溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
hdfs基本概念(設計思想 特性 工作機制 上傳下載 namenode存儲元數據機制)
1、hdfs總的設計思想:
設計目標:提高分布式并發處理數據的效率(提高并發度和移動運算到數據)
分而治之:將大文件、大批量文件,分布式存放在大量獨立的服務器上,以便于采取分而治之的方式對海量數據進行運算分析;
重點概念:文件切塊,副本存放,元數據,位置查詢,數據讀寫流
2、hdfs的shell操作 //見響應的單獨文檔
3、hdfs的一些概念
Hdfs分布式文件系統的基本工作機制及相關概念解析 //見畫圖
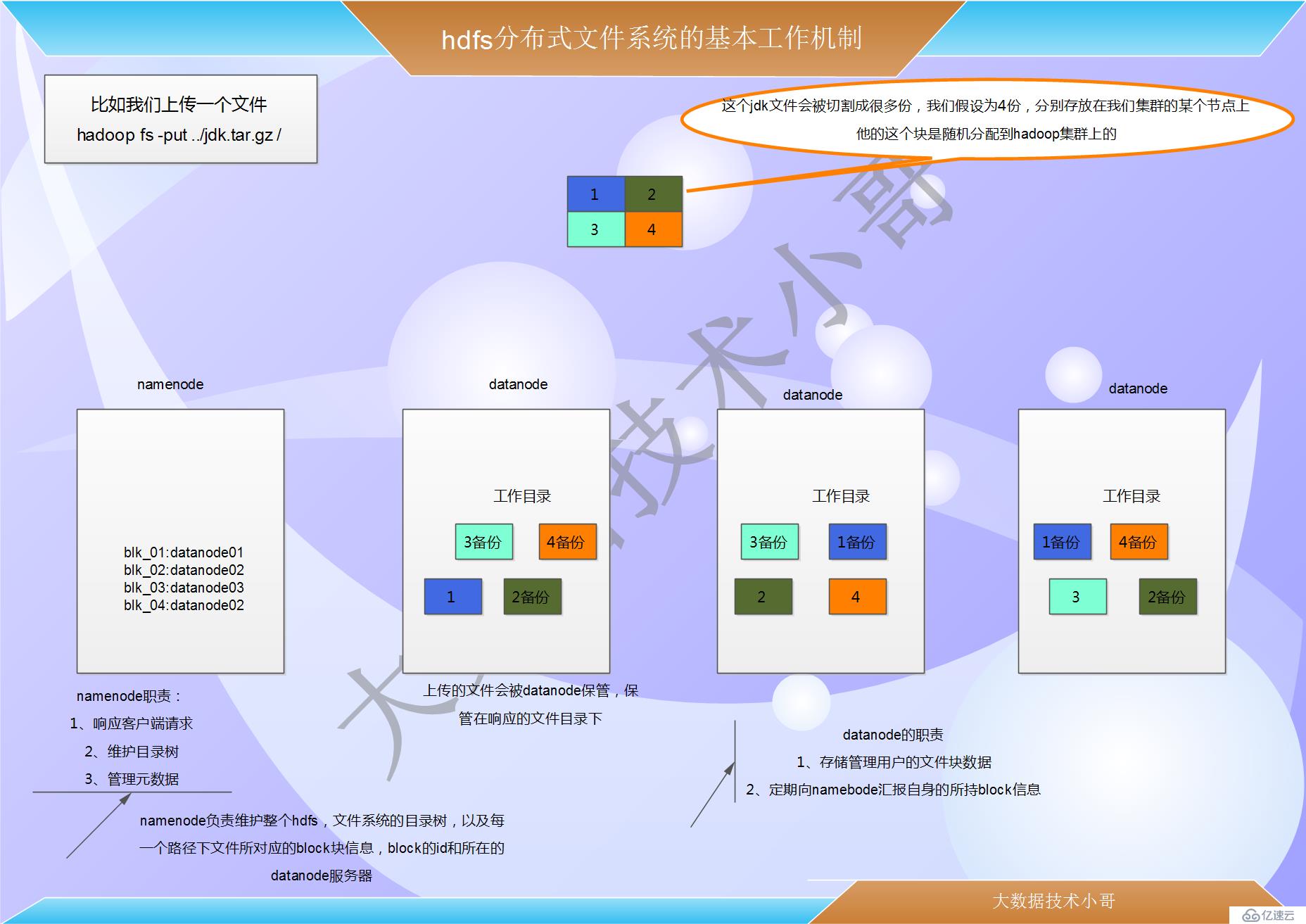
首先,它是一個文件系統,有一個統一的命名空間——目錄樹, 客戶端訪問hdfs 文件時就是
通過指定這個目錄樹中的路徑來進行
其次,它是分布式的,由很多服務器聯合起來實現功能;
? hdfs 文件系統會給客戶端提供一個統一的抽象目錄樹,Hdfs 中的文件都是分塊(block)
存儲的,塊的大小可以通過配置參數( dfs.blocksize)來規定,默認大小在hadoop2.x 版本
中是128M,老版本中是64M
? 文件的各個block 由誰來進行真實的存儲呢?----分布在各個datanode 服務節點上,而
且每一個block 都可以存儲多個副本(副本數量也可以通過參數設置dfs.replication,默
