溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
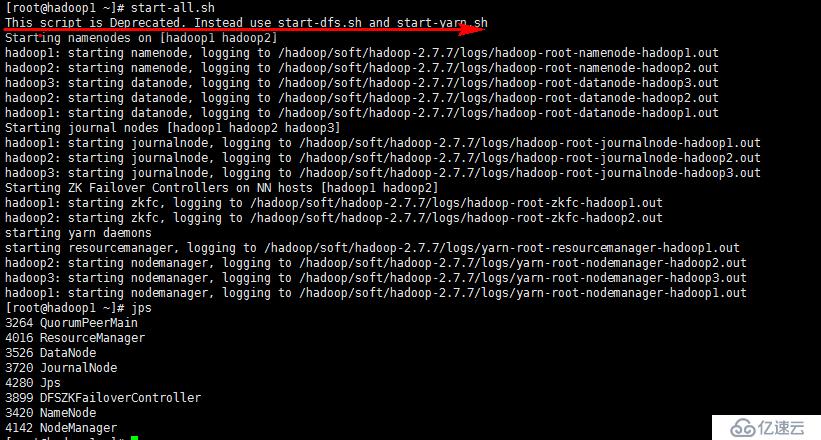
集群節點服務啟停
如圖所示腳本所在路徑:主要分類類命令:管理hdfs和管理yarn資源
服務啟動方式:分別啟動各節點服務、集群腳本啟動整個服務。
hadoop-daemon.sh <start | stop> namenode | datanode | journalnode |zkfc
hadoop-daemons.sh <start | stop> namenode | datanode |z kfc#表示啟動集群內所有dn/nn服務
yarn-daemon.sh start |stop resourcemanager | nodemanager | proxyserver
yarn-daemons.sh start |stop resourcemanager | nodemanager | proxyserver #表示啟動yarn集群內所有rm/nm等服務
mr-jobhistory-daemon.sh start | stop historyserver
[root@hadoop1 ~]# hadoop-daemons.sh start journalnode
hadoop1: starting journalnode, logging to /hadoop/soft/hadoop-2.7.7/logs/hadoop-root-journalnode-hadoop1.out
hadoop2: starting journalnode, logging to /hadoop/soft/hadoop-2.7.7/logs/hadoop-root-journalnode-hadoop2.out
hadoop3: starting journalnode, logging to /hadoop/soft/hadoop-2.7.7/logs/hadoop-root-journalnode-hadoop3.out
[root@hadoop1 ~]# jps
1628 JournalNode
1663 Jps
[root@hadoop1 ~]# ssh hadoop2 jps
1513 Jps
1452 JournalNode
[root@hadoop1 ~]# ssh hadoop3 jps
1473 Jps
1412 JournalNodestart-dfs.sh | stop-dfs.sh #啟停所有hdfs服務
start-yarn.sh | stop-yarn.sh #啟停所有yarn服務
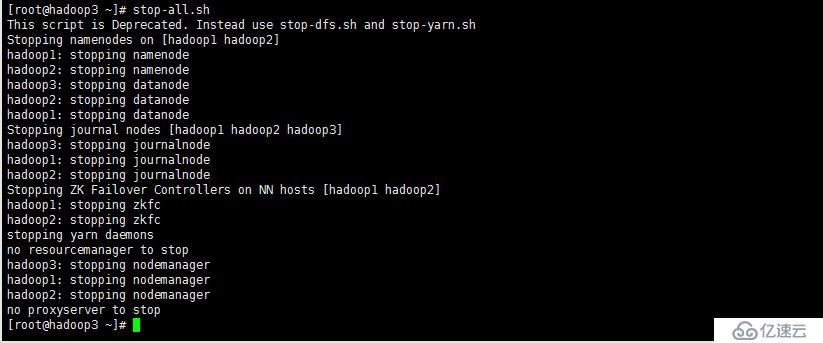
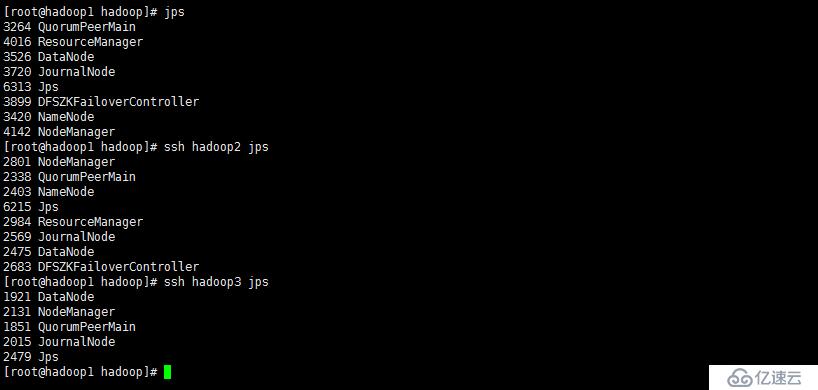
start-all.sh | stop-all.sh #可以啟停所有hdfs、yarn服務,這兩個腳本即將廢棄,建議使用上面兩個腳本管理服務。
Usage: hadoop [--config confdir] [COMMAND | CLASSNAME]
fs run a generic filesystem user client#運行一個文件系統客戶端
version print the version #查看版本信息
jar <jar> run a jar file #運行jar文件,注使用**yarn jar**運行yarn應用
distcp <srcurl> <desturl> #遞歸復制文件或目錄;DistCp(分布式拷貝)是用于大規模集群內部和集群之間拷貝的工具。 它使用Map/Reduce實現文件分發,錯誤處理和恢復,以及報告生成
