溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了如何理解k8s調度器的調度流程和算法,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
Kubernetes 作為當下最主流的容器自動化運維平臺,作為 K8s 的容器編排的核心組件 kube-scheduler 將是我今天介紹的主角,如下介紹的版本都是以 **release-1.16 **為基礎,下圖是 kube-scheduler 的主要幾大組件: 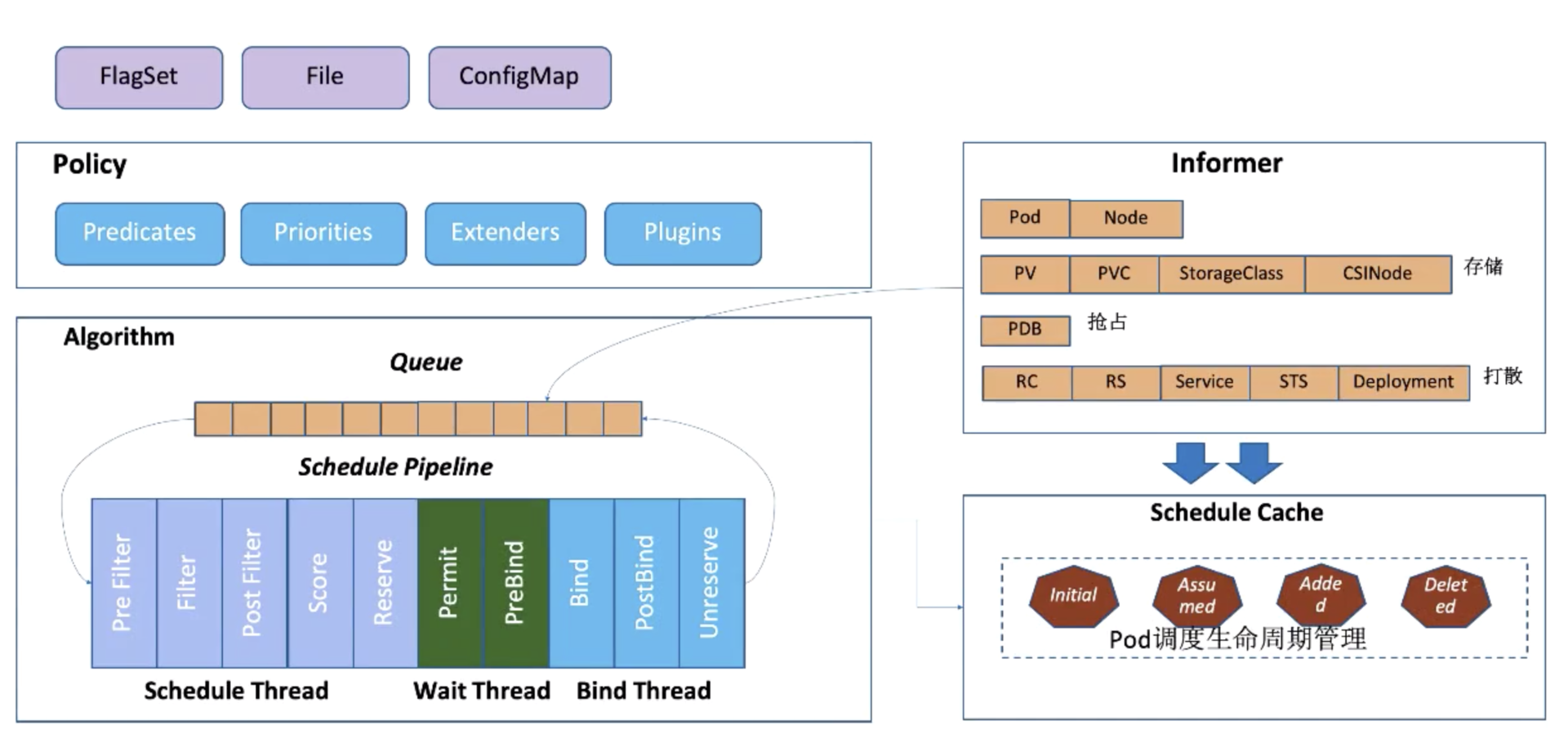
Scheduler 的調度策略啟動配置目前支持三種方式,配置文件 / 命令行參數 / ConfigMap。調度策略可以配置指定調度主流程中要用哪些過濾器 (Predicates)、打分器 (Priorities) 、外部擴展的調度器 (Extenders),以及最新支持的 SchedulerFramwork 的自定義擴展點 (Plugins)。
Scheduler 在啟動的時候通過 K8s 的 informer 機制以 List+Watch 從 kube-apiserver 獲取調度需要的數據例如:Pods、Nodes、Persistant Volume(PV), Persistant Volume Claim(PVC) 等等,并將這些數據做一定的預處理作為調度器的的 Cache。
通過 Informer 將需要調度的 Pod 插入 Queue 中,Pipeline 會循環從 Queue Pop 等待調度的 Pod 放入 Pipeline 執行。
調度流水線 (Schedule Pipeline) 主要有三個階段:Scheduler Thread,Wait Thread,Bind Thread。
Scheduler Thread 階段: 從如上的架構圖可以看到 Schduler Thread 會經歷 Pre Filter -> Filter -> Post Filter-> Score -> Reserve,可以簡單理解為 Filter -> Score -> Reserve。
Filter 階段用于選擇符合 Pod Spec 描述的 Nodes;Score 階段用于從 Filter 過后的 Nodes 進行打分和排序;Reserve 階段將 Pod 跟排序后的最優 Node 的 NodeCache 中,表示這個 Pod 已經分配到這個 Node 上, 讓下一個等待調度的 Pod 對這個 Node 進行 Filter 和 Score 的時候能看到剛才分配的 Pod。
**Wait Thread 階段: **這個階段可以用來等待 Pod 關聯的資源的 Ready 等待,例如等待 PVC 的 PV 創建成功,或者 Gang 調度中等待關聯的 Pod 調度成功等等;
**Bind Thread 階段: **用于將 Pod 和 Node 的關聯持久化 Kube APIServer。
整個調度流水線只有在 Scheduler Thread 階段是串行的一個 Pod 一個 Pod 的進行調度,在 Wait 和 Bind 階段 Pod 都是異步并行執行。
