溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
同志們,此部分,重要的不能再重要了
1、HBase發展到當下,對其進行的各種優化從未停止,而GC優化更是其中的重中之重。
hbase gc調優方向
從0.94版本提出MemStoreLAB策略、Memstore Chuck Pool策略對寫緩存Memstore進行優化開始,到0.96版本提出BucketCache以及堆外內存方案對讀緩存BlockCache進行優化,再到后續2.0版本宣稱會引入更多堆外內存,可見HBase會將堆外內存的使用作為優化GC的一個戰略方向。
然而無論引入多少堆外內存,都無法避免讀寫全路徑使用JVM內存,就拿BucketCache中offheap模式來講,即使HBase數據塊是緩存在堆外內存的,但是在讀取的時候還是會首先將堆外內存中的block加載到JVM內存中,再返回給用戶。
這句話的理解在:http://hbasefly.com/2016/04/26/hbase-blockcache-2/
//提到了
BucketCache工作模式 //
比如,內存分配時heap模式需要首先從操作系統分配內存再拷貝到JVM heap,相比offheap直接從操作系統分配內存更耗時;但是反過來,讀取緩存時heap模式可以從JVM heap中直接讀取,而offheap模式則需要首先從操作系統拷貝到JVM heap再讀取,顯得后者更費時。
可見,無論使用多少堆外內存,對JVM內存的使用終究是繞不過去,既然繞不過去,就還是需要落腳于GC本身,對GC本身進行優化。
回顧CMS GC 算法的工作原理
先上圖: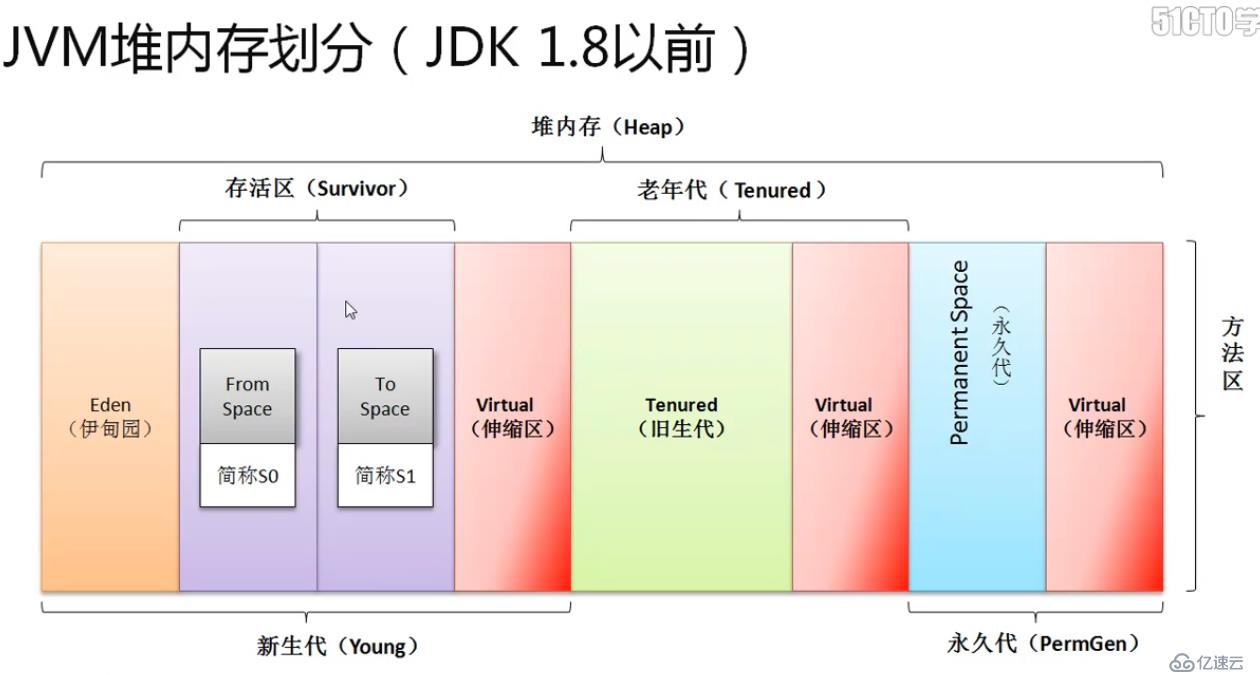
詳細請見:https://blog.51cto.com/12445535/2372976
文中對JVM的內存結構以及CMS GC進行了相當詳細的介紹。
先來看看GC調優的最終目標和基本原則:
下面對參數的調優技巧都謹遵以上原則,尤其對于HBase這類延遲敏感性項目而言,在盡量避免嚴重影響用戶讀寫的情況下使得GC更加平穩、暫停時間更短!
