溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
hbase讀寫請求
詳細解釋hbase的讀寫過程
讀請求過程
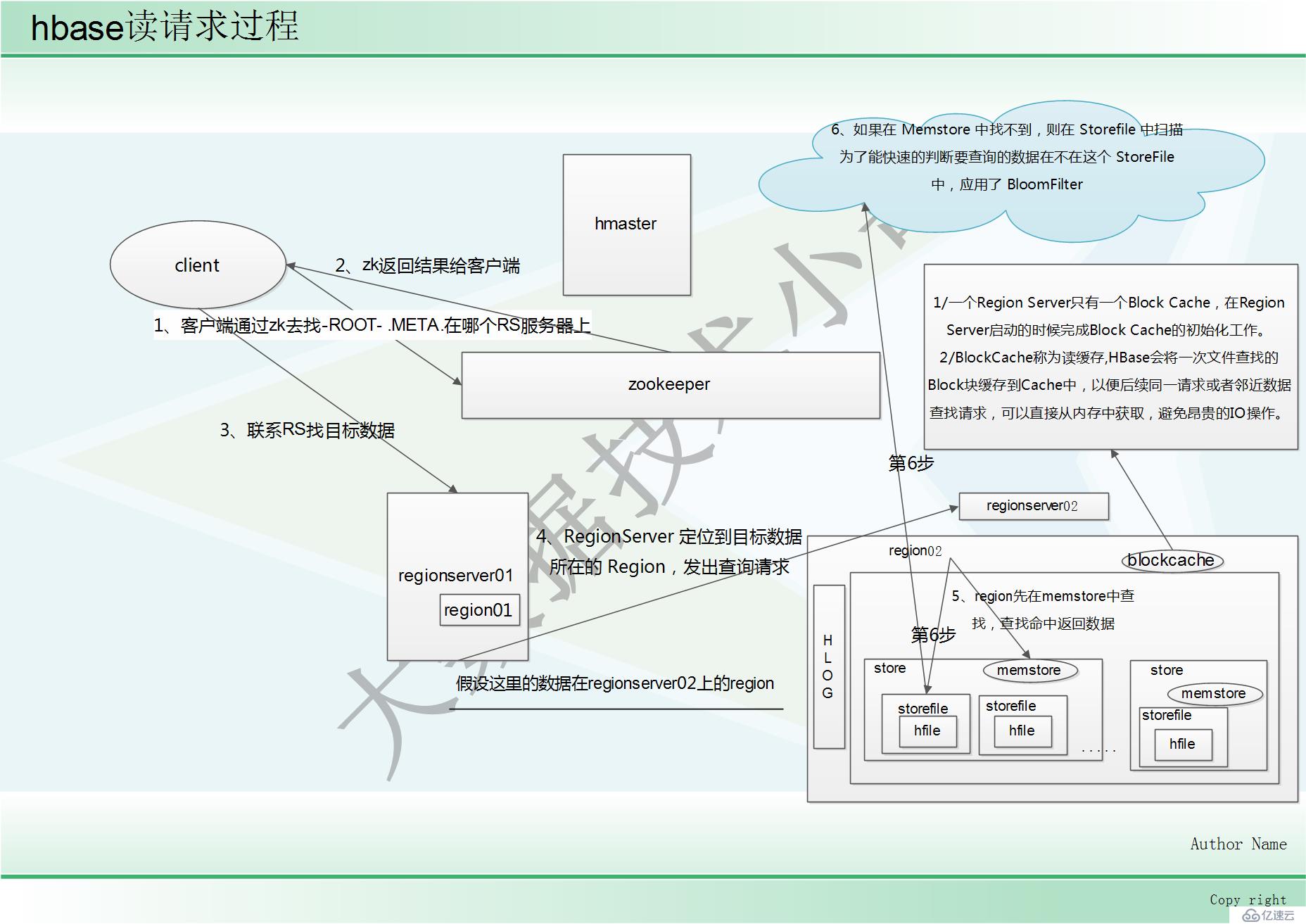
1、客戶端通過 ZooKeeper 以及-ROOT-表和.META.表找到目標數據所在的 RegionServer(就是 數據所在的 Region 的主機地址)
2、zk返回結果給客戶端
3、聯系 RegionServer 查詢目標數據
4、RegionServer 定位到目標數據所在的 Region,發出查詢請求
5、Region 先在 Memstore 中查找,命中則返回
6、如果在 Memstore 中找不到,則在 Storefile 中掃描 為了能快速的判斷要查詢的數據在不在這個 StoreFile 中,應用了 BloomFilter
(BloomFilter,布隆過濾器:迅速判斷一個元素是不是在一個龐大的集合內,但是他有一個 弱點:它有一定的誤判率)
(誤判率:原本不存在與該集合的元素,布隆過濾器有可能會判斷說它存在,但是,如果 布隆過濾器,判斷說某一個元素不存在該集合,那么該元素就一定不在該集合內)
BlockCache
1、BlockCache稱為讀緩存
2、HBase會將一次文件查找的Block塊緩存到Cache中,以便后續同一請求或者鄰近數據查找請求,可以直接從內存中獲取,避免昂貴的IO操作。
此部分參考鏈接:https://blog.51cto.com/12445535/2363376
hbase寫請求
//深度了解hbase的寫請求,請閱讀:hbase數據寫入流程深度解析 https://blog.51cto.com/12445535/2370653
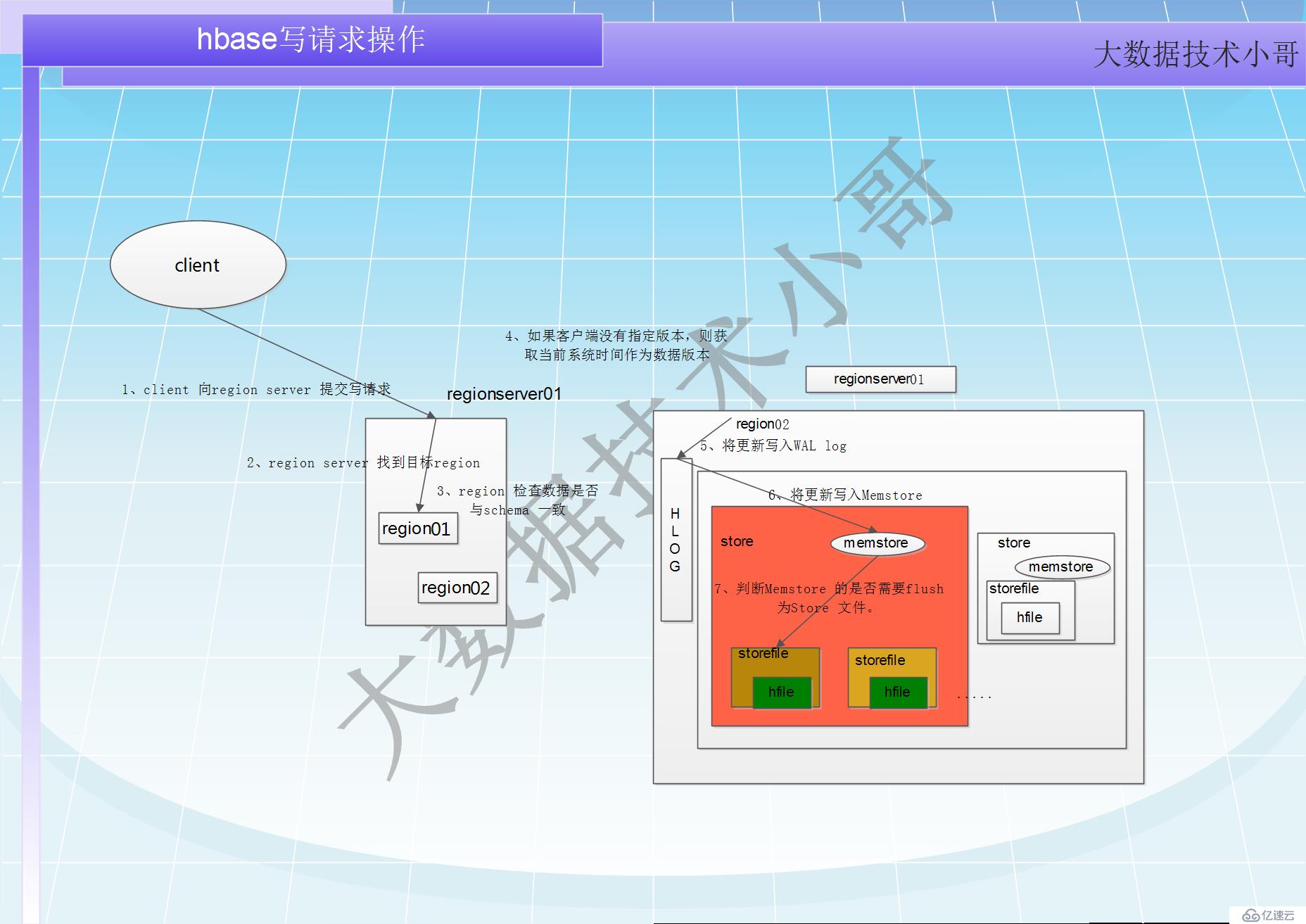
寫請求處理過程小結
1 client 向region server 提交寫請求
2 region server 找到目標region
3 region 檢查數據是否與schema 一致
4 如果客戶端沒有指定版本,則獲取當前系統時間作為數據版本
5 將更新寫入WAL log
6 將更新寫入Memstore
7 判斷Memstore 的是否需要flush 為Store 文件。