解說完 kube-scheduler 的幾大部件的作用和關聯關系之后,接下來深入理解下 Scheduler Pipeline 的具體工作原理,如下是 kube-scheduler 的詳細流程圖,先解說調度隊列: 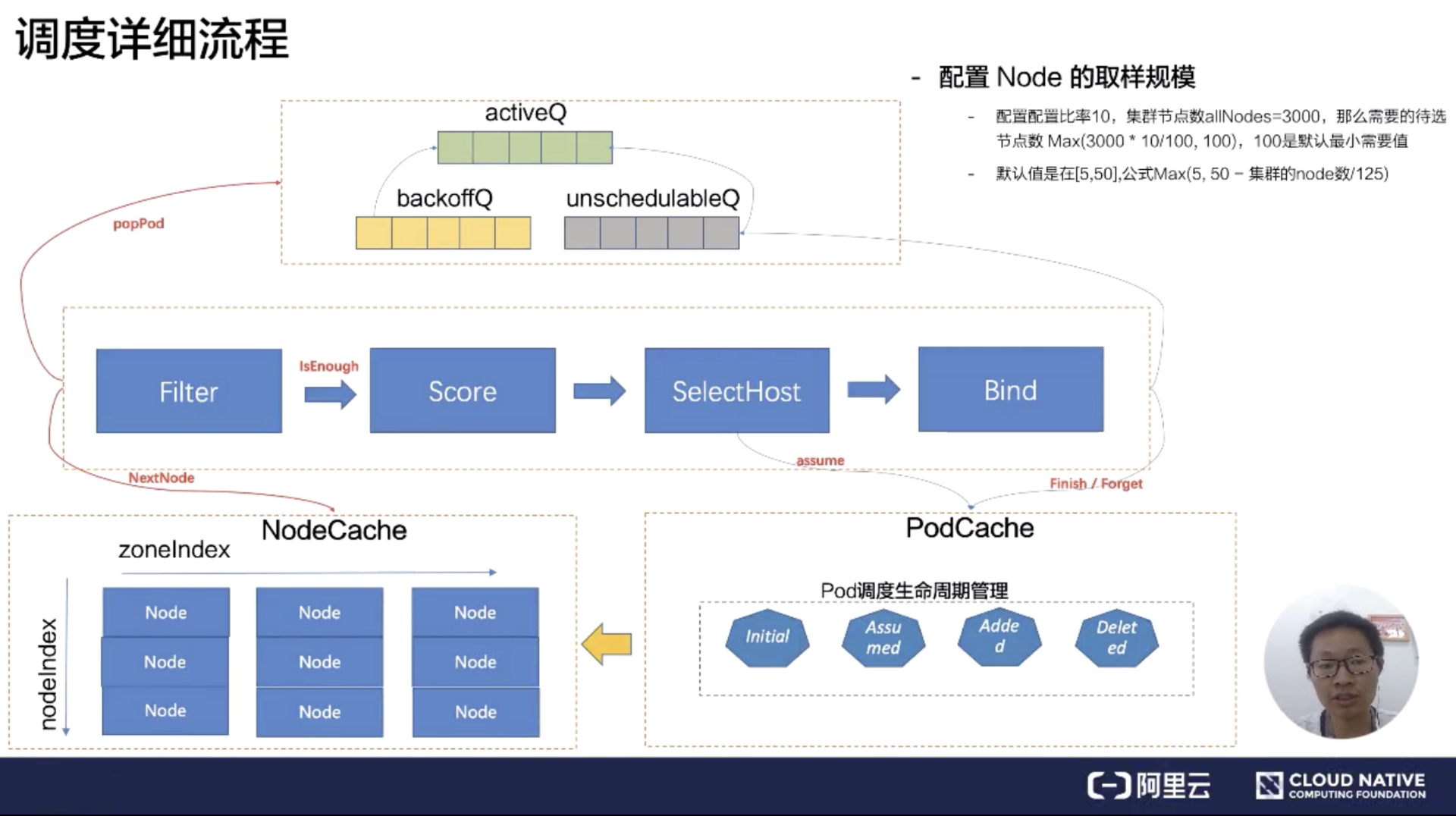
**SchedulingQueue **有三個子隊列 activeQ、backoffQ、unschedulableQ。
Scheduler 啟動的時候所有等待被調度的 Pod 都會進入 activieQ,activeQ 會按照 Pod 的 priority 進行排序,Scheduler Pipepline 會從 activeQ 獲取一個 Pod 進行 Pipeline 執行調度流程,當調度失敗之后會直接根據情況選擇進入 unschedulableQ 或者 backoffQ,如果在當前 Pod 調度期間 Node Cache、Pod Cache 等 Scheduler Cache 有變化就進入 backoffQ,否則進入 unschedulableQ。
unschedulableQ 會定期較長時間(例如 60 秒)刷入 activeQ 或者 backoffQ,或者在 Scheduler Cache 發生變化的時候觸發關聯的 Pod 刷入 activeQ 或者 backoffQ;backoffQ 會以 backoff 機制相比 unschedulableQ 比較快地讓待調度的 Pod 進入 activeQ 進行重新調度。
接著詳細介紹 Scheduler Thread 階段,在 Scheduler Pipeline 拿到一個等待調度的 Pod,會從 NodeCache 里面拿到相關的 Node 執行 Filter 邏輯匹配,這從 NodeCache 遍歷 Node 的過程有一個空間算法上的優化,簡單可以概括為在避免過濾所有節點的同時考慮了調度的容災取樣調度。
具體的優化算法邏輯(有興趣的同學可以看 node_tree.go 的 Next 方法):在 NodeCache 中,Node 是按照 zone 進行分堆。在 filter 階段的時候,為會 NodeCache 維護一個 zondeIndex,每 Pop 一個 Node 進行過濾,zoneIndex 往后挪一個位置,然后從該 zone 的 node 列表中取一個 node 出來。
可以看到上圖縱軸有一個 nodeIndex,每次也會自增。如果當前 zone 的節點無數據,那就會從下一個 zone 中拿數據。大概的流程就是 zoneIndex 從左向右,nodeIndex 從上到下,保證拿到的 Node 節點是按照 zone 打散,從而實現避免過濾所有節點的同時考慮了節點的 az 均衡部署。(最新 release-v.1.17 的版本已經取消這種算法,為什么取消應該是沒有考慮 Pod 的 prefer 和 node 的 prefer,沒有實現 Pod 的 Spec 要求)
取樣調度里面的取樣規模這里簡單介紹一下,默認的取樣比率公式 = Max (5, 50 - 集群的 node 數 / 125),取樣規模 = Max (100, 集群 Node 數*取樣比率)。
這里舉個例子:節點規模為 3000 個節點,那么**取樣比例 = Max (5, 50 - 3000/125) = 26%,那么取樣規模 *= Max (100, 3000 0.26) = 780,在調度流水線里面,Filter 只要匹配到 780 個候選節點,就可以停止 Filter 流程,走到 Score 階段。