//也就是遵循一個原則 不管是minor gc還是cms gc盡量時間段,減少cms gc的次數。
主要分三個階段進行。
1、第一階段會介紹適用于所有場景下的GC參數配置,這些參數不需要太多解釋讀者就可以輕松理解;
2、第二階段和第三階段分別就兩組參數進行調優講解,這兩組參數一般會根據不同的應用場景進行設置才能使得GC效果最好,鑒于這兩組參數的復雜性,
階段一:默認推薦配置 //每個參數什么意思講解
-Xmx -Xms -Xmn -Xss -XX:MaxPermSize= M -XX:SurvivorRatio=S -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:MaxTenuringThreshold=N -XX:+UseCMSCompactAtFullCollection -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=C -XX:-DisableExplicitGC
-Xmx:分配給JVM的最大堆內存
-Xms:分配給JVM的初始內存,此值一般和Xmx設置相同
-Xmn:分配給young區內存大小,此值的設置對系統性能影響很大,后面第二階段將會重點討論此值的參數的調優
-Xss:分配給每個線程的堆棧大小,在一些對線程數敏感的系統中該值設置比較重要,一般設置為256K~1M左右
-XX:MaxPermSize= M :分配給持久代的內存大小
-XX:SurvivorRatio=S : 表示young區中eden區和survivor區的內存大小比例,默認為8 該值的設置對系統性能影響很大,第三階段會重點討論該參數的調優
-XX:+UseConcMarkSweepGC :表示回收器使用CMS CG策略
-XX:+UseParNewGC :表示young區采用并行回收機制 推薦使用 &&&&&
-XX:+CMSParallelRemarkEnabled : 表示cms的remark階段采用并行的方式,推薦使用 &&&&&
-XX:MaxTenuringThreshold=N : 表示young區對象晉升到Tenured區的閾值,該值的設置對系統的影響很大,在第三節點會重點討論*****
-XX:+UseCMSCompactAtFullCollection :表示每次執行完cms gc之后執行一次碎片整合 推薦使用 &&&&&
-XX:+UseCMSInitiatingOccupancyOnly :表示cms gc只基于參數CMSInitiatingOccupancyFraction觸發
-Xx:CMSInitiatingOccupancyFraction : 表示當tenured(老年代)區內存使用量超過tenured總大小的百分比超過該閾值之后會觸發cms gc,該值一般設置為70%~80%
-XX:-DisableExplicitGC : 表示禁止使用命令System.gc() 該命令用于觸發整個JVM的垃圾回收,一般都是長時間full gc 推薦使用 &&&&&
-XX:+PrintTenuringDistribution才能打印對應日志,強烈建議線上集群開啟該參數,&&&&&
使用所有場景下的gc參數調優
*****通過上文對各個GC參數的說明,可以輕松得出第一階段推薦的參數設置如下,這樣的設置基本適用于所有的場景:
-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=75% -XX:-DisableExplicitGC
1、上文通過解釋各個GC參數意義給出了基本的推薦設置,同時也提到幾個對性能影響重大的參數:
2、Xmn、SurvivorRatio以及MaxTenuringThreshold,下面會通過理論推理+實驗驗證的方式對這幾個參數在HBase系統的設置進行調優。
需要強調的是HBase全部配置為BucketCache模式,而不是LruBlockCache。使用了大量堆外內存作為讀緩存,在很大程度上優化了GC
可見BucketCache模式比LruBlockCache模式GC表現好很多,強烈建議線上配置BucketCache模式。
介紹完實驗基本條件后,再對GC日志進行簡單的解釋,方便下文對日志進行分析。需要注意只有在添加參數-XX:+PrintTenuringDistribution才能打印對應日志,強烈建議線上集群開啟該參數,
HBase場景內存分析
因此可以看出,HBase系統屬于長壽對象居多的工程,因此GC的時候只需要將RPC這類短壽對象在Young區淘汰掉就可以達到最好的GC效果。
NewParSize表示young區大小,而young區大小直接決定minor gc的頻率。
minor gc頻率一方面決定單次minor gc的時間長短,gc越頻繁,gc時間就越短;一方面決定對象晉升到老年代的量,gc越頻繁,晉升到老年代的對象量就越大。解釋起來就是:
因此設置NewParSize需要進行一定的平衡,不能設置太大,也不能設置太小。
小結:
1、Xmn=2是一個最優的選擇
//Xmn設置過小會導致CMS GC性能較差,而設置過大會導致Minor GC性能較差,
//因此建議在JVM Heap為64g以上的情況下設置Xmn在1~3g之間
//在32g之下設置為512m~1g
