溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Anthos Config Management 產品設計分析,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
大家可以看Arctiq公司搞的修改node數量Demo:https://www.arctiq.ca/our-blog/2019/4/9/gke-on-prem-and-anthos-config-management/
簡單說,當你修改某個git管理下的yaml配置文件,里面描述了某個GKE私有集群某個cluster的node數量,然后Anthos Config Management會幫你自動的發命令并讓節點數量變成你想要的那個
是google發布的混合云多云平臺
GKE:Anthos 的命令和控制核心。用戶通過 GKE 的控制平面來對分散在 Google 云、私有數據中心一級其它云平臺上的基礎設施進行管理。
GKE On-Prem:Google 推出了一個基于 Kubernetes 的和 GKE 一致的軟件平臺。用戶能夠在任何的兼容硬件上部署這一產品,而 Google 將會對其進行管理。從升級 Kubernetes 版本到應用最新補丁,Google 都視其為 GKE 的邏輯擴展。尤其需要注意的是 GKE On-Prem 運行在 VMWare vSphere 6.5 的虛擬化基礎上,Hyper-V 和 KVM 等其它虛擬化技術的支持還在開發之中。
Istio:這一技術讓跨平臺的聯邦網絡管理成為可能。Anthos 需要為部署在不同數據中心、GCP 以及其它云上的多種應用程序的組件建立服務網格,Istio 自然是首選。它會和 VMWare NSX、Cisco ACI 以及 Google 自己的 Andromeda 等 SDN 進行無縫集成。已經在網絡設施上(例如 F5) 進行投資的客戶,可以將 Istio 和負載均衡及防火墻集成起來。
Velostrata:Google 在 2018 年收購了這一云遷移技術,來增強 Kubernetes 的競爭力。Velostrata 的主要功能——在 GCE 實例中復制物理機/虛擬機,并把現有虛擬機轉換為 Kubernetes 應用(Pod)。這是業界首個物理機到 Kubernetes 的遷移工具,由 Google 提供。這一技術以 Anthos Migrate 的面目出現,目前是 Beta 階段。
Anthos 配置管理:Kubernetes 是一個可擴展的策略驅動的平臺。Anthos 的客戶必須面對運行在不同環境中的多個 Kubernetes,因此 Google 嘗試利用 Anthos 來簡化配置管理工作。從發布工件、配置項目、網絡策略、密文和密碼等類型的配置,Anthos 配置管理都能夠進行管理并將配置應用到一或多個集群之中。
Stackdriver:Stackdriver 為 Anthos 基礎設施和應用提供了可觀察性的支持。客戶能夠使用這一組件跟蹤運行在 Anthos集群狀態,以及部署在各個托管集群上的應用的健康情況。該組件負責集中地提供監控、日志、跟蹤以及觀察的支持。