Score 階段依據 Policy 配置的算分插件,進行排序,分數最高的節點作為 SelectHost。接著將這個 Pod 分配到這個 Node 上,這個過程叫做 Reserver 階段可以稱為賬本預占。預占的過程修改 Pod 在 PodCache 的狀態為 Assumed 的狀態(處于內存態)。
調度過程涉及到 Pod 狀態機的生命周期,這里簡單介紹下 Pod 的幾個主要狀態: Initial(虛擬狀態)->Assumed(Reserver)->Added->Deleted(虛擬狀態); 當通過 Informer watch 到 Pod 數據已經確定分配到這個節點的時候,才會把 Pod 的狀態變成 Added。選中完節點在 Bind 的時候,有可能會 Bind 失敗,在 Bind 失敗的時候會做回退,就是把預占用的賬本做 Assumed 的數據退回 Initial,也就是把 Assumed 狀態擦除,從 Node 里面把 Pod 賬本清除。
如果 Bind 失敗,會把 Pod 重新丟回到 unschedulableQ 隊列里面。在調度隊列中,什么情況下 Pod 會到 backoffQ 中呢?這是一個很細節的點。如果在這么一個調度周期里面,Cache 發生了變化,會把 Pod 放到 backoffQ 里面。在 backoffQ 里面等待的時間會比在 unschedulableQ 里面時間更短,backoffQ 里有一個降級策略,是 2 的指數次冪降級。假設重試第一次為 1s,那第二次就是 2s,第三次就是 4s,第四次就是 8s,最大到 10s。
Filter 根據功能用途可以把它們分為四類:
存儲匹配相關
Pode 和 Node 匹配相關
Pod 和 Pod 匹配相關
Pod 打散相關
存儲相關的幾個過濾器的功能:
NoVolumeZoneConflict,pvc 關聯的 pv 的 label 上設置 zone\az 限制待匹配的節點要跟 pv;
MaxCSIVolumeCountPred,是用來校驗 pvc 上指定的 Provision 在 CSI plugin 上的單機最大 pv 數限制;
CheckVolumeBindingPred,在 pvc 和 pv 的 binding 過程中對其進行邏輯校驗,里頭的邏輯寫的比較復雜,主要都是如何復用 pv;
NoDiskConfict,SCSI 存儲不會被重復的 volume。
**CheckNodeCondition:**校驗節點是否準備好被調度,校驗node.condition的condition type :Ready為true和NetworkUnavailable為false以及Node.Spec.Unschedulable為false;
**CheckNodeUnschedulable:**在 node 節點上有一個 NodeUnschedulable 的標記,我們可以通過 kube-controller 對這個節點直接標記為不可調度,那這個節點就不會被調度了。在 1.16 的版本里,這個 Unschedulable 已經變成了一個 Taints。也就是說需要校驗一下 Pod 上打上的 Tolerates 是不是可以容忍這個 Taints;
**PodToleratesNodeTaints:**校驗 Node 的 Taints 是否被 Pod Tolerates 包含;
**PodFitsHostPorts:**校驗 Pod 上的 Container 聲明的 Ports 是否正在被 Node 上已經分配的 Pod 使用;
MatchNodeSelector: 校驗 Pod.Spec.Affinity.NodeAffinity 和 Pod.Spec.NodeSelector 是否與 Node 的 Labels 匹配。
