溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行一次年輕代GC長暫停問題的解決與思考,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
公司某規則引擎系統,在每次發版啟動會手動預熱,預熱完成當流量切進來之后會偶發的出現一次長達1-2秒的年輕代GC(流量并不大,并且LB下的每一臺服務都會出現該情況)
在這次長暫停之后,每一次的年輕代GC暫停時間又都恢復在20-100ms以內
2s雖然看起來不長,但是對比規則引擎每次10ms左右的響應時間來說,還是不可以接受的;并且由于該規則引擎響應超時,還會導致出單超時失敗
在分析該系統GC日志后發現,2s暫停發生在Young GC階段,而且每次發生長暫停的Young GC都會伴隨著新生代對象的晉升(Promotion)
核心JVM參數(Oracle JDK7)
-Xms10G
-Xmx10G
-XX:NewSize=4G
-XX:PermSize=1g
-XX:MaxPermSize=4g
-XX:+UseConcMarkSweepGC
復制代碼啟動后第一次年輕代GC日志
2020-04-23T16:28:31.108+0800: [GC2020-04-23T16:28:31.108+0800: [ParNew2020-04-23T16:28:31.229+0800: [SoftReference, 0 refs, 0.0000950 secs]2020-04-23T16:28:31.229+0800: [WeakReference, 1156 refs, 0.0001040 secs]2020-04-23T16:28:31.229+0800: [FinalReference, 10410 refs, 0.0103720 secs]2020-04-23T16:28:31.240+0800: [PhantomReference, 286 refs, 2 refs, 0.0129420 secs]2020-04-23T16:28:31.253+0800: [JNI Weak Reference, 0.0000000 secs]
Desired survivor size 214728704 bytes, new threshold 1 (max 15)
- age 1: 315529928 bytes, 315529928 total
- age 2: 40956656 bytes, 356486584 total
- age 3: 8408040 bytes, 364894624 total
: 3544342K->374555K(3774912K), 0.1444710 secs] 3544342K->374555K(10066368K), 0.1446290 secs] [Times: user=1.46 sys=0.09, real=0.15 secs]
復制代碼長暫停年輕代GC日志
2020-04-23T17:18:28.514+0800: [GC2020-04-23T17:18:28.514+0800: [ParNew2020-04-23T17:18:29.975+0800: [SoftReference, 0 refs, 0.0000660 secs]2020-04-23T17:18:29.975+0800: [WeakReference, 1224 refs, 0.0001400 secs]2020-04-23T17:18:29.975+0800: [FinalReference, 8898 refs, 0.0149670 secs]2020-04-23T17:18:29.990+0800: [PhantomReference, 600 refs, 1 refs, 0.0344300 secs]2020-04-23T17:18:30.025+0800: [JNI Weak Reference, 0.0000210 secs]
Desired survivor size 214728704 bytes, new threshold 15 (max 15)
- age 1: 79203576 bytes, 79203576 total
: 3730075K->304371K(3774912K), 1.5114000 secs] 3730075K->676858K(10066368K), 1.5114870 secs] [Times: user=6.32 sys=0.58, real=1.51 secs]
復制代碼從這個長暫停的GC日志來看,是發生了晉升的,在Young GC后,有363M+的對象晉升到了老年代,這個晉升操作因該就是耗時原因(ps: 檢查過safepoint原因,不存在異常)
由于日志參數中沒有配置-XX:+PrintHeapAtGC參數,這里是手動計算的晉升大小:
年輕代年輕變化 - 全堆容量變化 = 晉升大小
(304371K - 3730075K) - (676858K - 3730075K) = 372487K(363M)
下一次年輕代GC日志