GCP Cloud Interconnect:在企業數據中心以及云基礎設施之間的高速互聯,是混合云平臺的必要條件。Cloud Interconnect 能夠在數據中心和云間交付高達 100Gbps 的高速網絡。客戶也可以使用 Equinix、NTT Communications、Softbanck 等電信廠商的網絡將其數據中心延伸到 GCP
GCP Marketplace:Google 為能夠在 Kubernetes 上運行的(來自 ISV 和開源的)軟件列表。用戶能夠在 Anthos 中一鍵部署 Cassandra 數據庫或者 GitLab 等軟件。最終 Google 可能還會為內部 IT 提供一個私有的 Catalog 服務。
大家可以看到,在這8大組件里面,大概只有4和5是最近推出的,其他的早就投入生產并有不少企業在用了,這些組件到底是什么關系?我們把這些組件放到一張圖上,就排著這個樣子(原諒我忽略了可憐的StackDriver和Marktplace,我假定讀者對這2個東西很熟悉)
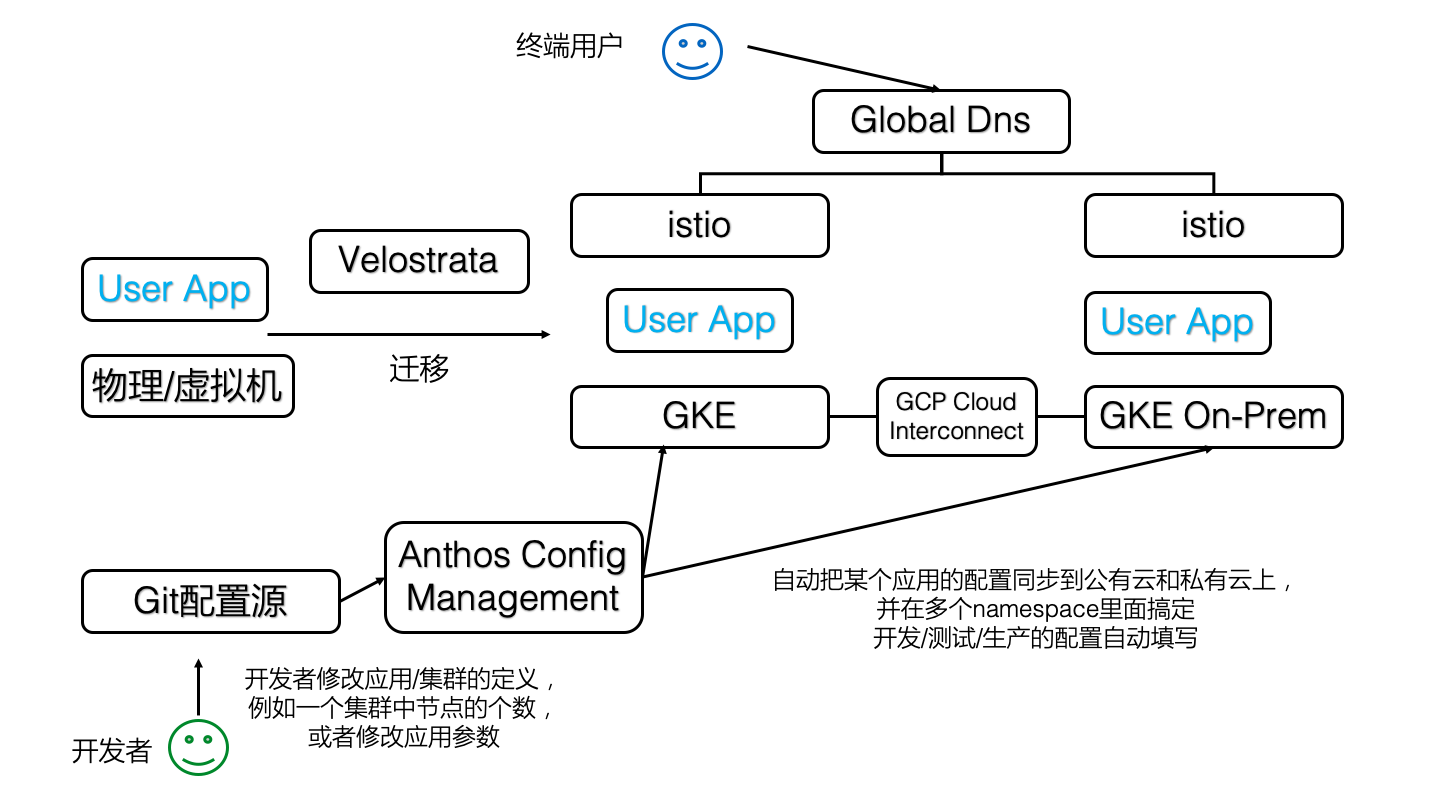
也就是說,Anthos Config Management是一瓶膠水,把混合云里面應用的配置工作給自動化了。
這個詞過于寬泛,所以在這里提幾個常見的k8s用戶場景
你是否碰到過,一個典型的Web應用,在測試環境有一份配置文件(我們假定這個配置文件是一個k8s的deployment的yaml),在準生產環境有一份配置文件,在公有云有一份配置文件,在私有云也有一份配置文件?每次你都復制黏貼并修改一些參數,并指望這些環境能夠混合起來給終端用戶提供合理的服務,但手工修改往往會造成差錯
你是否碰到過,配置文件存在多個k8s集群里面,每次都要手忙腳亂的用kubectl挨個修改,但沒法看到這些配置的歷史版本?你可以回滾應用的docker鏡像,但你沒法回滾配置。如果你是一個資深k8s玩家,你當然知道在etcd的某個角落里面存有所有yaml的歷史版本,通過某種黑魔法般的命令行操作你還是可以找回歷史的,但肯定沒有git那么爽快
是的,Anthos Config Management就是用來解決這些問題的,并且,是按照Infrasturce as code的理念來做這個事情的
眾所周知,在傳統的Unix/Linux環境下,在/etc下有不少配置文件,大部分苦逼的運維工程師每天的工作就是修改這些文件,并且通過重啟進程或者給進程發信號讓這些配置生效,并且要修改上百臺機器;過去幾年有了ansible或者salt這類批處理工具,把登陸幾百臺機器的工作量給省了;而k8s除了解決集群的批量問題,還引入了一個新的理念,就是聲明式配置,運維工程師不需要苦逼的重啟進程,這些“進程”會自動按照你的配置達到期望的狀態(當然,由于這是在一個集群內,所以需要一定的時間),也就是說
聲明式配置 = 面向終態
所以,你寫的配置和傳統的配置文件,那種靜態的文本配置已經完全不一樣了,最后這些配置會變成生產系統的某個狀態,并且,如果使用了合理的工具鏈,這一系列工作都是自動化的。
那么現在這些“配置文件”還是配置嗎?運維工程師的工作流程就變成了
git pull
read, think, modify
git push // all things done automaticlly
是的,你會發現運維工程師的工作流程就和開發工程師一樣了!