MatchinterPodAffinity:主要是 PodAffinity 和 PodAntiAffinity 的校驗邏輯,這里面最大的復雜度是在于 Affinity 里面的 PodAffinityTerm 描述支持的 TopologyKey(可以表示在 node/zone/az 等拓撲結構上),這個其實是一個性能殺手。
EvenPodsSpread
CheckServiceAffinity
這是一個新的功能特性,首先來看一下 EvenPodsSpread 中 Spec 描述:<br />-- 描述符合條件的一組 Pod 在指定 TopologyKey 上的打散要求。
下面我們來看一下怎么描述一組 Pod,如下圖所示:
spec: topologySpreadConstraints: - maxSkew: 1 whenUnsatisfiable: DoNotSchedule topologyKey: k8s.io/hostname selector: matchLabels: app: foo matchExpressions: - key: app operator: In values: ['foo', 'foo2']
topologySpreadConstraints: 用于描述 Pod 要在什么拓撲結構上進行均衡打散,多個 topologySpreadConstraint 之間是 and 關系; selector:用于描述需要滿足的拓撲打散的一組 Pod 的列表 topologyKey: 作用在什么拓撲結構上; maxSkew: 最大允許的不均衡數量; whenUnsatisfiable: 當不滿足 topologySpreadConstraint 的時候的策略,DoNotSchedule:表示作用于 filter 階段,ScheduleAnyway:作用于 score 階段。 下面舉例描述下: 
selector 選擇的是所有 lable 符合 app=foo 的 pod,必須在 zone 級別是打散的,允許最大不均衡數為 1。 集群中有三個 zone,上圖中 label 的值 app=foo 的 Pod 在 zone1 和 zone2 中都分配了一個 pod。 計算不均衡數量公式為:ActualSkew = count[topo] - min(count[topo]) 首先,依據 selector 獲取到符合條件的 Pod 列表 其次,會按照 topologyKey 去分組得到 count[topo]
如上圖所示:
假設 maxSkew 為 1,如果分配到 zone1/zone2,skew 的值為2,大于前面設置的 maxSkew。這是不匹配的,所以只能分配到 zone3。如果分配到 zone3 的話,min(count[topo]) 為1,count[topo]為 1,那 skew 就等于 0,因此只能分配到 zone2。
假設 maxSkew 為 2,分配到 z1(z2),skew 的值為 2/1/0(1/2/0),最大值為 2,滿足 <=maxSkew。那 z1/z2/z3 都是允許被選擇的。
