溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關Dataphin怎樣幫助企業萃取數據中心,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
Dataphin作為阿里巴巴數據中臺OneData (OneModel、OneID、OneService)方法論的產品載體,幫助企業構建三大數據中心:基于數據集成形成的垂直數據中心、基于數據開發沉淀的公共數據中心和基于標簽工廠構建的萃取數據中心。今天我們就一起來看看,Dataphin是如何基于OneID思想構建數據萃取中心,連接上下游應用為企業創造更多價值的吧~
為什么要建立萃取數據中心:提升數據價值密度
首先,我們來看看Dataphin為什么要幫助企業構建自己的萃取數據中心?
大數據時代,任何微小的數據都可能產生不可思議的價值。作為智能數據構建與管理平臺,Dataphin的規范建模、數據處理等核心功能幫助企業高效整合來自不同業務數據庫的海量數據,沉淀數據資產,構建自己的數據中臺,應對大數據時代Volume(大量)、Variety(多樣)、Velocity(高速)方面的挑戰。然而,相比于傳統的小數據,大數據更大的價值在于從海量不相關的各類數據中,挖掘出對預測分析有參考意義的數據,提升數據價值密度并應用于指導生產,從而幫助企業實現提效降本的目的。Dataphin的數據萃取功能正提供了這樣的能力。
從業務視角來看,日常生產和營銷活動中,不管是人群圈選、選址還是個性化投放,都離不開標簽的指導。標簽是對一個實體的立體刻畫(不局限于人,任何可被描述和分析的存在都可以是實體,如商品、公司等)。不同維度的標簽從不同角度對實體進行描述,例如以零售視角為切入點,我們可以從自然屬性(如性別、年齡)、社會屬性(如經濟狀況、婚姻狀態)、興趣偏好(如喜歡整潔的環境、希望有漂亮的牙齒)和行業消費偏好(如美妝偏好、母嬰偏好)來對消費者進行描述。高質量、全面的標簽能夠有效地抽象出一個實體的信息全貌,為精準營銷奠定了基礎。
數據只有融通才能產生更大的價值,我們不僅希望可以分析和應用大數據,更希望得到通過跨業務單元連接起來的數據和精細化萃取的數據。這種情況下,Dataphin數據萃取模塊基于業務數據庫的原始數據和建模研發等沉淀的數據資產,將全系統中主數據——即貫穿各個隔離業務的核心對象,進行識別與關聯連接,打通業務數據孤島,進一步提煉可直接應用的高價值標簽數據,從而幫助企業構建自己的萃取數據中心,并對接上游應用(QuickAudience等)進一步指導生產營銷活動。
