溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
主子表是數據庫最常見的關聯關系之一,最典型的包括合同和合同條款、訂單和訂單明細、保險保單和保單明細、銀行賬戶和賬戶流水、電商用戶和訂單、電信賬戶和計費清單或流量詳單。當主子表的數據量較大時,關聯計算的性能將急劇降低,在增加服務器負載的同時嚴重影響用戶體驗。作為面向過程的結構化數據計算語言,集算器 SPL 可通過有序歸并的方法,顯著提升大主子表關聯計算的性能。
所謂主子表關聯計算,就是針對主表的每條記錄,按關聯字段找到子表中對應的一批記錄。以訂單(主表)和訂單明細(子表)為例,兩者以訂單ID為關聯字段。下圖顯示了關聯計算過程中對主表中一條記錄的處理情況,紅色箭頭代表沒找到對應記錄(不可關聯),綠色箭頭代表找到了對應記錄(可關聯):
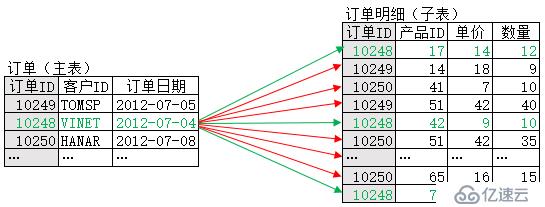
假設訂單(主表)有m條記錄,訂單明細(子表)有n條記錄,在不考慮優化算法時,主表中每一條記錄的關聯都需要遍歷子表,相應的時間復雜度為O(n)。而主表一共有m條記錄,所以整個計算的復雜度就是O(m*n),顯然過高。雖然數據庫一般會采用hash方案來優化,但在數據量較大或較多表關聯時,仍然會面臨時難以并行、使用外存緩存數據的問題,性能依舊會急劇下降。
而對于集算器來說,針對大主子表關聯算法,可以通過兩步來實現顯著優化:數據有序化、歸并關聯。
l 數據有序化
對主表和子表,首先分別按照關聯字段排序,形成有序數據。
l 歸并關聯
首先在主表和子表上分別用指針指向第一條記錄,然后開始比對,對于主表的第一條記錄,如果子表遇到匹配的記錄,則表示可以關聯,記錄后子表指針前移;如果遇到不匹配的記錄,表示主表第一條記錄的關聯計算完成,此時子表指針不動,主表指針下移一位,指向第二條記錄。以此類推……
優化后,單條記錄的關聯計算可用下圖示意:
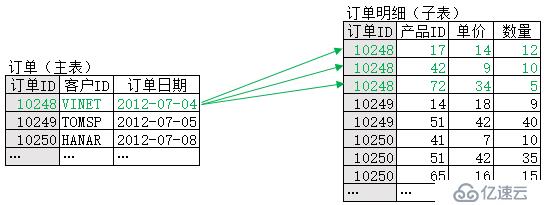
可以看到,經過優化,主表中單條記錄的關聯只需比對部分數據,不再需要遍歷子表。事實上,對主表所有記錄的關聯,才會遍歷一次子表,也就是復雜度為O(n)。再加上主表本身會遍歷一次,因此整個計算的復雜度就是O(m+n)。
這樣,經過集算器優化后,算法的時間復雜度變為線性,而且不再需要生成落地的中間數據,性能自然得到大幅提升。
當然,需要注意的是,有序化本身也會耗費時間,因此這種優化方法不適合只做一次的關聯算法。但在實際業務中,關聯算法通常會反復執行,這時有序化的開銷就是一次性的,完全可以忽略不計。
下面還是以訂單和訂單明細為例,說明集算器優化大主子表關聯的方法。
首先進行數據有序化(注意,這是一次性動作)。集算器腳本“數據有序化.dfx”如下:
A | B | |
1 | =connect("orcl") | |
2 | =A1.cursor("select 訂單ID,客戶ID,訂購日期 from 訂單 order by 訂單ID") | =A1.cursor("select 訂單ID, 產品ID,單價,數量 from 訂單明細 order by 訂單ID,產品ID") |
3 | =file("訂單.ctx").create(#訂單ID,客戶ID,訂購日期) | =file("訂單明細.ctx").create(#訂單ID,#產品ID,單價,數量 ) |
4 | =A3.append(A2) | =B3.append(B2) |
5 | =A1.close() |
A1連接Oracle數據源,A5關閉數據源。集算器可連接大部分常用數據源,包括數據庫、Excel、阿里云、SAP等等。
A2、B2:用SQL語句分別取訂單和訂單明細,并按關聯字段排序。由于數據量較大,無法一次性讀入內存,因此這里用到了游標函數cursor。
A3、B3:分別創建組表文件“訂單.ctx”和“訂單明細.ctx”,用于存儲有序化之后的數據。這里需要指定字段名,其中帶#號的字段是主鍵,。數據將按主鍵排序,且主鍵的值不可重復。
A4-B4:將游標追加寫入組表文件。