Hbase 在做數據插入操作時,首先要找到 RowKey 所對應的的 Region,怎么找到的?其實這 個簡單,因為.META.表存儲了每張表每個 Region 的起始 RowKey 了。
建議:在做海量數據的插入操作,避免出現遞增 rowkey 的 put 操作
如果 put 操作的所有 RowKey 都是遞增的,那么試想,當插入一部分數據的時候剛好進行分 裂,那么之后的所有數據都開始往分裂后的第二個 Region 插入,就造成了數據熱點現象。
寫請求過程 //細節描述
上面提到,hbase 使用MemStore 和StoreFile 存儲對表的更新。
1、數據在更新(寫)時首先寫入Log(WAL log)和內存(MemStore)中,MemStore 中的數據是排序的,當MemStore 累計到一定閾值時,就會創建一個新的MemStore,并且將老的MemStore 添加到flush 隊列,由單獨的線程flush 到磁盤上,成為一個StoreFile。
2、于此同時,系統會在zookeeper 中記錄一個redo point,表示這個時刻之前的變更已經持久化了。(minor compact)
3、當系統出現意外時,可能導致內存(MemStore)中的數據丟失,此時使用Log(WAL log)來恢復checkpoint 之后的數據。
4、前面提到過StoreFile 是只讀的,一旦創建后就不可以再修改。因此Hbase 的更新其實是不斷追加的操作。
5、當一個Store 中的StoreFile 達到一定的閾值后,就會進行一次合并(major compact),將對同一個key 的修改合并到一起,形成一個大的StoreFile,當StoreFile 的大小達到一定閾值后,又會對StoreFile 進行split,等分為兩個StoreFile。
6、由于對表的更新是不斷追加的,處理讀請求時,需要訪問Store 中全部的StoreFile 和MemStore,將他們的按照row key 進行合并,由于StoreFile 和MemStore 都是經過排序的,并且StoreFile 帶有內存中索引,合并的過程還是比較快。
提示:
