume的日志收集(source、channel、sink)----hdfs(數據存儲)
其中:
  source:數據源(讀原始日志文件進行讀取)
  channel:數據通道(緩沖,緩解讀寫數據速度不一致問題)
  sink:數據的目的地(收集到的數據寫出到最終的目的地)
OG架構:(0.9以前)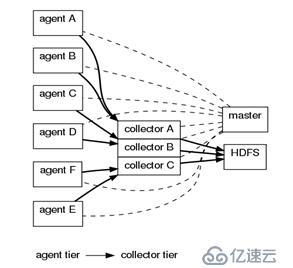
代理節點(agent) ----- 收集節點(collector)-----(master)主節點
 Agent從各個數據源收集日志數據,將收集到的數據集中到collector,然后由收集節點匯總存入hdfs。Master負責管理agent和collector的活動。
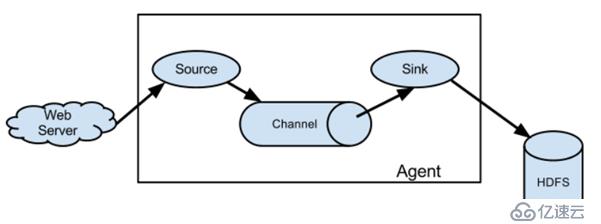
 Flume的數據由事件(event)貫穿始終,事件是flume的基本數據單位,它攜帶日志數據(字節數組形式),并且攜帶有頭信息,這些event由agent外部的source生成,當source捕獲的事件后會進行特定的格式化,然后source會把事件推入(單個或多個)channel中。可以把 Channel 看作是一個緩沖區,它將保存事件直到 Sink 處理完該事件。Sink 負責持久化日志或 者把事件推向另一個 Source。
 Flume以agent為最小的獨立運行單位,一個agent就是一個jvm,單個agent由source、sink和channel三大組件構成。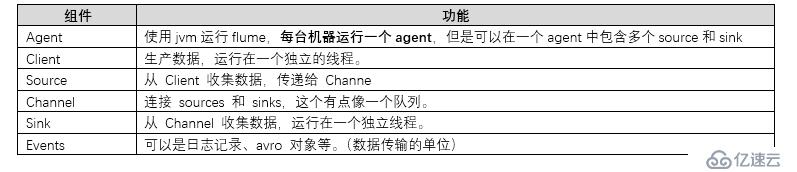
Event
 Event是flume數據傳輸的基本單位。Flume以事件的形式將數據從源頭,傳送到最終的目的地。Event由可選的header和載有數據的一個byte array構成。Header 是容納了 key-value 字符串對的無序集合,key 在集合內是唯一的。
agent
 agent 是 flume 流的基礎部分,一個 Agent 包含 source,channel,sink 和其他組件;利用這些組件將 events 從一個節點傳輸到另一個節點或最終目的地。
Source
 Source負責接收event或者通過特殊機制產生event,并將events批量的放到一個或者多個channel中。
channel
 Channel 位于 Source 和 Sink 之間,用于緩存進來的 event。當sink成功的將event發送到下一個的channel或者最終目的,event從channel刪除。
Sink
 Sink負責將event傳輸到下一個或者最終目的地,成功后將event從channel移除。
 flume的搭建極為簡單,基本上就是解壓即可,但是由于我們經常將flume和大數據平臺聯系,所以需要我們將hadoop和jdk的環境搭建成功。
安裝
 - 上傳安裝包
 - 解壓安裝包
 - 配置環境變量
 - 修改配置文件:
[hadoop @hadoop01 ~]cd /application/flume/conf [hadoop @hadoop01 ~]mv flume-env.sh.template flume-env.sh [hadoop @hadoop01 ~]vim flume-env.sh export JAVA_HOME=/application/jdk1.8 (修改這一個就行)
 -測試是否安裝成功
[hadoop @hadoop01 ~]flume-ng version
看見以上的結果表示安裝成功!!!!
注意:一般的需要在哪臺機器中采集數據,就在哪臺機器中安裝flume
 flume的一切操作都是基于配置文件,所以,必須寫配置文件。(必須是以.conf或者.properties結尾)。
這里我們以一個非常簡單的案例,介紹flume如何使用:
配置文件:
#example.conf #這里的a1指的是agent的名字,可以自定義,但注意:同一個節點下的agent的名字不能相同 #定義的是sources、sinks、channels的別名 a1.sources = r1 a1.sinks = k1 a1.channels = c1 #指定source的類型和相關的參數 a1.sources.r1.type = spooldir a1.sources.r1.spoolDir = /home/hadoop/flumedata #監聽一個文件夾 #設定channel a1.channels.c1.type = memory #設定sink a1.sinks.k1.type = logger #Bind the source and sink to the channel #設置sources的通道 a1.sources.r1.channels = c1 #設置sink的通道 a1.sinks.k1.channel = c1
準備測試環境:
創建一個目錄:a1.sources.r1.spoolDir = /home/hadoop/flumedata
啟動命令:
flume-ng agent --conf conf --conf-file /home/hadoop/example.conf --name a1 -Dflume.root.logger=INFO,console
然后移動一個有內容的文件到flume監聽的文件夾下(/home/hadoop/flumedata):
查看 此時窗口的狀態:
內容成功收集!!
到此,關于“flume的使用方法是什么”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