其次,對于通常會反復執行的關聯算法,可以用集算器腳本“歸并關聯.dfx”實現如下:
A | B | |
1 | =file("訂單.ctx").create().cursor(訂單ID) | =file("訂單明細.ctx").create().cursor(訂單ID,數量) |
2 | =joinx(A1:主表,訂單ID; B1:子表,訂單ID) | |
3 | =A2.groups(;sum(子表.數量)) |
A1、B1:讀入組表文件“訂單.ctx”和“訂單明細.ctx”。注意組表默認為列式存儲,因此只需讀入后續計算需要的字段,從而大幅降低I/O。
A2:對有序游標A1、B1進行歸并關聯,其中“主表”、“子表”是別名,方便后續引用,如果省略別名,后續可以通過默認別名_1、_2引用。注意,函數joinx默認進行內關聯,可用選項@1指定左關聯,或者@f指定全關聯。如果有多個游標都要與A1關聯,可用分號依次隔開。
A3:對關聯結果進行后續計算,例如匯總產品數量。事實上后續計算可以支持任意算法,也不是本文的討論范圍了。
上面介紹了集算器SPL腳本的寫法,而在實際執行時,還需要部署集算器的運行環境。有兩種部署方式可供選擇:內嵌部署和獨立部署。
l 內嵌部署
內嵌部署時,集算器的用法類似內嵌數據庫,應用系統使用集算器驅動(JDBC)執行同一個JVM下的集算器腳本。
下面是Java調用“歸并關聯.dfx”的代碼
1. com.esproc.jdbc.InternalConnection con=null; 2. try { 3. Class.forName("com.esproc.jdbc.InternalDriver"); 4. con =(com.esproc.jdbc.InternalConnection)DriverManager.getConnection("jdbc:esproc:local://"); 5. ResultSet rs = con.executeQuery("call 歸并關聯()"); 6. } catch (SQLException e){ 7. out.println(e); 8. }finally{ 9. if (con!=null) con.close(); 10. } |
在上述JAVA代碼中,集算器腳本以文件的形式保存,調用語法類似存儲過程。而如果腳本很簡單,也可以不保存腳本文件,直接書寫表達式,調用語法類似SQL,這時第5行可以寫成:
ResultSet rs = con.executeQuery("=joinx(file(\"訂單.ctx\").create().cursor(訂單ID),訂單ID; file(\"訂單明細.ctx\").create().cursor(訂單ID,數量),訂單ID).groups(;sum(_2.數量))"); |
這篇文章詳細介紹了JAVA調用集算器的過程:http://doc.raqsoft.com.cn/esproc/tutorial/bjavady.html
除了使用Java代碼,也可以通過報表訪問集算器,這時按照訪問一般數據庫的方法即可,具體可參考《讓Birt報表腳本數據源變得既簡單又強大》。
對于腳本“數據有序化.dfx”,可以用同樣的方法執行。不過這個腳本通常只執行一次,所以也可以直接在命令行中執行,windows用法如下:
D:\raqsoft64\esProc\bin>esprocx 數據有序化.dfx |
Linux下用法類似,可以參考http://doc.raqsoft.com.cn/esproc/tutorial/minglinghang.html
l 獨立部署
獨立部署時,集算器的用法類似遠程數據庫,應用系統可以使用集算器驅動(JDBC或ODBC驅動)訪問集算服務器。這種情況下,應用系統和集算器服務器通常部署在不同的機器上。
例如集算服務器的IP地址為192.168.0.2,端口號為8281,那么JAVA應用系統可以通過如下代碼訪問:
st = con.createStatement(); st.executeQuery("=callx(\"歸并關聯.dfx\";[\"192.168.0.2:8281\"])"); |