通過 EvenPodsSpread 可以實現一組 Pod 在某個 TopologyKey 上的均衡打散需求,如果必須要求每個 topo 上都均衡可以設 maxSkew 為1,當然這個描述缺乏了一些控制,例如必須分配在多少個 topologyValue 上的限制。
接下來看一下打分算法,打分算法主要解決的問題就是集群的碎片、容災、水位、親和、反親和等。
按照類別可以分為四大類:
Node 水位
Pod 打散 (topp,service,controller)
Node 親和&反親和
Pod 親和&反親和
接下來介紹打分器相關的第一個資源水位。 
節點打分算法跟資源水位相關的主要有四個,如上圖所示。 
資源水位公式的概念
Request:Node 已經分配的資源;Allocatable:Node 的可調度的資源
優先打散
把 Pod 分到資源空閑率最高的節點上,而非空閑資源最大的節點,公式:資源空閑率=(Allocatable - Request) / Allocatable,當這個值越大,表示分數越高,優先分配到高分數的節點。其中**(Allocatable - Request)**表示為Pod分配到這個節點之后空閑的資源數。
優先堆疊
把 Pod 分配到資源使用率最高的節點上,公式:資源使用率 = Request / Allocatable ,資源使用率越高,表示得分越高,會優先分配到高分數的節點。
碎片率
是指 Node 上的多種資源之間的資源使用率的差值,目前支持 CPU/Mem/Disk 三類資源, 假如僅考慮 CPU/Mem,那么碎片率的公式 = Abs[CPU(Request / Allocatable) - Mem(Request / Allocatable)] 。舉一個例子,當 CPU 的分配率是 99%,內存的分配率是 50%,那么碎片率 = 99% - 50% = 50%,那么這個例子中剩余 1% CPU, 50% Mem,很難有這類規格的容器能用完 Mem。得分 = 1 - 碎片率,碎片率越高得分低。
指定比率
可以在 Scheduler 啟動的時候,為每一個資源使用率設置得分,從而實現控制集群上 node 資源分配分布曲線。

Pod 打散為了解決的問題為:支持符合條件的一組 Pod 在不同 topology 上部署的 spread 需求。
SelectorSpreadPriority
用于實現 Pod 所屬的 Controller 下所有的 Pod 在 Node 上打散的要求。實現方式是這樣的:它會依據待分配的 Pod 所屬的 controller,計算該 controller 下的所有 Pod,假設總數為 T,對這些 Pod 按照所在的 Node 分組統計;假設為 N (表示為某個 Node 上的統計值),那么對 Node上的分數統計為 (T-N)/T 的分數,值越大表示這個節點的 controller 部署的越少,分數越高,從而達到 workload 的 pod 打散需求。
ServiceSpreadingPriority
官方注釋上說大概率會用來替換 SelectorSpreadPriority,為什么呢?我個人理解:Service 代表一組服務,我們只要能做到服務的打散分配就足夠了。
EvenPodsSpreadPriority
用來指定一組符合條件的 Pod 在某個拓撲結構上的打散需求,這樣是比較靈活、比較定制化的一種方式,使用起來也是比較復雜的一種方式。