如何高效建立萃取數據中心:可視化配置,自動化生產
Dataphin研發模塊下的數據萃取為我們提供了連接行為數據并實現標簽萃取的功能,現階段優先支持以消費者為對象的數據體系,功能模塊主要包括3 大部分:ID中心、行為中心和標簽中心(目前ID中心暫未上線)。此外,運維模塊下還提供單獨的萃取運維子模塊,支持從業務視角查看萃取相關的調度任務。下面,我們將從幾個功能模塊的視角給大家介紹Dataphin如何幫助企業構建自己的萃取數據中心。
cdn.com/95221d8f99c5611687fcfb363c72554d0071f209.png">
1)ID中心:相關ID自動化識別與連接
Dataphin基于OneID的思想,以唯一標識打通來自不同平臺、系統、渠道的數據,支持通過可視化界面參數配置的方式,從所有數據中提煉并基于算法自動識別各類型ID 之間的映射關系(購物會員ID、視頻觀看者ID、購物設備mac、觀看設備IP 等),并將屬于同一實體的不同類型ID通過唯一的One ID進行連接,使得基于ID生產的標簽可以聚合到同一實體,從而對實體進行更精準、全面的刻畫。
2)行為中心:沉淀行為元素,構建行為規則
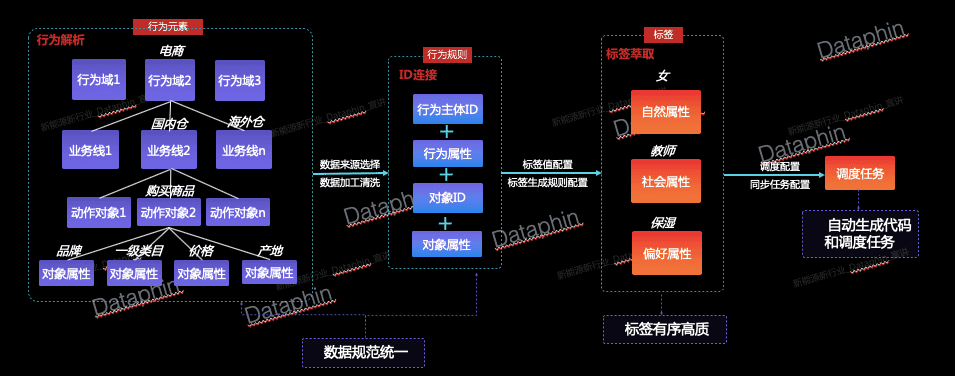
Dataphin目前支持以人的相關ID 為中心,通過可視化界面表單配置的方式,從來源行為數據中提煉進而聚攏不同業務域下的行為數據(如電商購物、視頻觀看)。
首先,我們需要從業務視角對行為數據進行梳理,從中提煉出可復用的行為元素(行為域、業務線、動作、對象、對象屬性),并通過對行為元素進行組合定義不同的行為(行為域-業務線-動作-對象)。行為域聚合業務含義一致的行為數據,如電商域、文娛域;業務線基于行為域將行為數據進一步細分,各業務線之間相對獨立,如淘寶業務線、天貓業務線;動作指行為主體發出的操作,如購買、瀏覽;對象指行為主體操作的具體事物,如商品、電影;對象屬性是對象的描述性信息,如名稱、品牌、年份。通過抽取沉淀行為元素,我們可以將來源數據更好地進行劃分組合以得到具有明確業務含義的行為,如電商域-淘寶-購買-商品、文娛域-優酷-瀏覽-電影。通過沉淀行為元素,我們可以更好地規范來源數據,并減少重復建設和人力投入。
給同一行為選擇不同的來源表并添加配置,即生成不同的行為規則(由行為+來源表唯一確定),后續標簽生產將依賴已經構建的行為和行為規則。規則配置主要包括行為主體ID、對象、對象屬性和行為發生次數,從來源表選擇相應的字段,再通過行為規則的周期調度任務,我們就能得到持續更新的行為數據作為標簽生產的來源。