關于集算服務器的部署和使用,詳細內容可參考http://doc.raqsoft.com.cn/esproc/tutorial/fuwuqi.html
關于JDBC和ODBC驅動的部署方法,可分別參考
http://doc.raqsoft.com.cn/esproc/tutorial/jdbcbushu.html
http://doc.raqsoft.com.cn/esproc/tutorial/odbcbushu.html
前面介紹了基本的優化思路和實現方法,也就是針對數據本身的優化。而現實中服務器都是多核心CPU,因此可以進一步對上述算法進行多線程優化。
多線程優化的原理,是將主表和子表各分為N段,使用N個線程同時進行關聯計算。
原理雖簡單,但真正實現的時候,就會發現很多難題:
l 分段效率
想把數據分為N段,就要先找到每一段的起始行號,如果用遍歷的笨辦法數行號,顯然會白白消耗大量的I/O資源。
l 數據跨段
理論上,關聯字段值相同的子表記錄,應該分到同一段。如果對子表隨意分段,很可能形成跨段的數據。
l 分段對齊
更進一步,理論上,子表的第i段數據,應該與主表的第i段數據對齊,也就是主子表關聯字段值的范圍應該一致。如果兩者各自獨立分段,則可能導致分段數據難以對齊。
l 二次計算
如果后續計算不涉及聚合,例如只是過濾,那么只需將N個線程的計算結果直接合并。但如果后續計算涉及聚合,比如sum或分組匯總,那就要單獨再進行二次計算聚合。
好在集算器已經充分解決了上述難題,分段時不會耗費IO資源、關聯字段值相同的記錄會分在同一段、子表和主表會保持對齊、各種二次計算無需單獨實現。
具體來說,首先,數據有序化腳本需要做如下修改(紅色字體為修改部分):
A | B | |
1 | =connect("orcl") | |
2 | =A1.cursor("select 訂單ID,客戶ID,訂購日期 from 訂單 order by 訂單ID") | =A1.cursor("select 訂單ID, 產品ID,單價,數量 from 訂單明細 order by 訂單ID,產品ID") |
3 | =file("訂單多線程.ctx").create(#訂單ID,客戶ID,訂購日期) | =file("訂單明細多線程.ctx").create(#訂單ID,#產品ID,單價,數量 ;#訂單ID ) |
4 | =A3.append(A2) | =B3.append(B2) |
5 | =A1.close() |
B3:生成“訂單明細多線程.ctx”時,數據按“#訂單ID”分段。這將保證訂單ID相同的記錄,將來會分到同一段。
歸并關聯的腳本需修改如下:
A | B | |
1 | =file("訂單多線程.ctx").create().cursor@m(訂單ID) | =file("訂單明細多線程.ctx").create().cursor@m(訂單ID,數量;;A1) |
2 | =joinx(A1:主表,訂單ID; B1:子表,訂單ID) | |
3 | =A2.groups(;sum(子表.數量)) |
A1:@m表示對數據分段,形成多線程游標(也叫多路并行游標)。其中線程數量是默認值,由系統參數“最大并行數”決定,也可手工修改。例如希望生成4線程游標,A1應寫成:
=file("訂單多線程.ctx").create().cursor@m(訂單ID ;;4) |
B1:同樣生成多線程游標,并與A1的多線程游標對齊。
A2-A3:歸并關聯,再執行后續算法。這兩步寫法上沒變化,但底層會自動進行多線程合并和二次計算,從而降低了程序員的編程難度。
在前面算法的基礎上,還可以進一步提升計算性能,那就是以層次結構存儲數據,直接記錄關聯關系。
具體來說,先用“結構優化有序化.dfx”生成組表文件:
A | B | |
1 | =connect("orcl") | |
2 | =A1.cursor("select 訂單ID,客戶ID,訂購日期 from 訂單 order by 訂單ID") | =A1.cursor("select 訂單ID, 產品ID,單價,數量 from 訂單明細 order by 訂單ID,產品ID") |