因為這個使用方式可能會一直變化,我們假設這個拓撲結構是這樣的:Spec 是要求在 node 上進行分布的,我們就可以按照上圖中的計算公式,計算一下在這個 node 上滿足 Spec 指定 labelSelector 條件的 pod 數量,然后計算一下最大的差值,接著計算一下 Node 分配的權重,如果說這個值越大,表示這個值越優先。

NodeAffinityPriority,這個是為了滿足 Pod 和 Node 的親和 & 反親和;
ServiceAntiAffinity,是為了支持 Service 下的 Pod 的分布要按照 Node 的某個 label 的值進行均衡。比如:集群的節點有云上也有云下兩組節點,我們要求服務在云上云下均衡去分布,假設 Node 上有某個 label,那我們就可以用這個 ServiceAntiAffinity 進行打散分布;
NodeLabelPrioritizer,主要是為了實現對某些特定 label 的 Node 優先分配,算法很簡單,啟動時候依據調度策略 (SchedulerPolicy)配置的 label 值,判斷 Node 上是否滿足這個label條件,如果滿足條件的節點優先分配;
ImageLocalityPriority,節點親和主要考慮的是鏡像下載的速度。如果節點里面存在鏡像的話,優先把 Pod 調度到這個節點上,這里還會去考慮鏡像的大小,比如這個 Pod 有好幾個鏡像,鏡像越大下載速度越慢,它會按照節點上已經存在的鏡像大小優先級親和。
InterPodAffinityPriority
先介紹一下使用場景:
第一個例子,比如說應用 A 提供數據,應用 B 提供服務,A 和 B 部署在一起可以走本地網絡,優化網絡傳輸;
第二個例子,如果應用 A 和應用 B 之間都是 CPU 密集型應用,而且證明它們之間是會互相干擾的,那么可以通過這個規則設置盡量讓它們不在一個節點上。
NodePreferAvoidPodsPriority
用于實現某些 controller 盡量不分配到某些節點上的能力;通過在 node 上加 annotation 聲明哪些 controller 不要分配到 Node 上,如果不滿足就優先。

怎么啟動一個調度器,這里有兩種情況:
第一種我們可以通過默認配置啟動調度器,什么參數都不指定;
第二種我們可以通過指定配置的調度文件。
如果我們通過默認的方式啟動的話,想知道默認配置啟動的參數是哪些?可以用 --write-config-to 可以把默認配置寫到一個指定文件里面。 下面來看一下默認配置文件,如下圖所示: 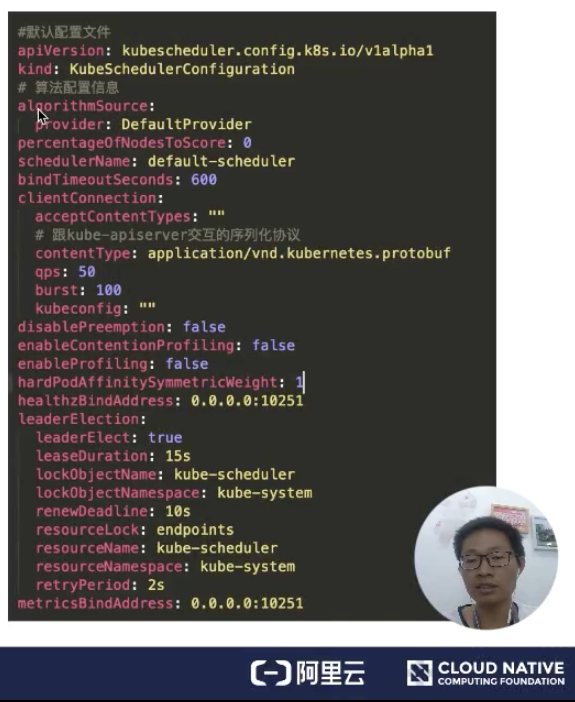
**algorithmSource **:算法提供者,目前提供三種方式:Provider、file、configMap,后面會介紹這塊;
**percentageOfNodesToscore **: 調度器提供的一個擴展能力,能夠減少 Node 節點的取樣規模;
**schedulerName **:用來表示調度器啟動的時候,負責哪些 Pod 的調度;如果沒有指定的話,默認名稱就是 default-scheduler;
**bindTimeoutSeconds **:用來指定 bind 階段的操作時間,單位是秒;
clientConnection: 用來配置跟 kube-apiserver 交互的一些參數配置。比如 contentType,是用來跟 kube-apiserver 交互的序列化協議,這里指定為 protobuf;
