溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“TensorFlow on Kubernetes性能怎么理解”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
增加worker數,一定范圍內能帶來較好的性能提升,但是繼續增加worker數時,訓練性能提升不明顯;
增加ps數,一定范圍內能帶來較好的性能提升,但是繼續增加ps數時,訓練性能提升不明顯;
可能原因:
與ps和worker的分布情況強相關:
目前的調度策略,主要根據服務器的cpu和內存使用情況進行均衡調度,盡量使得集群中每臺服務器的cpu和內存使用率相當。這種情況下,ps和worker的調度存在一定程度的隨機性。
如果調度時,每臺包含worker的服務器都有對應一個ps,那么訓練性能會更高?如果有,性能提升多少呢?
K8S中的worker從HDFS集群中讀取訓練數據時存在IO瓶頸?可能網絡上的或者是HDFS本身的配置,需要通過HDFS集群的監控來進一步排查。
下面,是針對第一種“可能原因:與ps和worker的分布情況強相關“ 設計的測試場景和用例:
| 用例ID | 服務器數 | worker數 | ps數 | 說明 |
|---|---|---|---|---|
| 1 | 1 | 10 | 1 | 一臺服務器部署了10個worker和1個ps |
| 2 | 5 | 50 | 5 | 5臺服務器分別部署了10個worker和1個p |
| 3 | 10 | 100 | 10 | 10臺服務器分別部署了10個worker和1個p |
| 4 | 20 | 200 | 20 | 20臺服務器分別部署了10個worker和1個p |
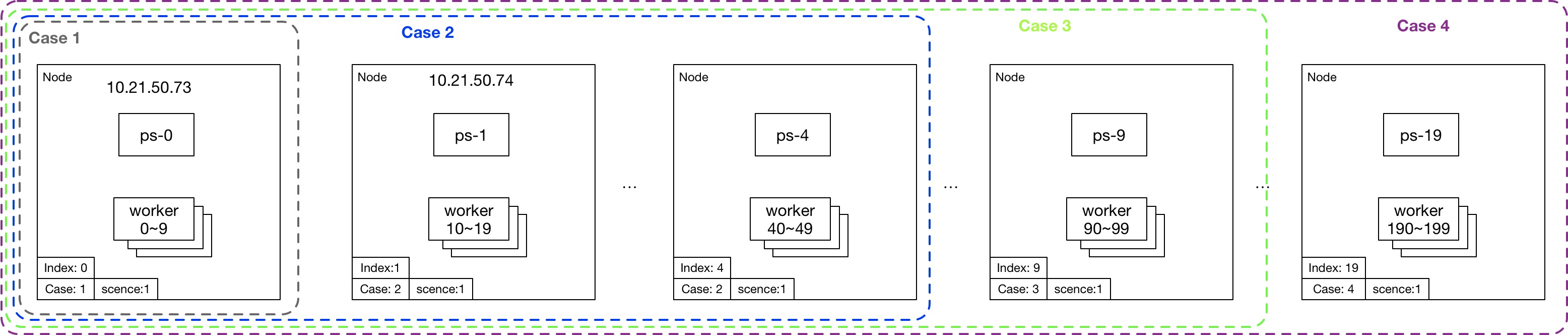
場景1的TensorFlow對象模板scene1.jinja
# scene1.jinja —— 對象模板
{%- set name = "##NAME##" -%}
{%- set worker_replicas = ##WN## -%}
{%- set ps_replicas = ##PN## -%}
{%- set script = "##SCRIPT##" -%}
{%- set case = "##CASE##" -%}
{%- set port = 2222 -%}
{%- set log_host_dir = "/var/log/tensorflow" -%}
{%- set log_container_dir = "/var/log" -%}
{%- set image = "registry.vivo.xyz:4443/bigdata_release/tensorflow1.3.0" -%}
{%- set replicas = {"worker": worker_replicas, "ps": ps_replicas} -%}
{%- macro worker_hosts() -%}
{%- for i in range(worker_replicas) -%}
{%- if not loop.first -%},{%- endif -%}
{{ name }}-worker-{{ i }}:{{ port }}
{%- endfor -%}
{%- endmacro -%}
{%- macro ps_hosts() -%}
{%- for i in range(ps_replicas) -%}
{%- if not loop.first -%},{%- endif -%}
{{ name }}-ps-{{ i }}:{{ port }}
{%- endfor -%}
{%- endmacro -%}
{%- for i in range( begin_index, end_index ) -%}
{%- if task_type == "worker" %}
---
kind: Service
apiVersion: v1
metadata:
name: {{ name }}-{{ task_type }}-{{ i }}
namespace: {{ name }}
spec:
clusterIP: None
selector:
name: {{ name }}
job: {{ task_type }}
task: "{{ i }}"
ports:
- port: {{ port }}
targetPort: 2222
---
kind: Job
apiVersion: batch/v1
metadata:
name: {{ name }}-{{ task_type }}-{{ i }}
namespace: {{ name }}
spec:
template:
metadata:
labels:
name: {{ name }}