archive -archiveName NAME -p <parent path> <src>* <dest> #創建hadoop歸檔文件
classpath #列出所需要的類庫 bash$ hadoop distcp hdfs://nn1:8020/foo/bar hdfs://nn2:8020/bar/foo
[root@hadoop2 ~]# hadoop/hdfs fs
Usage: hadoop fs [generic options]
[-cat [-ignoreCrc] <src> ...] #查看文件內容
[-checksum <src> ...] #查看文件校驗碼
[-chgrp [-R] GROUP PATH...] #修改文件屬組
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] #修改文件權限
[-chown [-R] [OWNER][:[GROUP]] PATH...] #修改文件屬主或屬組
[-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>] #復制本地文件到hdfs文件系統,類似put命令
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] #復制hdfs文件到本地,類似get命令
[-cp [-f] [-p | -p[topax]] <src> ... <dst>] #允許多源復制操作 ,目標路徑必須是目錄
[-createSnapshot <snapshotDir> [<snapshotName>]] #創建快照
[-deleteSnapshot <snapshotDir> <snapshotName>] #刪除快照
[-df [-h] [<path> ...]] #顯示文件系統使用空間
[-du [-s] [-h] <path> ...] #顯示某個目錄內包含的文件的大小,目錄占用空間大小,與Linux命令一樣
[-find <path> ... <expression> ...] #查找文件
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getfacl [-R] <path>]
[-getfattr [-R] {-n name | -d} [-e en] <path>]
[-help [cmd ...]] #查看幫助
[-ls [-d] [-h] [-R] [<path> ...]] #替代“hadoop fs -ls -R”
[-mkdir [-p] <path> ...] #創建目錄
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] [-l] <localsrc> ... <dst>]
[-renameSnapshot <snapshotDir> <oldName> <newName>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
[-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]]
[-setfattr {-n name [-v value] | -x name} <path>]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>] #測試命令 ,-d是否為目錄,-e文件是否存在,-z是否為空文件,用法一樣
[-text [-ignoreCrc] <src> ...]
[-touchz <path> ...] #創建 0字節空文件
[-truncate [-w] <length> <path> ...]