**disablePreemption **:關閉搶占調度;
**hardPodAffinitySymnetricweight **:配置 PodAffinity 和 NodeAffinity 的權重是多少。

這里介紹一下過濾器、打分器等一些配置文件的格式,目前提供三種方式:
Provider
file
configMap
如果指定的是 Provider,有兩種實現方式:
一種是 DefaultPrivider;
一種是 ClusterAutoscalerProvider。
ClusterAutoscalerProvider 是優先堆疊的,DefaultPrivider 是優先打散的。關于這個策略,當你的節點開啟了自動擴容,盡量使用 ClusterAutoscalerProvider 會比較符合你的需求。
這里看一下策略文件的配置內容,如下圖所示:
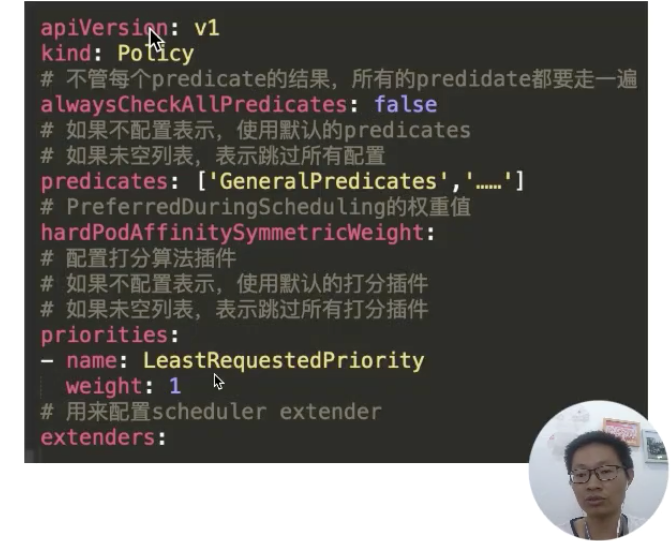
這里可以看到配置的過濾器 predicates,配置的打分器 priorities,以及我們配置的擴展調度器。這里有一個比較有意思的參數就是:alwaysCheckAllPredicates。它是用來控制當過濾列表有個返回 false 時,是否繼續往下執行?默認的肯定是 false;如果配置成 true,它會把每個插件都走一遍。

首先來看一下 Schedule Extender 能做什么?在啟動官方調度器之后,可以再啟動一個擴展調度器。
通過配置文件,如上文提到的 Polic 文件中 extender 的配置,包括 extender 服務的 URL 地址、是否 https 服務,以及服務是否已經有 NodeCache。如果有 NodeCache,那調度器只會傳給 nodenames 列表。如果沒有開啟,那調度器會把所有 nodeinfo 完整結構都傳遞過來。
ignorable 這個參數表示調度器在網絡不可達或者是服務報錯,是否可以忽略擴展調度器。managedResources,官方調度器在遇到這個 Resource 時會用擴展調度器,如果不指定表示所有的都會使用擴展調度器。
這里舉個 GPU share 的例子。在擴展調度器里面會記錄每個卡上分配的內存大小,官方調度器只負責 Node 節點上總的顯卡內存是否足夠。這里擴展資源叫 example/gpu-men: 200g,假設有個 Pod 要調度,通過 kube-scheduler 會看到我們的擴展資源,這個擴展資源配置要走擴展調度器,在調度階段就會通過配置的 url 地址來調用擴展調度器,從而能夠達到調度器能夠實現 gpu-share 的能力。
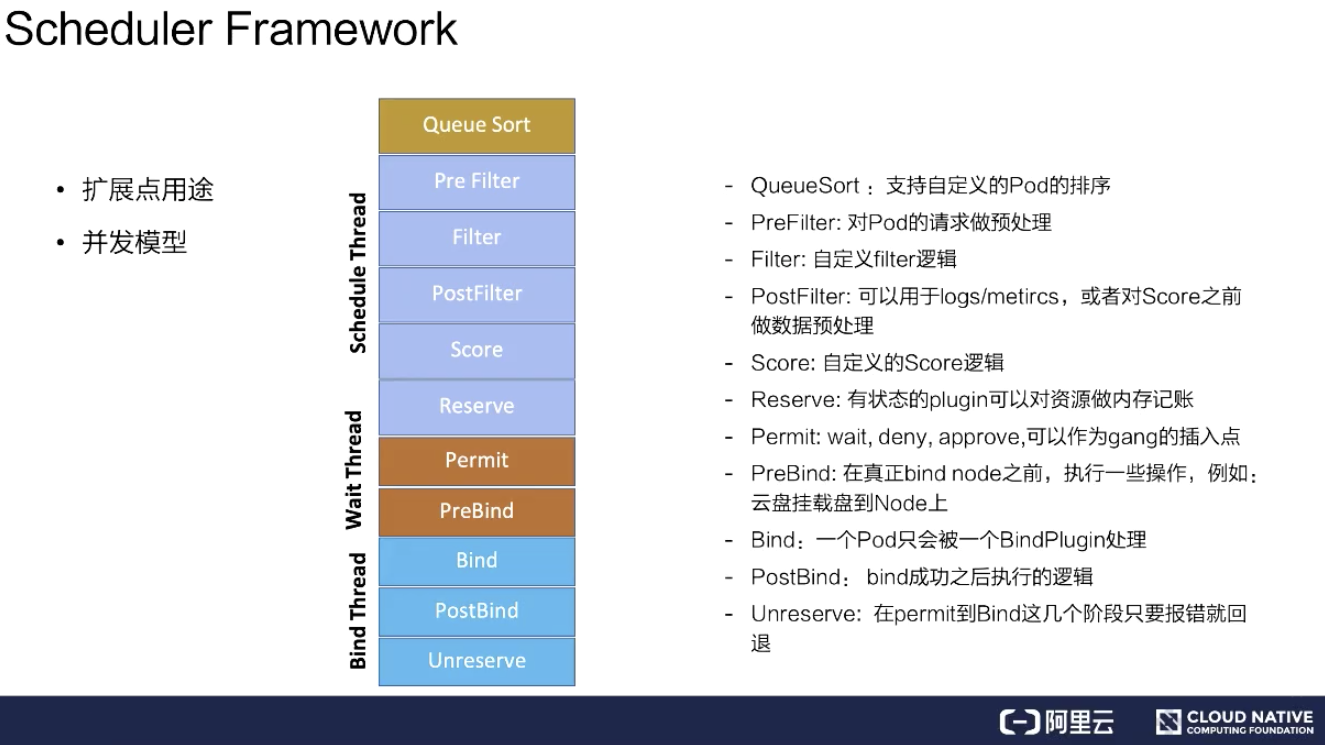
這里分成兩點來說,從擴展點用途和并發模型分別介紹。
擴展點的主要用途主要有以下幾個:
QueueSort:用來支持自定義 Pod 的排序。如果指定 QueueSort 的排序算法,在調度隊列里面就會按照指定的排序算法來進行排序;
Prefilter:對 Pod 的請求做預處理,比如 Pod 的緩存,可以在這個階段設置;
Filter:就是對 Filter 做擴展,可以加一些自己想要的 Filter,比如說剛才提到的 gpu-shared 可以在這里面實現;