Client 寫入 -> 存入 MemStore,一直到 MemStore 滿 -> Flush 成一個 StoreFile,直至增長到 一定閾值 -> 觸發 Compact 合并操作 -> 多個 StoreFile 合并成一個 StoreFile,同時進行版本 合并和數據刪除 -> 當 StoreFiles Compact 后,逐步形成越來越大的 StoreFile -> 單個 StoreFile 大小超過一定閾值后,觸發 Split 操作,把當前 Region Split 成 2 個 Region,Region 會下線, 新 Split 出的 2 個孩子 Region 會被 HMaster 分配到相應的 HRegionServer 上,使得原先 1 個 Region 的壓力得以分流到 2 個 Region 上由此過程可知,HBase 只是增加數據,有所得更新 和刪除操作,都是在 Compact 階段做的,所以,用戶寫操作只需要進入到內存即可立即返 回,從而保證 I/O 高性能。
寫入數據的過程補充:
工作機制:每個 HRegionServer 中都會有一個 HLog 對象,HLog 是一個實現 Write Ahead Log 的類,每次用戶操作寫入 Memstore 的同時,也會寫一份數據到 HLog 文件,HLog 文件定期 會滾動出新,并刪除舊的文件(已持久化到 StoreFile 中的數據)。當 HRegionServer 意外終止 后,HMaster 會通過 ZooKeeper 感知,HMaster 首先處理遺留的 HLog 文件,將不同 Region 的 log數據拆分,分別放到相應 Region 目錄下,然后再將失效的 Region(帶有剛剛拆分的 log) 重新分配,領取到這些 Region 的 HRegionServer 在 load Region 的過程中,會發現有歷史 HLog 需要處理,因此會 Replay HLog 中的數據到 MemStore 中,然后 flush 到 StoreFiles,完成數據 恢復。
參考鏈接為:https://www.cnblogs.com/qingyunzong/p/8692430.html
http://hbasefly.com/2016/03/23/hbase_writer/
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