細節:
具體最好經過簡單的線上調試;需要特別強調的是,筆者在很多場合都看到很多HBase線上集群會把Xmn設置的很大,比如有些集群Xmx為48g,Xmn為10g,查看日志發現GC性能極差:單次Minor GC基本都在300ms~500ms之間,CMS GC更是很多超過1s。在此強烈建議,將Xmn調大對GC(無論Minor GC還是CMS GC)沒有任何好處,不要設置太大。
階段三:增大Survivor區大小(減小SurvivorRatio) & 增大MaxTenuringThreshold
1、-XX:SurvivorRatio=S : 表示young區中eden區和survivor區的內存大小比例,默認為8 該值的設置對系統性能影響很大,第三階段會重點討論該參數的調優
2、-XX:MaxTenuringThreshold=N : 表示young區對象晉升到Tenured區的閾值,該值的設置對系統的影響很大,在第三節點會重點討論
小結:
1、一般情況下,默認MaxTenuringThreshold=15已經相對比較大,不需要做任何調整。
2、對于Minor GC來說,SurvivorRatio設置對其影響不是很大。而對于CMS GC來說,將SurvivorRatio設置過大簡直就是災難,性能極其差。而和默認值SurvivorRatio=8相比,將SurvivorRatio調小有利于短壽小對象更充分地淘汰,因此建議將SurvivorRatio=2
總結:
1、其中Xmn可以隨著Java分配堆內存增大而適度增大,但是不能大于4g,取值范圍在1~3g范圍;
2、SurvivorRatio一般建議選擇為2;
3、MaxTenuringThreshold設置為15;
4、對于小內存(小于64G),只需要將上述配置中Xmn改為512m-1g即可
最后小結:
通用場景
-XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=75% -XX:-DisableExplicitGC -XX:+PrintTenuringDistribution
cms gc調優(小于64G內存的)
-Xmx""g -Xms""g -Xmn1g -Xss256k -XX:MaxPermSize=256m -XX:SurvivorRatio=2 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
-XX:+CMSParallelRemarkEnabled -XX:MaxTenuringThreshold=15 -XX:+UseCMSCompactAtFullCollection -XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=75 -XX:-DisableExplicitGC -XX:+PrintTenuringDistribution
cms gc對于大內存(大于64G),采用如下配置:
-Xmx64g -Xms64g -Xmn2g -Xss256k -XX:MaxPermSize=256m -XX:SurvivorRatio=2 -XX:+UseConcMarkSweepGC -XX:+UseParNewGC
-XX:+CMSParallelRemarkEnabled -XX:MaxTenuringThreshold=15 -XX:+UseCMSCompactAtFullCollection -XX:+UseCMSInitiatingOccupancyOnly
-XX:CMSInitiatingOccupancyFraction=75 -XX:-DisableExplicitGC -XX:+PrintTenuringDistribution
小伙伴的問題1: 關于gc日志的問題
博主您好,想請教一下,gc的日志,/var/log/hbase/gc.regionserver.log每次重啟就會覆蓋,能夠配置成追加寫嗎。有時hbase報錯,想去查gc的問題時,一旦重啟就沒了之前的gc日志信息了。
答:
可以看看你的jvm配置 將GC日志設為3或者更多 -Xloggc:$HBASE_LOG_DIR/gc-regionserver-date +%Y%m%d-%H-%M.log -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=3
小伙伴的問題2:
博主你好,我也是做了好多測試,發現不同讀寫比情況下LRU的性能(吞吐、延時)都要強于CBC,看到文章中也提到了這一點,但還是想不懂為什么CBC要差一些,所以很想請教博主?
答:
因為CBC模式下bucketcache(offheap模式)使用堆外內存,堆外內存讀取會比jvm內存讀取復雜,流程更多,所以在全內存場景喜愛LRU完全好于CBC,在緩存基本不命中場景下兩者吞吐量延遲基本相當
全內存場景是指?
數據量比較小或者有大量熱點讀的場景 大多數讀都落在BlockCache場景
小伙伴的問題3:
范大神,能問下你們hbase集群zookeeper.session.timeout這個參數設置多大么,能否通過調大這個參數來降低因為GC導致的RS連接zk超時掛掉問題呢? 假如我調整到比如180秒會對hbase造成什么影響嗎? 萬分感謝!!