[-usage [cmd ...]] #查看命令的用法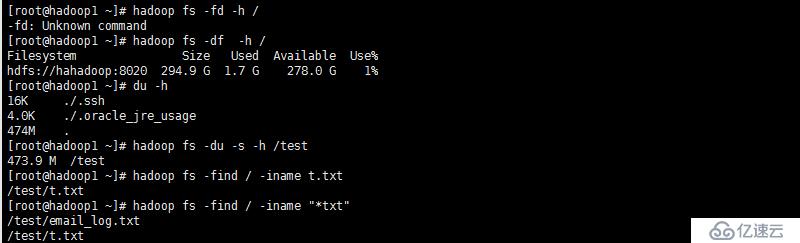
[root@hadoop2 ~]# hdfs haadmin # dfs管理客戶端,查看hdfs狀態集群
Usage: haadmin
[-transitionToActive [--forceactive] <serviceId>]
[-transitionToStandby <serviceId>]
[-failover [--forcefence] [--forceactive] <serviceId> <serviceId>] #以上3條關于手動故障轉移命令
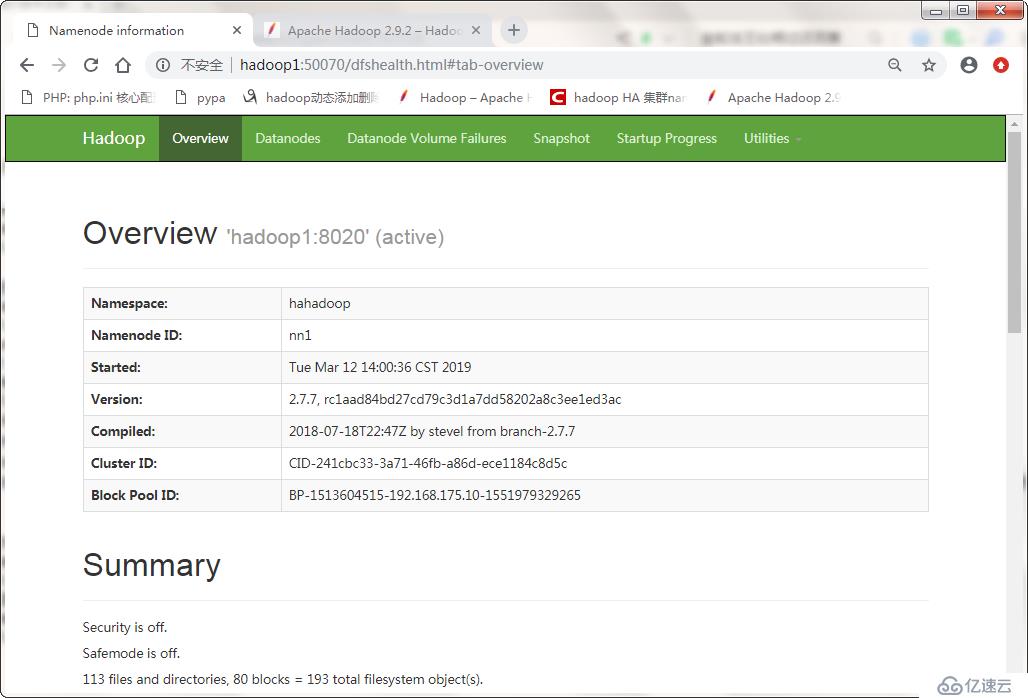
[-getServiceState <serviceId>] #查看nn節點處active還是standby狀態
[-checkHealth <serviceId>] #檢查nn節點是否健康
[-help <command>] #查看命令幫助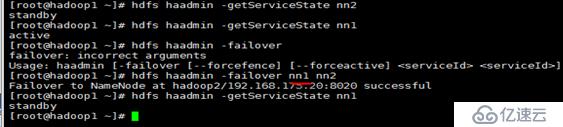
Usage: hdfs dfsadmin :Note: hdfs超級管理員才能夠運行該命令
[-report [-live] [-dead] [-decommissioning]] #報告文件系統的基本信息和統計信息
[-safemode <enter | leave | get | wait>] #安全模式維護命令。安全模式是Namenode的一個狀態, 不接受對名字空間的更改(只讀)、 不復制或刪除塊
[-saveNamespace] #保存當前名稱空間到存儲目錄,開始新edit-log,需要安全模式
[-rollEdits]
[-restoreFailedStorage true|false|check]
[-refreshNodes] #重新讀取hosts和exclude文件,更新允許連到NN的那些需要退出或新加入的Datanode。
[-setQuota <quota> <dirname>...<dirname>] #限制一個目錄包含最多子目錄和文件
#hdfs dfsadmin -setQuota 1t /user/dirname
[-clrQuota <dirname>...<dirname>]
[-setSpaceQuota <quota> [-storageType <storagetype>] <dirname>...<dirname>] #設置一個目錄最多使用空間
[-clrSpaceQuota [-storageType <storagetype>] <dirname>...<dirname>]
[-refreshServiceAcl]
[-refreshUserToGroupsMappings]
[-refreshSuperUserGroupsConfiguration]
[-refreshCallQueue] #刷新請求隊列
[-refresh <host:ipc_port> <key> [arg1..argn]
[-reconfig <datanode|...> <host:ipc_port> <start|status>] #將datanode節點重新加入集群
[-refreshNamenodes datanode_host:ipc_port]