3 | =file("多層訂單.ctx").create(#訂單ID,客戶ID,訂購日期) | |
4 | =A3.append(A2) | =A3.attach(訂單明細,#產品ID,單價,數量) |
5 | =B4.append(B2) | |
6 | =A1.close() |
B4:在主表的基礎上附加子表,命名為訂單明細。與主表不同的是,子表默認繼承了主表的主鍵,因此可以省略訂單ID,只需要寫另一個主鍵產品ID。這樣,2個表寫在了一個組表文件中,從而才能形成層次結構。
B5:向子表寫入數據。
此時,組表“多層訂單.ctx”將按層次結構存儲,邏輯示意圖如下:
#訂單 ID | #產品 ID | 單價 | 數量 | 客戶 ID | 訂單日期 |
10248 | VINET | 2012-07-04 | |||
17 | 14 | 12 | |||
42 | 9 | 10 | |||
72 | 34 | 5 | |||
10249 | TOMSP | 2012-07-05 | |||
14 | 18 | 9 | |||
51 | 42 | 40 | |||
10250 | HANAR | 2012-07-08 | |||
41 | 7 | 10 | |||
51 | 42 | 35 | |||
65 | 16 | 15 | |||
… | … | … | |||
… | … | … |
可以看到,每條主表記錄與對應的子表記錄,在邏輯上已經緊密相關,無需額外關聯,這樣便可大幅提高關聯算法的性能。
進行關聯計算時,使用以下腳本“結構優化歸并關聯.dfx”:
A | B | |
1 | =file("多層訂單.ctx").create() | =A1.attach(訂單明細) |
2 | =A1.cursor@m(訂單ID) | =B1.cursor@m(訂單ID,產品ID) |
3 | =joinx(A2:主表,訂單ID; B2:子表,訂單ID) | |
4 | =A3.groups(;sum(子表.數量)) |
A1、B1:打開主表,以及附加在主表上的子表。
A2、B2:以多線程方式分別讀取主表和子表。需要注意的是,多層組表里的實表之間天然具備相關性,因此無需特意指定子表和主表的分段關系,代碼比之前更清晰簡單。
A3,A4:歸并關聯并執行后續算法,這兩步沒變化。
前面的優化方式都基于庫表全量導出為組表文件的情況,但實際業務中數據庫表總會發生變化,因此需要考慮數據更新的問題,也就是要將變化的數據定時更新到組表文件中。
顯然,更新數據應選擇在無人查詢組表文件時進行,一般都是半夜或凌晨。而更新的頻率,則需要按照數據實時性要求來設定,例如每天一次或每周一次。至于更新的方式,需要按照數據的變化規律來考慮,最常見的是數據追加,有時也會遇到增刪改。
下面先看數據追加:
訂單和訂單明細每天都會產生新記錄,假設需要在每天凌晨2點將昨天新增的記錄追加到組表文件中。下圖顯示了2018/11/23新增記錄的情況,注意,有些訂單(訂單ID:20001)并沒有對應的訂單明細:
訂單表 | 訂單明細表 |
| 訂單 ID 客戶 ID 訂單日期 19999APK2018/11/2220000APK2018/11/2320001APJ2018/11/2320002APL2018/11/2320003APP2018/11/24 | 訂單 ID 產品 ID 單價數量 199991757.1151999916204.516200001364.282000014640.22200021615.242000319245.25 |
把主子表追加到組表文件中的腳本 “追加組文件.dfx”如下:
A | B | |
2 | =begin=datetime(elapse(date(now()),-1)) | =end=elapse(begin,1) |
3 | =connect("orcl") | |