PostFilter:可以用于 logs/metircs,或者是對 Score 之前做數據預處理。比如說自定義的緩存插件,可以在這里面做;
Score:就是打分插件,通過這個接口來實現增強;
Reserver:對有狀態的 plugin 可以對資源做內存記賬;
Permit:wait、deny、approve,可以作為 gang 的插入點。這個可以對每個 pod 做等待,等所有 Pod 都調度成功、都達到可用狀態時再去做通行,假如一個 pod 失敗了,這里可以 deny 掉;
PreBind:在真正 bind node 之前,執行一些操作,例如:云盤掛載盤到 Node 上;
Bind:一個 Pod 只會被一個 BindPlugin 處理;
PostBind:bind 成功之后執行的邏輯,比如可以用于 logs/metircs;
Unreserve:在 Permit 到 Bind 這幾個階段只要報錯就回退。比如說在前面的階段 Permit 失敗、PreBind 失敗, 都會去做資源回退。
并發模型意思是主調度流程是在 Pre Filter 到 Reserve,如上圖淺藍色部分所示。從 Queue 拿到一個 Pod 調度完到 Reserve 就結束了,接著會把這個 Pod 異步交給 Wait Thread,Wait Thread 如果等待成功了,就會交給 Bind Thread,就是這樣一個線程模型。
如何編寫注冊自定義 Plugin? 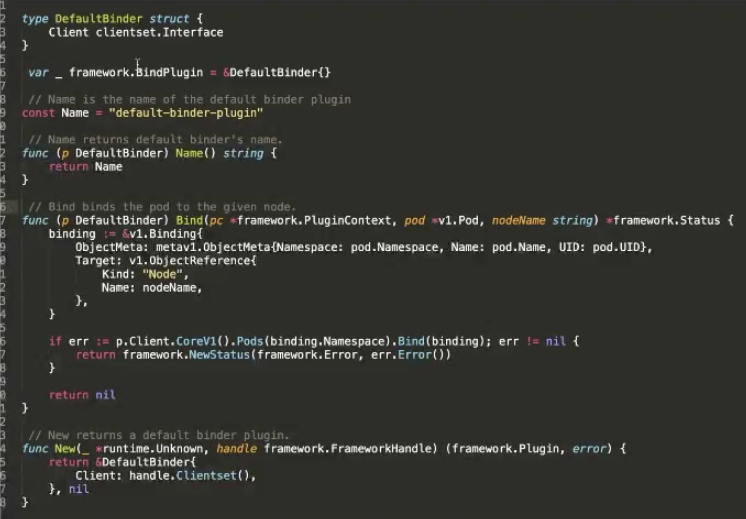
這里是一個官方的例子,在 Bind 階段,要將 Pod 綁定到某個 Node 上,對 Kube-apiserver 做 Bind。這里可以看到主要有兩個接口,bind 的接口是聲明調度器的名稱,以及 bind 的邏輯是什么。最后還要實現一個構造方法,告訴它的構造方法是怎樣的邏輯。
啟動自定義 Plugin 的調度器:
vendor
fork
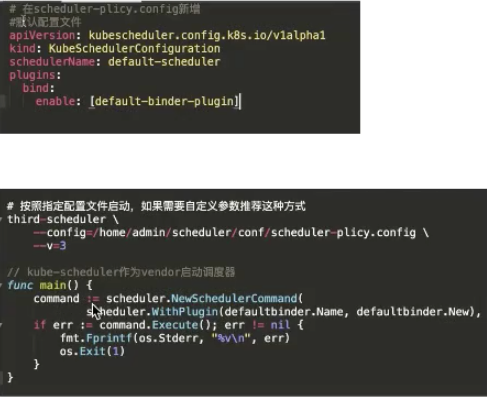
在啟動的時候可以通過兩種方式去注冊:
第一種方式是通過自己編寫一個腳本,通過 vendor 把調度器的代碼 vendor 進來。在啟動 scheduler.NewSchedulerCommand 的時候把 defaultbinder 注冊進去,這樣就可以啟動一個調度器;
第二種方式是可以 fork kube-scheduler 的源代碼,然后把調度器的 defaultbinder 通過 register 插件注冊進去。注冊完這個插件,去 build 一個腳本、build 一個鏡像,然后啟動的時候,在配置文件的 plugins.bind.enable 啟動起來。
第一部分跟大家介紹了下調度器的整體工作流程,以及一些計算的算法優化;
第二部分詳細介紹調度的主要幾個工作組件過濾器組件、score 組件的實現,并列舉幾個 score 的使用場景;
第三部分介紹調度器的配置文件的用法說明,讓大家可以通過這些配置來實現自己期望的調度行為;
第四部分介紹了一些高級用法,怎么通過 extender/framework 擴展調度能力,來滿足特殊業務場景的調度需求。
上述內容就是如何理解k8s調度器的調度流程和算法,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