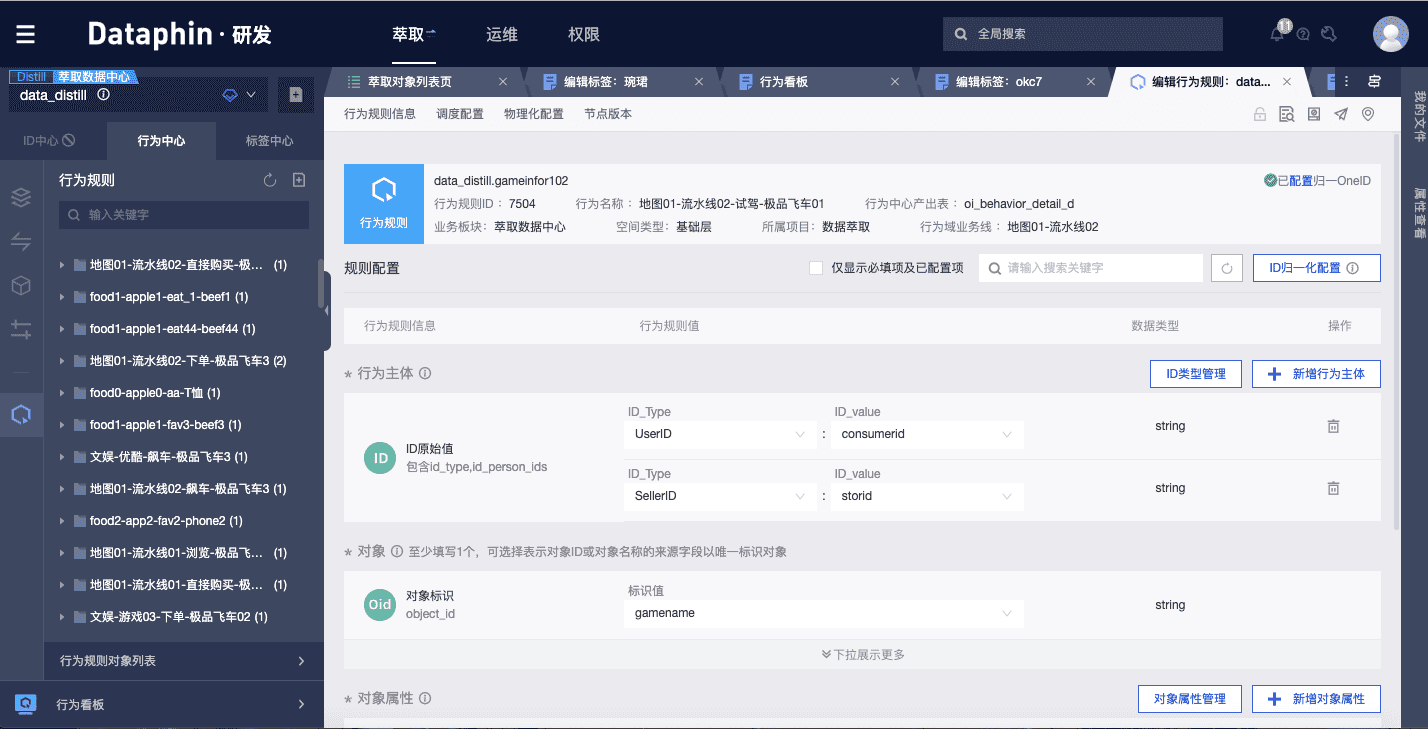
3)標簽中心:高效標簽生產
構建完成行為和行為規則后,進一步地,我們將基于算法模型,通過簡單的界面配置定義標簽的生成規則。
標簽的配置分為兩大步驟:第一步首先基于定義的行為圈選出某標簽需要依賴的行為數據,接著對預期得到的標簽值和打標方式進行配置;第二步需要對已選的行為數據設置時間衰減模式,并基于業務含義給不同的行為分配不同的權重。例如,我們認為“購買母嬰用品”和“觀看親子視頻”的用戶都可以被打上“母嬰人群”的標簽,那么第一步,我們將這兩種行為相關的數據都勾選出來,設置預期標簽值為“母嬰人群”;第二步,我們認為近期的行為比之前發生的行為更有參考性,因此選擇線性衰減模式,給近期行為賦予更大的時間權重;同時,基于業務經驗,我們認為“購買母嬰用品”比“觀看親子視頻”更能精確定位到目標用戶,所以給“購買母嬰用品”行為分配更大的權重。這樣,我們就完成了“母嬰人群”這樣一個購物偏好標簽的生產。
不同于傳統標簽生產,Dataphin數據萃取的用戶只需要關心標簽的具體業務含義和規則,而不用關心底層算法的實現,通過簡單的界面操作即可完成標簽的配置,并自動生成代碼和周期調度任務,極大程度上降低了標簽生產的難度和門檻。
4)萃取運維
最后,我們在萃取模塊配置的行為規則和標簽都會生成自動化調度的周期任務。在“運維”界面的“萃取運維”子模塊下,我們可以從業務視角更清晰明了地查看相應任務和對應生成的實例,并針對異常調度通過補數據等操作回復生產。如此一來,業務人員也可以配置并查看萃取任務,大大降低了對技術人員的依賴。
Dataphin數據萃取功能上線后,批量生產十幾個同類型的標簽的時間從兩周縮短到兩天左右,而且可以監控標簽生產任務,不管是速度還是正確性上都得到了很大的提升;參與的人員也從原本的數據產品經理、數據研發工程師、數據科學家為主導轉變為更多的業務角色可以參與甚至主導。
Dataphin萃取數據中心的建立,幫助企業更好的實現了目標對象相關ID 的識別與連接、目標對象所有行為的規范化結構化聚集和目標對象相關標簽屬性的快速創建,從而快速構建企業自己用戶數據資產,以便對接數據應用類產品,實現營銷投放等。
看完上述內容,你們對Dataphin怎樣幫助企業萃取數據中心有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