答:
離線集群的話設置大點沒啥問題 實時在線對延遲敏感的集群就不能設置太大
小伙伴的問題:
博主方便用 jmap -heap PID 顯示出博主的配置,然后解釋這些參數嗎?這樣可能更加方便大家看學習博主的配置。
我這邊的答案為
[root@hdfs-master-80-121 hbase]# ps -ef|grep hbase
hbase 3004 2490 0 Mar06 ? 00:54:30 /usr/java/jdk1.8.0_102/bin/java -Dproc_regionserver -XX:OnOutOfMemoryError=kill -9 %p -Djava.net.preferIPv4Stack=true -Xms4294967296 -Xmx4294967296 -XX:+UseParNewGC -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+CMSParallelRemarkEnabled -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/hbase_hbase-REGIONSERVER-e72e026ce56e3850d7702a2ca6ecc206_pid3004.hprof -XX:OnOutOfMemoryError=/usr/lib64/cmf/service/common/killparent.sh -Dhbase.log.dir=/var/log/hbase -Dhbase.log.file=hbase-cmf-hbase-REGIONSERVER-hdfs-master-80-121.log.out -Dhbase.home.dir=/opt/cloudera/parcels/CDH-5.9.2-1.cdh6.9.2.p0.3/lib/hbase -Dhbase.id.str= -Dhbase.root.logger=INFO,RFA -Djava.library.path=/opt/cloudera/parcels/CDH-5.9.2-1.cdh6.9.2.p0.3/lib/hadoop/lib/native:/opt/cloudera/parcels/CDH-5.9.2-1.cdh6.9.2.p0.3/lib/hbase/lib/native/Linux-amd64-64 -Dhbase.security.logger=INFO,RFAS org.apache.hadoop.hbase.regionserver.HRegionServer start
hbase 3090 3004 0 Mar06 ? 00:26:57 /bin/bash /usr/lib64/cmf/service/hbase/hbase.sh regionserver start
hbase 6981 3090 0 18:04 ? 00:00:00 sleep 1
root 6983 21889 0 18:04 pts/0 00:00:00 grep --color=auto hbase
[root@hdfs-master-80-121 hbase]# jmap -heap 3004
Attaching to process ID 3004, please wait...
Debugger attached successfully.
Server compiler detected.
JVM version is 25.102-b14
using parallel threads in the new generation.
using thread-local object allocation.
Concurrent Mark-Sweep GC
Heap Configuration:
MinHeapFreeRatio = 40
MaxHeapFreeRatio = 70
MaxHeapSize = 4294967296 (4096.0MB)
NewSize = 348913664 (332.75MB)
MaxNewSize = 348913664 (332.75MB)
OldSize = 3946053632 (3763.25MB)
NewRatio = 2
SurvivorRatio = 8
MetaspaceSize = 21807104 (20.796875MB)
CompressedClassSpaceSize = 1073741824 (1024.0MB)
MaxMetaspaceSize = 17592186044415 MB
G1HeapRegionSize = 0 (0.0MB)
Heap Usage:
New Generation (Eden + 1 Survivor Space):
capacity = 314048512 (299.5MB)
used = 94743000 (90.35396575927734MB)
free = 219305512 (209.14603424072266MB)
30.168269034817143% used
Eden Space:
capacity = 279183360 (266.25MB)
used = 91102232 (86.8818588256836MB)
free = 188081128 (179.3681411743164MB)
32.63168406598445% used
From Space:
capacity = 34865152 (33.25MB)
used = 3640768 (3.47210693359375MB)
free = 31224384 (29.77789306640625MB)
10.442426867951127% used
To Space:
capacity = 34865152 (33.25MB)
used = 0 (0.0MB)
free = 34865152 (33.25MB)
0.0% used
concurrent mark-sweep generation:
capacity = 3946053632 (3763.25MB)
used = 16010552 (15.268852233886719MB)
free = 3930043080 (3747.9811477661133MB)
0.4057357931013544% used
14606 interned Strings occupying 1393920 bytes.
小伙伴的問題6:
您好,請問您為什么沒有使用G1 GC機制呢?
答:
沒有用G1GC一方面是因為我們這邊內存使用量沒有那么大,另一方面G1GC要用好需要關注太多參數配置。不過以后是一個大的方向
請問有G1調優的嗎 我等了三年了
可以參考下:http://openinx.github.io/ppt/hbaseconasia2017_paper_18.pdf
參考鏈接:
http://hbasefly.com/2016/08/09/hbase-cms-gc/
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