這些配置,無論是什么語言寫的,本質上變成了源代碼,只是沒有通過編譯工具鏈而是通過運維工具鏈達到了魯棒性,這樣就把傳統運維的重復勞動工作從大部分人手中拿出來交給少部分的運維工具鏈專家去維護。
關于這點,Google并沒有放出這個東西的源代碼,但是有一張圖
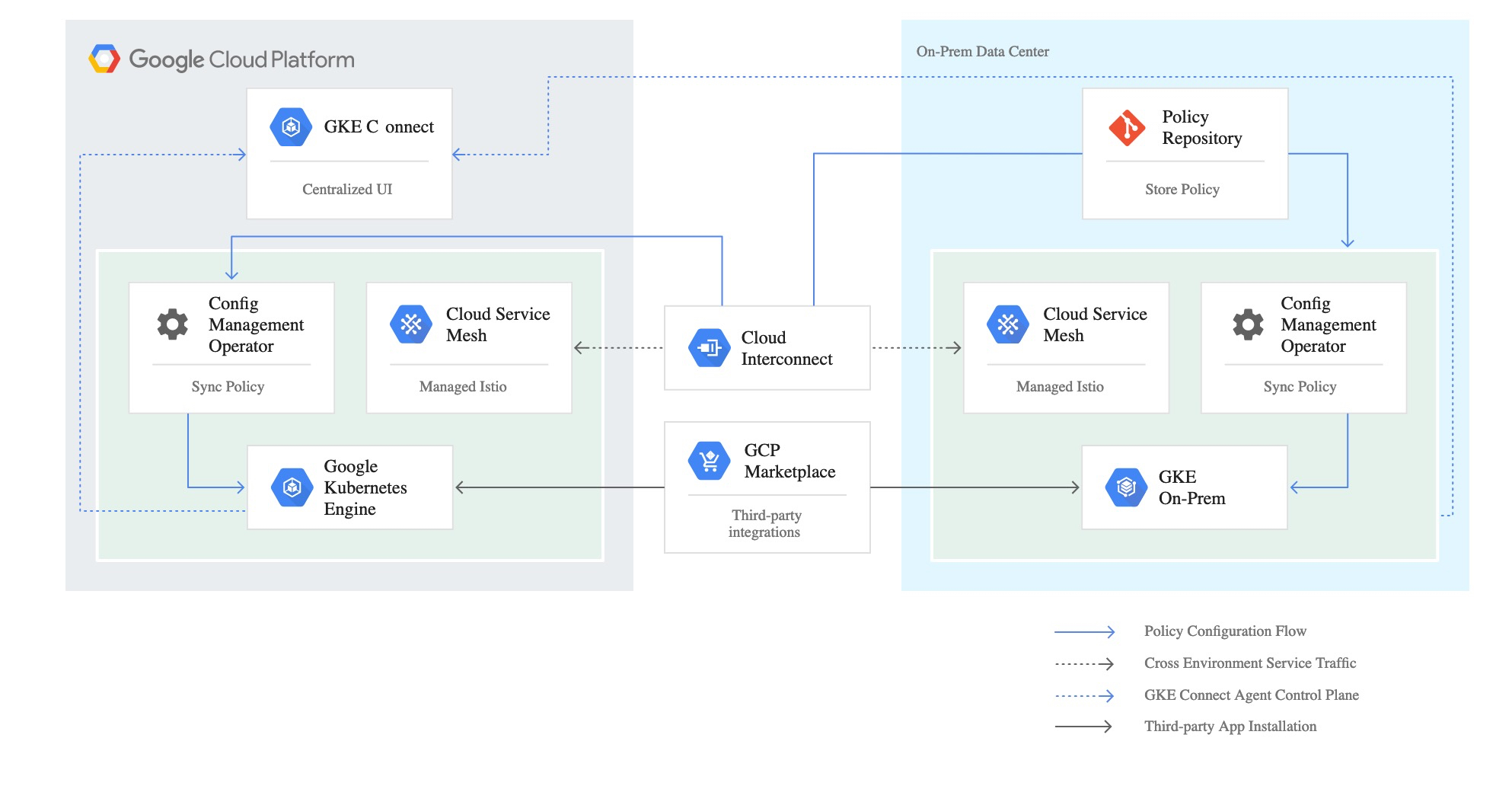
是的,這張圖在組件上畫的非常清晰,Anthos Config Mangement,在運行形態上是一個k8s的operator,部署在多個集群里面,并且應該可以從同一個遠程git repo里面讀取配置,從這個demo庫里面,我們可以看到這個operator讀取git庫的配置
apiVersion: addons.sigs.k8s.io/v1alpha1 kind: ConfigManagement metadata: name: config-management spec: git: syncRepo: git@github.com:GoogleCloudPlatform/csp-config-management.git syncBranch: "0.1.0" syncWait: 5 secretType: ssh policyDir: foo-corp
這里幾個參數清晰的標明,Anthos Config Mangement會去每5秒鐘讀取一次git repo的0.1.0分支,并按照這個分支上的配置來進行后續的操作。那么,這些操作具體能干啥,怎么干呢?官方文檔實在是太可憐了,就幾句話就想打發我們,不過,從Demo里面我們可以試圖尋找這些功能和配置的對應關系。讀者可以把demo庫 git clone下來,比對著看。
官方的功能描述是:
從單一代碼庫衍生的真實,控制和管理
允許使用代碼審查,驗證和回滾工作流程。
避免陰影操作,由于手動更改導致的Kubernetes集群之間不同步。
允許使用CI / CD管道進行自動化測試和部署。
跨所有集群的一步式部署
Anthos Config Management將單個Git提交轉換為跨所有集群的多個kubectl命令。
只需還原Git中的更改即可回滾。 然后,大規模自動部署恢復。
豐富的繼承模型,簡化修改
使用命名空間,您可以為所有集群,某些集群,某些命名空間甚至自定義資源創建配置。
使用命名空間繼承,您可以創建一個分層的命名空間模型,該模型允許跨repo文件夾結構進行配置繼承。
這是demo的樹形目錄結構