2020-04-23T17:23:39.749+0800: [GC2020-04-23T17:23:39.749+0800: [ParNew2020-04-23T17:23:39.774+0800: [SoftReference, 0 refs, 0.0000500 secs]2020-04-23T17:23:39.774+0800: [WeakReference, 3165 refs, 0.0002720 secs]2020-04-23T17:23:39.774+0800: [FinalReference, 3520 refs, 0.0021520 secs]2020-04-23T17:23:39.776+0800: [PhantomReference, 150 refs, 1 refs, 0.0051910 secs]2020-04-23T17:23:39.782+0800: [JNI Weak Reference, 0.0000100 secs]
Desired survivor size 214728704 bytes, new threshold 15 (max 15)
- age 1: 17076040 bytes, 17076040 total
- age 2: 40832336 bytes, 57908376 total
: 3659891K->90428K(3774912K), 0.0321300 secs] 4032378K->462914K(10066368K), 0.0322210 secs] [Times: user=0.30 sys=0.00, real=0.03 secs]
復制代碼乍一看其實沒什么問題,仔細想想發現了一些不正常,為什么程序剛啟動第二次gc就發生了晉升呢
這里應該是動態年齡判定導致的,GC中晉升年齡閾值并不是固定的15,而是jvm每次gc后動態計算的
為了能更好地適應不同程序的內存狀況,虛擬機并不是永遠地要求對象的年齡必須達到了MaxTenuringThreshold才能晉升老年代,如果在Survivor空間中相同年齡所有對象大小的總和大于Survivor空間的一半,年齡大于或等于該年齡的對象就可以直接進入老年代,無須等到MaxTenuringThreshold中要求的年齡
《深入理解Java虛擬機》一書中提到,對象晉升年齡的閾值是動態判定的。
不過經查閱其他資料和驗證后,發現此處和《深入理解Java虛擬機》解釋的有些出入(或者是書上解釋的不夠清楚)
其實就是按年齡給對象分組,取total(累加值,小于等與當前年齡的對象總大小)最大的年齡分組,如果該分組的total大于survivor的一半,就將晉升年齡閾值更新為該分組的年齡
注意:不是是超過survivor一半就晉升,超過survivor一半只會重新設置晉升閾值(threshold),在下一次GC才會使用該新閾值
3544342K->374555K(3774912K), 0.1444710 secs] 年輕代
3544342K->374555K(10066368K), 0.1446290 secs] 全堆
復制代碼從上面第一次的GC日志也可以證明這個結論,在這次GC中全堆的內存變化和年輕代內存變化是相等的,所以并沒有發生對象的晉升
就像上面的日志中,第一次GC只是將threshold設置為1,因為此時survivor一半為214728704 bytes,而年齡為1的對象總和有315529928 bytes,超過了Desired survivor size,所以在本次GC后將threshold設置為年齡為1的對象年齡1
這里更新了對象晉升年齡閾值為1
Desired survivor size 214728704 bytes, new threshold 1 (max 15)
- age 1: 315529928 bytes, 315529928 total
- age 2: 40956656 bytes, 356486584 total
- age 3: 8408040 bytes, 364894624 total
復制代碼這里順便解釋下這個年齡分布的輸出內容:
- age 1: 315529928 bytes, 315529928 total
復制代碼age 1表示年齡為1的對象分組,315529928 bytes表示年齡為1的對象占用內存大小
315529928 total這個是一個累加值,表示小于等于當前分組年齡的對象總大小。先把對象按年齡分組,age 1的分組total為age 1總大小(前面的xxx bytes),age 2的分組total為age 1 + age 2總大小,age n的分組total為age 1 + age 2 + ... +age n的總大小,累加規則如下圖所示
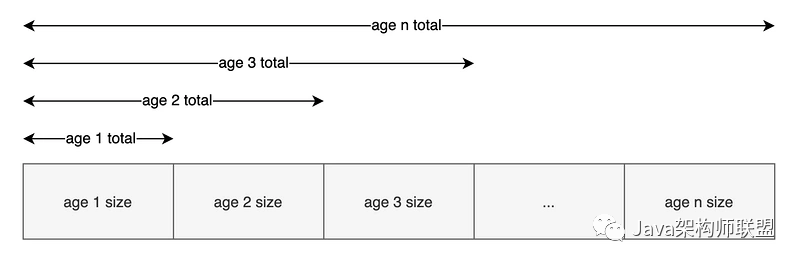
當total最大的分組的total值超過了survivor/2時,就會更新晉升閾值
在第二次年輕代GC“長暫停年輕代GC日志”中,由于新的晉升年齡閾值為1,所以那些經歷了一次GC并存活并且現在仍然可達(reachable)的對象們就會發生晉升了
由于此次GC發生了363M的對象晉升,所以導致了長暫停
JVM中這個“動態對象年齡判定”真的是合理的嗎?個人認為機制是好的,可以更好的適應不同程序的內存狀況,但不是任何場景都適合,比如在本文中這個剛啟動不就GC的場景下就會有問題
因為在程序剛啟動時,大多數對象年齡都是0或者1,很容易出現年齡為1的大量存活對象;在這個“動態對象年齡判定”機制下,就會導致新的晉升閾值被設置為1,導致這些不該晉升的對象發生了晉升
比如程序在初始化,正在加載各種資源時發生了Young GC,加載邏輯還在執行中,很多新建的對象年齡在這次GC時還是可達的(reachable)
經歷了這次GC后,這些對象年齡更新為1,但是由于“動態對象年齡判定”機制的影響,晉升年齡閾值更新為了“最大的對象年齡分組”的年齡,也就是這批剛經歷了一次GC的對象們