認值是3)
? Hdfs 中有一個重要的角色:namenode,負責維護整個hdfs 文件系統的目錄樹,以及每
一個路徑(文件)所對應的block 塊信息(block 的id,及所在的datanode 服務器)
? hdfs 是設計成適應一次寫入,多次讀出的場景,并不支持文件的修改
(hdfs 并不適合用來做網盤應用,因為,不便修改,延遲大,網絡開銷大,成本太高)
hdfs 切片的定義 概念
1:定義一個切片大小:可以通過參數來調節,默認情況下等于“hdfs 中設置的blocksize”,通常是128M
2:獲取輸入數據目錄下所有待處理文件List
3:遍歷文件List,逐個逐個文件進行切片
for(file:List)
對file 從0 偏移量開始切,每到128M 就構成一個切片,比如a.txt(200M),就會被切成兩個切片: a.txt: 0-128M, a.txt :128M-256M
再比如b.txt(80M),就會切成一個切片, b.txt :0-80M
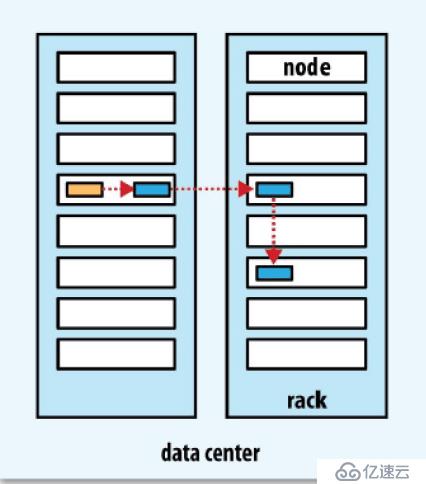
HDFS Block復制策略
–第1個副本放在客戶端所在節點
?如果是遠程客戶端,block會隨機選擇節點
?系統會首先選擇空閑的DataNode節點
–第2個副本放在不同的機架節點上
–第3個副本放在與第2個副本同一機架的不同機器上
–很好的穩定性、負載均衡,較好的寫入帶寬、讀取性能,塊均勻分布
–機架感知:將副本分配到不同的機架上,提高數據的高容錯性