. ├── cluster │ ├── namespace-reader-clusterrole.yaml │ ├── namespace-reader-clusterrolebinding.yaml │ ├── pod-creator-clusterrole.yaml │ └── pod-security-policy.yaml ├── namespaces │ ├── audit │ │ └── namespace.yaml │ ├── online │ │ └── shipping-app-backend │ │ ├── pod-creator-rolebinding.yaml │ │ ├── quota.yaml │ │ ├── shipping-dev │ │ │ ├── job-creator-role.yaml │ │ │ ├── job-creator-rolebinding.yaml │ │ │ ├── namespace.yaml │ │ │ └── quota.yaml │ │ ├── shipping-prod │ │ │ └── namespace.yaml │ │ └── shipping-staging │ │ └── namespace.yaml │ ├── sre-rolebinding.yaml │ ├── sre-supported-selector.yaml │ └── viewers-rolebinding.yaml └── system ├── config-management.yaml └── resourcequota-hierarchy.yaml
我相信應該是anthos的工作流應該是讀取cluster里面的一些安全配置,并且在所有集群上都創建這里的namespace目錄所描述的命名空間。
在一些demo視頻里面我們還看到了clusterregistry目錄,應該是用來修改集群的一些屬性,達到動態修改節點數量的目的。
但如何讓一個應用在多個集群的多個namespace流轉,當前還沒能看到痕跡,從namespace的嵌套目錄來看,應用WorkLoad會經過這些目錄的層級,然后動態的修改自己的一些配置。這些細節還有待研究。
Anthos是在多k8s集群的場景下,想到了這兩點
既然k8s把所有東西的狀態變為靜態的yaml文本描述,那么這些配置存在etcd里面并用kubectl去修改就是低效的,完全可以用git存起來
這些配置之間是有冗余的,完全可以通過模板化的方式去自動搞定單個應用多集群的配置
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