4 | =A3.query@x("select 訂單.訂單ID 主訂單ID,訂單明細.訂單ID 子訂單ID,產品ID,單價,數量,客戶ID,訂購日期 from 訂單 left join 訂單明細 on 訂單.訂單ID=訂單明細.訂單ID where 訂購日期>? and 訂購日期<=? order by 訂單ID,產品ID",begin,end) | |
5 | =A4.groups(主訂單ID:訂單ID,客戶ID,訂購日期) | =A4.select(子訂單ID).new(子訂單ID:訂單ID,產品ID,單價,數量) |
6 | =file("多層訂單.ctx").create() | |
7 | =A6.append(A5.cursor()) | =A6.attach(訂單明細) |
8 | =B7.append(B5.cursor()) |
A2、B2:計算昨天的起止時間,以便查詢新增數據。函數now獲取當前時間點,理論上應該是2018-11-24 02:00:00。A2是昨天的起始時間點,即2018-11-22 00:00:00。B2是終止時間點,即2018-11-23 00:00:00。之所以在集算器中計算起止時間,主要是為了增加可讀性和移植性。實際上也可以在SQL中計算。
A4:取出新增的主表和子表記錄。這里用一句SQL取兩張表的數據,主要是為了提高效率。由于有些訂單并沒有對應的訂單明細,因此用訂單左關聯訂單明細,且將對應不上的訂單明細置空。計算結果如下:
主訂單 ID | 子訂單 ID | 產品 ID | 單價 | 數量 | 客戶 ID | 訂購日期 |
20000 | 20000 | 13 | 64.2 | 8 | APK | 2018/11/23 |
20000 | 20000 | 14 | 640.2 | 2 | APK | 2018/11/23 |
20001 | APJ | 2018/11/23 | ||||
20002 | 20002 | 16 | 15.2 | 4 | APL | 2018/11/23 |
A5、B5:拆出新增的主子表記錄,結果示例如下:
| 訂單 ID 客戶 ID 訂單日期 20000APK2018/11/2320001APJ2018/11/2320002APL2018/11/23 | 訂單 ID 產品 ID 單價數量 200001364.282000014640.22200021615.24 |
A6-B8:將主表和子表追加到組表文件中。
腳本寫完之后,還需要在每天的02:00:00定時執行,這可以使用操作系統內置的任務調度。
在Windows下,建立如下的bat批處理文件,:
"D:\raqsoft64\esProc\bin\esprocx.exe" 追加組文件.dfx |
再使用windows內置的"計劃任務",定時執行批處理文件即可。
在linux下,建立如下的sh批處理文件,:
/raqsoft/esProc/bin/esprocx.sh synclastday.dfx |
再使用crontab命令,定時執行批處理文件即可。
當然也可使用圖形化工具定時執行腳本,比如Quartz。
需要注意的是,大多數情況下,能夠選擇無人使用組表文件的時候進行追加,但有些業務中組表文件全天都要使用,而有些項目對容錯要求更高,要求追加失敗時再次追加,這類項目就需要更加細致的追加方法,詳情可參考《基于文件系統實現可追加的數據集市》。
除了追加這種主要的更新方式,業務中也會遇到增刪改都存在的情況。
在這種情況下,就需要知道哪些是刪除的記錄,哪些是修改或新增的記錄。如果條件允許,可以在原表中新加“標記”字段,并將維護狀態記錄在該字段中。如果不方便修改原表,則應當創建對應的“維護日志表”。例如下面兩張表,分別是訂單和訂單明細的維護日志。
訂單維護表 | 訂單明細維護表 |
| 訂單 ID 客戶 ID 訂購日期標記 11108OKBJ12012/11/23 刪除 11107VINET2018/11/26 修改 30000TOMSP2018/11/26 新增 | 訂單 ID 產品 ID 單價數量標記 1110817100.110 刪除 1110819100.110 刪除 1110717200.120 修改 1110718300.130 新增 3000020400.140 新增 3000021500.150 新增 |