–以節點為備份對象
4、特性:
容量可以線性擴展
數據存儲高可靠
分布式運算處理很方便
數據訪問延遲較大,不支持數據的修改操作
適合一次寫入多次讀取的應用場景
5、hdfs 的工作機制
HDFS 集群分為兩大角色:NameNode、DataNode
NameNode 負責管理整個文件系統的元數據
DataNode 負責管理用戶的文件數據塊
6、namenode 工作機制
namenode 職責:
1、響應客戶端請求 //客戶端去請求hdfs的時候都會先去找namenode
2、維護目錄樹 //客戶端去讀或者寫文件的時候都會去指定一個目錄,這個目錄是hdfs的目錄,這個目錄有namenode管理
3、管理元數據(查詢,修改) *****
//什么是元數據
文件的描述信息:某一個路徑的文件有幾個block,每一個block在那些datanode上面有存儲,一個文件的副本數量是幾?這些信息就是元數據,元數據很重要,不能發生丟失或者錯誤,那么在客戶端請求的時候,就有可能請求不到。
提示:內存中存儲了一份完整的元數據,包括目錄樹結構,以及文件和數據塊和副本存儲地 的映射關系;
7、datanode 的工作機制
1、Datanode 工作職責:
2、存儲管理用戶的文件塊數據
3、定期向namenode 匯報自身所持有的block 信息(通過心跳信息上報)
4、上傳一個文件,觀察文件的block 具體的物理存放情況
在每一臺datanode 機器上的這個目錄:
/home/hadoop/app/hadoop-2.4.1/tmp/dfs/data/current/BP-193442119-192.168.2.120-1432457733
977/current/finalized
2019/2/18 星期一
hdfs 寫數據流程(put)
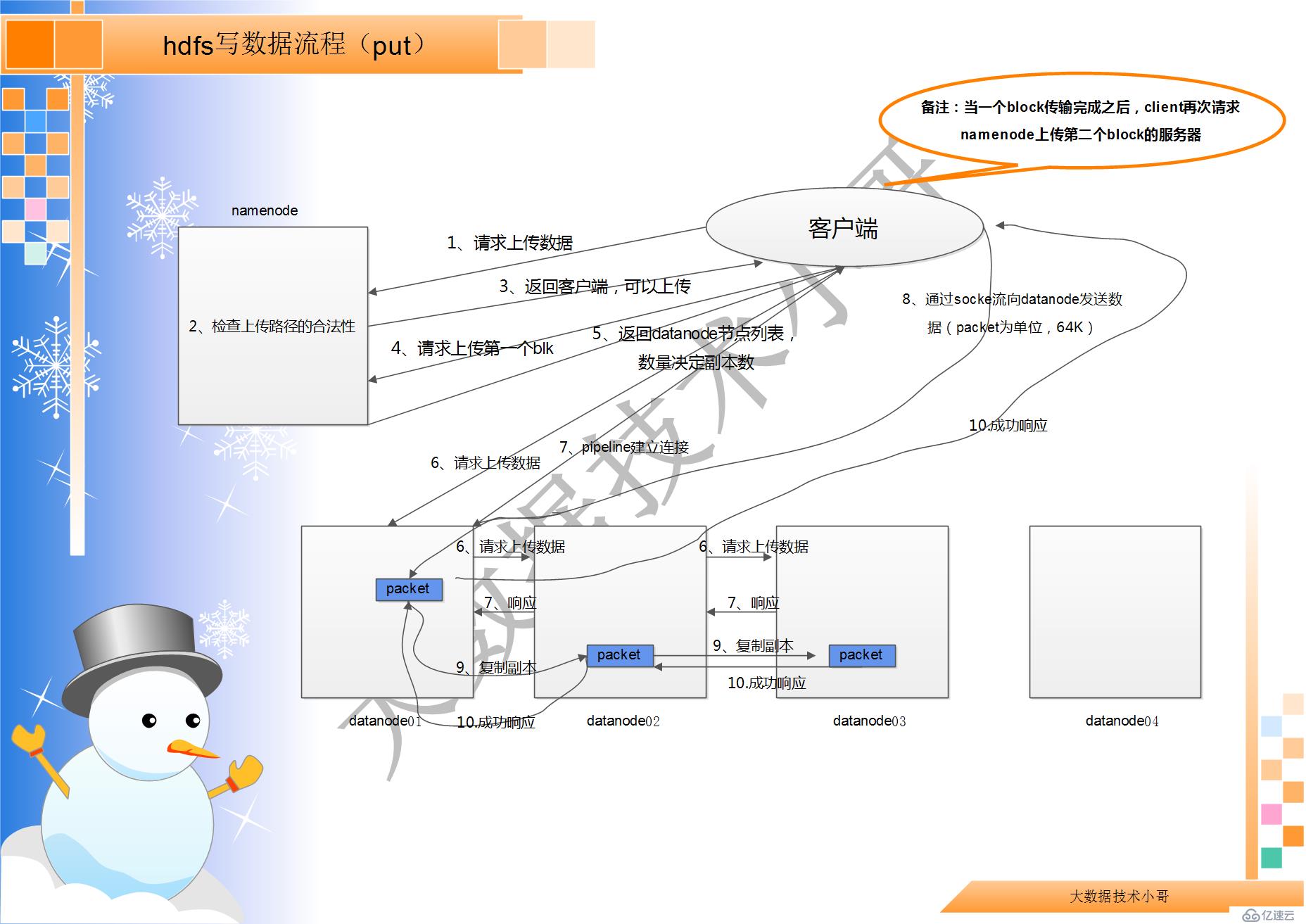
1、根namenode 通信請求上傳文件,namenode 檢查目標文件是否已存在,父目錄是否存在
2、namenode 返回是否可以上傳
3、client 請求第一個block 該傳輸到哪些datanode 服務器上
4、namenode 返回3 個datanode 服務器ABC
5、client 請求3 臺dn 中的一臺A 上傳數據(本質上是一個RPC 調用,建立pipeline),A收到請求會繼續調用B,然后B 調用C,將真個pipeline 建立完成,逐級返回客戶端
6、client 開始往A 上傳第一個block(先從磁盤讀取數據放到一個本地內存緩存),以packet為單位,A 收到一個packet 就會傳給B,B 傳給C;A 每傳一個packet 會放入一個應答隊列等待應答
7、當一個block 傳輸完成之后,client 再次請求namenode 上傳第二個block 的服務器。
hdfs 讀數據流程(get)
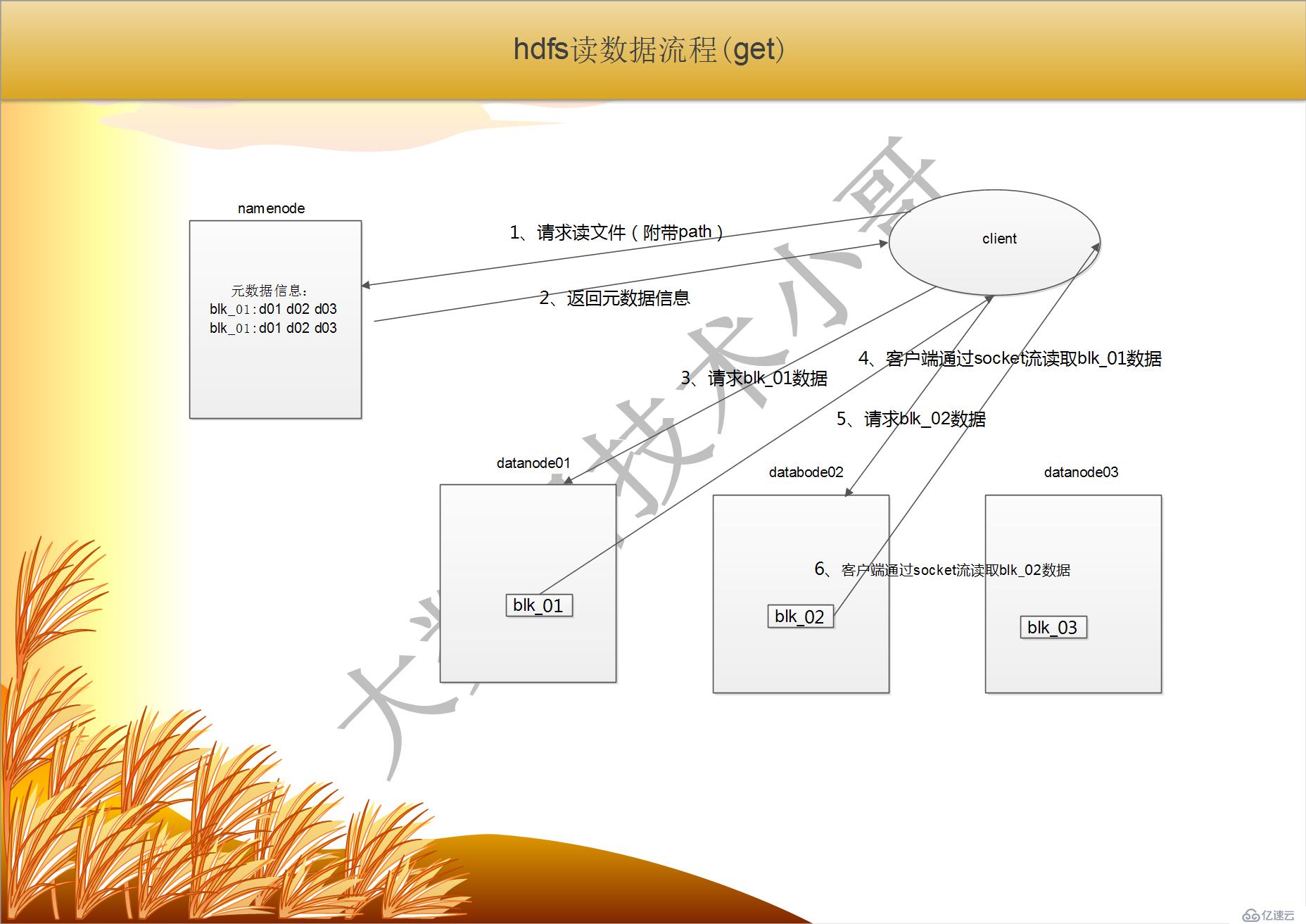