[-deleteBlockPool datanode_host:ipc_port blockpoolId [force]]
[-setBalancerBandwidth <bandwidth in bytes per second>]
[-fetchImage <local directory>]
[-allowSnapshot <snapshotDir>] #某目錄允許快照才可以進行快照
[-disallowSnapshot <snapshotDir>]
[-shutdownDatanode <datanode_host:ipc_port> [upgrade]]
[-getDatanodeInfo <datanode_host:ipc_port>]
[-metasave filename] hadoop balancer [-threshold <threshold>] # 磁盤容量的百分比
hdfs達到平衡狀態達到磁盤使用率偏差值,值越低越平衡,但消耗時間也越長。
[root@hadoop2 ~]# yarn rmadmin #resourcemanager 客戶端
Usage: yarn rmadmin
-refreshQueues #重載隊列的acl、狀態及調度器隊列
-refreshNodes #為RM刷新主機信息
-refreshSuperUserGroupsConfiguration
-refreshUserToGroupsMappings
-refreshAdminAcls
-refreshServiceAcl
-addToClusterNodeLabels [label1,label2,label3] (label splitted by ",")
-removeFromClusterNodeLabels [label1,label2,label3] (label splitted by ",")
-replaceLabelsOnNode [node1[:port]=label1,label2 node2[:port]=label1,label2]
-directlyAccessNodeLabelStore
-transitionToActive [--forceactive] <serviceId>#rm節點故障轉移
-transitionToStandby <serviceId>
-failover [--forcefence] [--forceactive] <serviceId> <serviceId>
-getServiceState <serviceId>#檢查當前rm狀態
-checkHealth <serviceId>
-help [cmd]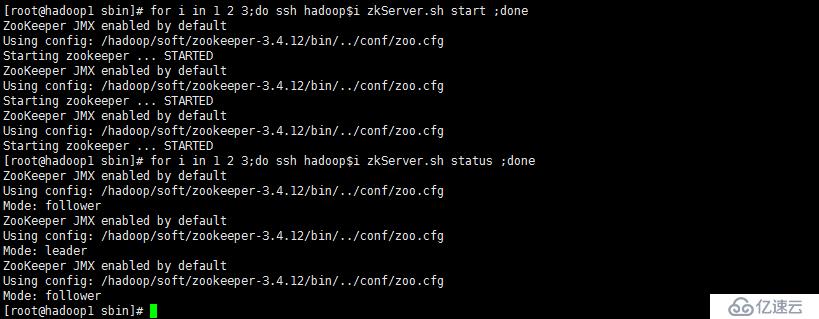

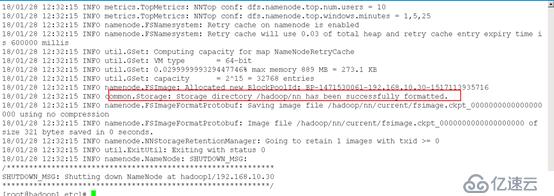
hdfs namenode -format
hadoop1:hadoop-daemon.sh start namenode
hadoop2:hdfs namenode -bootstrapStandby,在啟動nn
hdfs zkfc -formatZK
hadoop-daemon.sh start zkfc #把故障轉移節點服務啟動,否則當前狀態都為standby!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。