根據維護日志更新組表文件,可使用下面的腳本:
A | B | |
1 | =connect("orcl") | |
2 | =訂單刪除=A1.query("select * from 訂單維護where 標記= '刪除' ") | =明細刪除= A1.query("select * from 訂單明細維護where標記= '刪除' ") |
3 | =訂單修改新增= A1.query("select * from 訂單維護where 標記= '修改' or標記= '新增' ") | =明細新增修改= A1.query("select * from 訂單明細維護where標記= '修改' or標記= '新增' ") |
4 | =file("多層訂單.ctx").create() | =A4.attach(訂單明細) |
5 | =A4.delete(訂單刪除) | =B4.delete(訂單刪除) |
6 | =A4.update(訂單修改新增) | =B4.update(訂單修改新增) |
7 | =A1.execute("delete * from 訂單維護") | =A1.execute("delete * from 訂單明細維護") |
8 | =A1.close() |
A2、B2:從數據庫查出應刪除的記錄
A3、B3:從數據查出應修改和新增的記錄
A5、B5:對組表進行刪除操作。
A6、B6:從組表進行修改新增操作。
A7、B7:清空維護日志表,以便下次繼續更新數據。
通過定時追加,能保證組表文件與昨天的數據同步,從而實現T+1計算,但有時需要進行實時大主表關聯,即T+0計算。
對于T+0計算,需要將兩種不同的數據源進行混合計算,由于SQL或SP的數據模型較為封閉,因此難以實現混合計算,而使用集算器就非常簡單。
比如對組表文件定時追加后,數據庫當天又產生了如下新數據:
訂單 | 訂單明細 |
| 訂單 ID 客戶 ID 訂購日期………20002APL2018/11/2340000VINET2018/11/2640001TOMSP2018/11/2640002HANAR2018/11/26 | 訂單 ID 產品 ID 單價數量…………200021615.2440000115005400001260064000213700.274000214800.28 |
可使用如下腳本實現T+0實時計算:
A | B | |
1 | =begin=datetime(date(now())) | |
2 | =connect("orcl") | |
3 | =A2.query@x("select sum(數量) as 總數 from 訂單,訂單明細 where 訂單.訂單ID=訂單明細.訂單ID and 訂購日期>=?",begin) | |
4 | =file("多層訂單.ctx").create() | =A4.attach(訂單明細) |
5 | =A4.cursor@m(訂單ID) | =B4.cursor@m(訂單ID,數量) |
6 | =joinx(A5:主表,訂單ID; B5:子表,訂單ID) | |
7 | =A6.groups(;sum(子表.數量):總數) | |
8 | =(A3|A7).groups(;sum(總數):總數) |
A1:算出當天的起始時間點,即2018-11-26 00:00:00。
A3:針對數據庫當天產生的新數據,進行關聯計算。由于當天數據量較小,因此性能可以接受。
A4-A7:針對組表文件歷史數據,進行高性能關聯計算。
A8:合并當天和歷史,并進行二次計算,以獲得最終計算結果。其中符號|表示縱向合并,這是實現混合計算的關鍵。事實上,這種寫法也表明集算器支持任意數據源之間的混合計算,比如Excel與elasticSearch之間。
關于T+0計算更多的細節,可參考相關文章《實時報表 T+0 的實現方案》
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