在這次GC之后不久,資源初始化完成了,涉及的相關對象有很可能不可達了,但是由于剛才晉升年齡閾值被更新為了1,在下一次正常的Young GC這批年齡為1的對象會直接發生晉升,提前或者說錯誤的發生了晉升
經查閱文檔、資料,發現“動態年齡判定”這個機制并不能禁用,所以如果想解決這個問題,只有靠“繞過”這個計算規則了
動態年齡的判定,是根據Survivor空間中相同年齡所有對象大小的總和大于Survivor空間的一半來判定的,那么根據這個機制解決也很簡單
由于我們足夠了解自己的系統,清楚的知道加載資源所需的大概內存,完全可以設定一個大于這些暫時可達的對象總和的數值來作為survivor的容量
比如上面的日志中,第一次GC后年齡為1的對象有315529928 Bytes(300M),Desired survivor size為(survivor size /2)214728704 bytes(204M),那么survivor就可以設置為600M以上。
不過為了穩妥,還是將survivor調到800M,這樣desired survivor size就是400M左右,在第一次Young GC后,就不會因年齡為1的對象總和超過了desired survivor size而導致晉升年齡閾值的更新了,從而也就不會有提前/錯誤晉升而導致的GC長暫停問題
survivor不可以直接指定大小,不過可以通過-XX:SurvivorRatio這種調節比例的方式來調節survivor大小
-XX:SurvivorRatio=8
表示兩個Survivor和Edgen區的比,8表示兩個Survivor:Eden=2:8,即一個Survivor占新生代的1/10。
計算方式為:
Survivor Size(1) = Young Generation Size / (2+SurvivorRatio)
Eden Size = Young Generation Size / (2+SurvivorRatio) * SurvivorRatio
復制代碼為什么晉升300M比年輕代回收3G還要慢這么多倍
根據復制算法的特性,復制算法的時間消耗主要取決于存活對象的大小,而不是總空間的大小
比如上面4G的年輕代(實際只有Eden+S0可用),GC時只需要從GC ROOTS開始遍歷對象圖,將可達的對象復制至S1即可,并不需要遍歷整個年輕代
在上面那次長暫停GC日志中,發生了363M的晉升,300M左右的回收,對比第一次GC基本可以得出,花費的1.5S基本上都是在晉升操作
那么為什么晉升操作這么耗時呢?
這里沒有深入研究Oracle JVM實現的年輕代晉升細節,不過晉升涉及跨代復制(其實都年輕代和老年代都是heap,在復制這件事上本質上沒什么區別,都是memcpy而已,只是需要額外處理的邏輯更多了)
,所需處理的邏輯會更復雜一些,比如指針的更新等操作,更耗時也是可以理解的,
這里也附上一段可以在本地模擬問題的代碼,Oracle JDK7下可直接運行測試
//jdk7.。
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
public class PromotionTest {
public static void main(String[] args) throws IOException {
//模擬初始化資源場景
List<Object> dataList = new ArrayList<>();
for (int i = 0; i < 5; i++) {
dataList.add(new InnerObject());
}
//模擬流量進入場景
for (int i = 0; i < 73; i++) {
if(i == 72){
System.out.println("Execute young gc...Adjust promotion threshold to 1");
}
new InnerObject();
}
System.out.println("Execute full gc...dataList has been promoted to cms old space");
//這里注意dataList中的對象在這次Full GC后會進入老年代
System.gc();
}
public static byte[] createData(){
int dataSize = 1024*1024*4;//4m
byte[] data = new byte[dataSize];
for (int j = 0; j < dataSize; j++) {
data[j] = 1;
}
return data;
}
static class InnerObject{
private Object data;
public InnerObject() {
this.data = createData();
}
}
}
復制代碼jvm options
-server -Xmn400M -XX:SurvivorRatio=9 -Xms1000M -Xmx1000M -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintTenuringDistribution -XX:+PrintHeapAtGC -XX:+PrintReferenceGC -XX:+PrintGCApplicationStoppedTime -XX:+UseConcMarkSweepGC
看完上述內容,你們掌握如何進行一次年輕代GC長暫停問題的解決與思考的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