1、跟namenode 通信查詢元數據,找到文件塊所在的datanode 服務器
2、挑選一臺datanode(就近原則,然后隨機)服務器,請求建立socket 流
3、datanode 開始發送數據(從磁盤里面讀取數據放入流,以packet 為單位來做校驗)
4、客戶端以packet 為單位接收,現在本地緩存,然后寫入目標文件
小結:
在這里我們描述的是hdfs的讀寫數據的流程是比較順利的一種情況,這上面的每一個階段都有可能出現異常,那hdfs對于每個異常也是很完善的,容錯性非常的高,這些異常處理的邏輯比較復雜,我們暫時不做深入的描述,搞懂正常的讀寫流程就ok了。
Hdfs中namenode管理元數據的機制 //元數據的 CheckPoint
如圖:
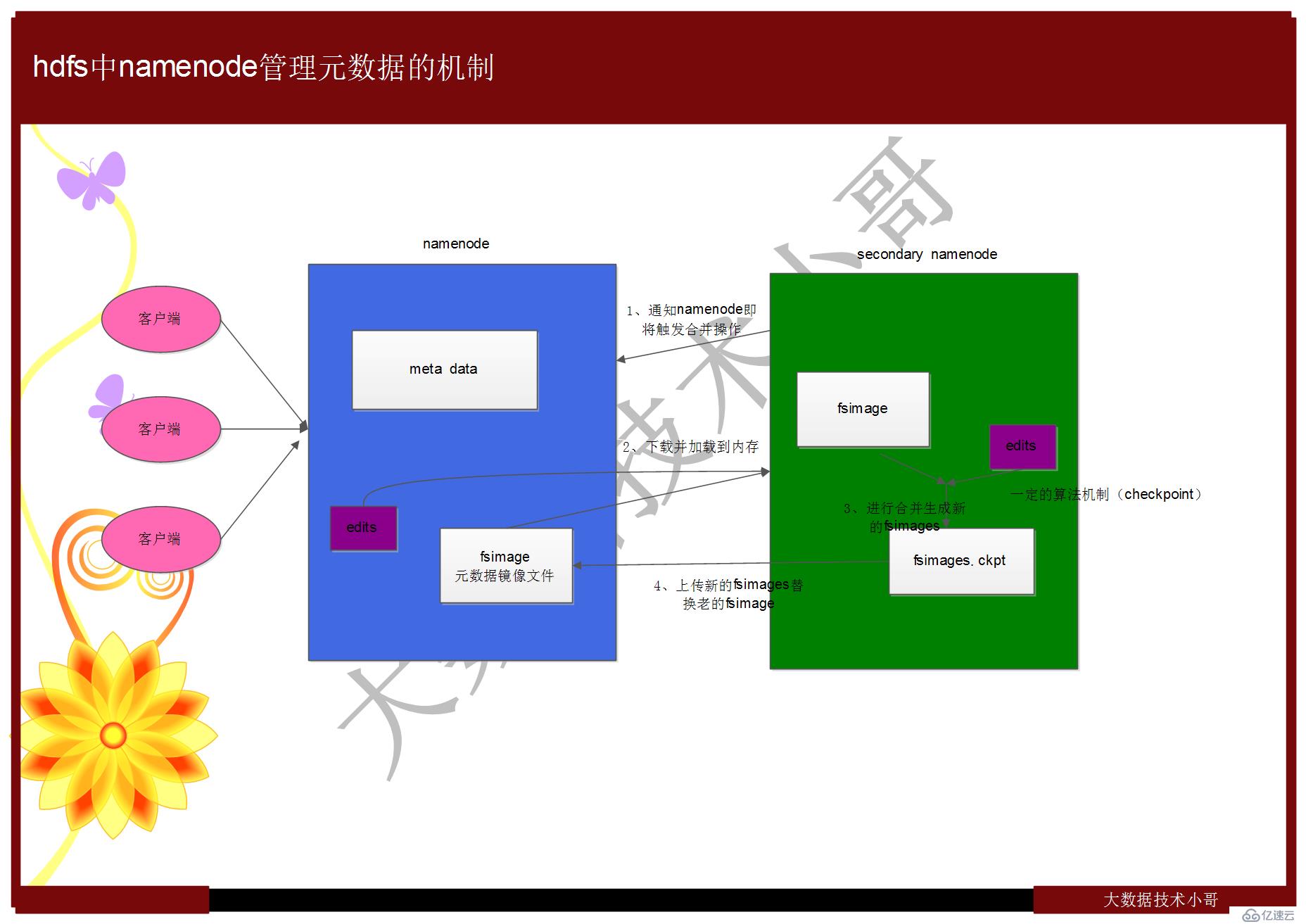
hdfs 元數據是怎么存儲的?
A、內存中有一份完整的元數據(特定數據結構)
B、磁盤有一個“準完整”的元數據的鏡像文件
C、當客戶端對hdfs 中的文件進行新增或者修改操作,首先會在edits 文件中記錄操作日志,當客戶端操作成功后,相應的元數據會更新到內存中;每隔一段時間,會由secondary namenode 將namenode 上積累的所有edits 和一個最新的fsimage 下載到本地,并加載到內存進行merge(這個過程稱為checkpoint)
D、checkpoint 操作的觸發條件配置參數:
dfs.namenode.checkpoint.check.period=60 #檢查觸發條件是否滿足的頻率,60 秒
dfs.namenode.checkpoint.dir=file://${hadoop.tmp.dir}/dfs/namesecondary
#以上兩個參數做checkpoint 操作時,secondary namenode 的本地工作目錄
dfs.namenode.checkpoint.edits.dir=${dfs.namenode.checkpoint.dir}
dfs.namenode.checkpoint.max-retries=3 #最大重試次數
dfs.namenode.checkpoint.period=3600 #兩次checkpoint 之間的時間間隔3600 秒
dfs.namenode.checkpoint.txns=1000000 #兩次checkpoint 之間最大的操作記錄
E、namenode 和secondary namenode 的工作目錄存儲結構完全相同,所以,當namenode故障退出需要重新恢復時,可以從secondary namenode 的工作目錄中將fsimage 拷貝到namenode 的工作目錄,以恢復namenode 的元數據
F、可以通過hdfs 的一個工具來查看edits 中的信息
bin/hdfs oev -i edits -o edits.xml
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