job: {{ task_type }}
task: "{{ i }}"
spec:
imagePullSecrets:
- name: harborsecret'
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "CASE"
operator: In
values:
- "{{ case }}"
- key: "INDEX"
operator: In
values:
- "{{ i // 10 }}"
- key: "SCENCE"
operator: In
values:
- "1"
containers:
- name: {{ name }}-{{ task_type }}-{{ i }}
image: {{ image }}
resources:
requests:
memory: "4Gi"
cpu: "300m"
ports:
- containerPort: 2222
command: ["/bin/sh", "-c", "export CLASSPATH=.:/usr/lib/jvm/java-1.8.0/lib/tools.jar:$(/usr/lib/hadoop-2.6.1/bin/hadoop classpath --glob); wget -r -nH -np --cut-dir=1 -R 'index.html*,*gif' {{ script }}; cd ./{{ name }}; sh ./run.sh {{ ps_hosts() }} {{ worker_hosts() }} {{ task_type }} {{ i }} {{ ps_replicas }} {{ worker_replicas }}"]
restartPolicy: OnFailure
{%- endif -%}
{%- if task_type == "ps" -%}
---
kind: Service
apiVersion: v1
metadata:
name: {{ name }}-{{ task_type }}-{{ i }}
namespace: {{ name }}
spec:
clusterIP: None
selector:
name: {{ name }}
job: {{ task_type }}
task: "{{ i }}"
ports:
- port: {{ port }}
targetPort: 2222
---
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: {{ name }}-{{ task_type }}-{{ i }}
namespace: {{ name }}
spec:
replicas: 1
template:
metadata:
labels:
name: {{ name }}
job: {{ task_type }}
task: "{{ i }}"
spec:
imagePullSecrets:
- name: harborsecret
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "CASE"
operator: In
values:
- "{{ case }}"
- key: "INDEX"
operator: In
values:
- "{{ i }}"
- key: "SCENCE"
operator: In
values:
- "1"
containers:
- name: {{ name }}-{{ task_type }}-{{ i }}
image: {{ image }}
resources:
requests:
memory: "4Gi"
cpu: "2"
ports:
- containerPort: 2222
command: ["/bin/sh", "-c","export CLASSPATH=.:/usr/lib/jvm/java-1.8.0/lib/tools.jar:$(/usr/lib/hadoop-2.6.1/bin/hadoop classpath --glob); wget -r -nH -np --cut-dir=1 -R 'index.html*,*gif' {{ script }}; cd ./{{ name }}; sh ./run.sh {{ ps_hosts() }} {{ worker_hosts() }} {{ task_type }} {{ i }} {{ ps_replicas }} {{ worker_replicas }}"]
restartPolicy: Always
{%- endif -%}
{%- endfor -%}Label Nodes
選擇對應的節點打上對應的Label。
kubectl label node $node_name SCENCE=1 CASE=? INDEX=?
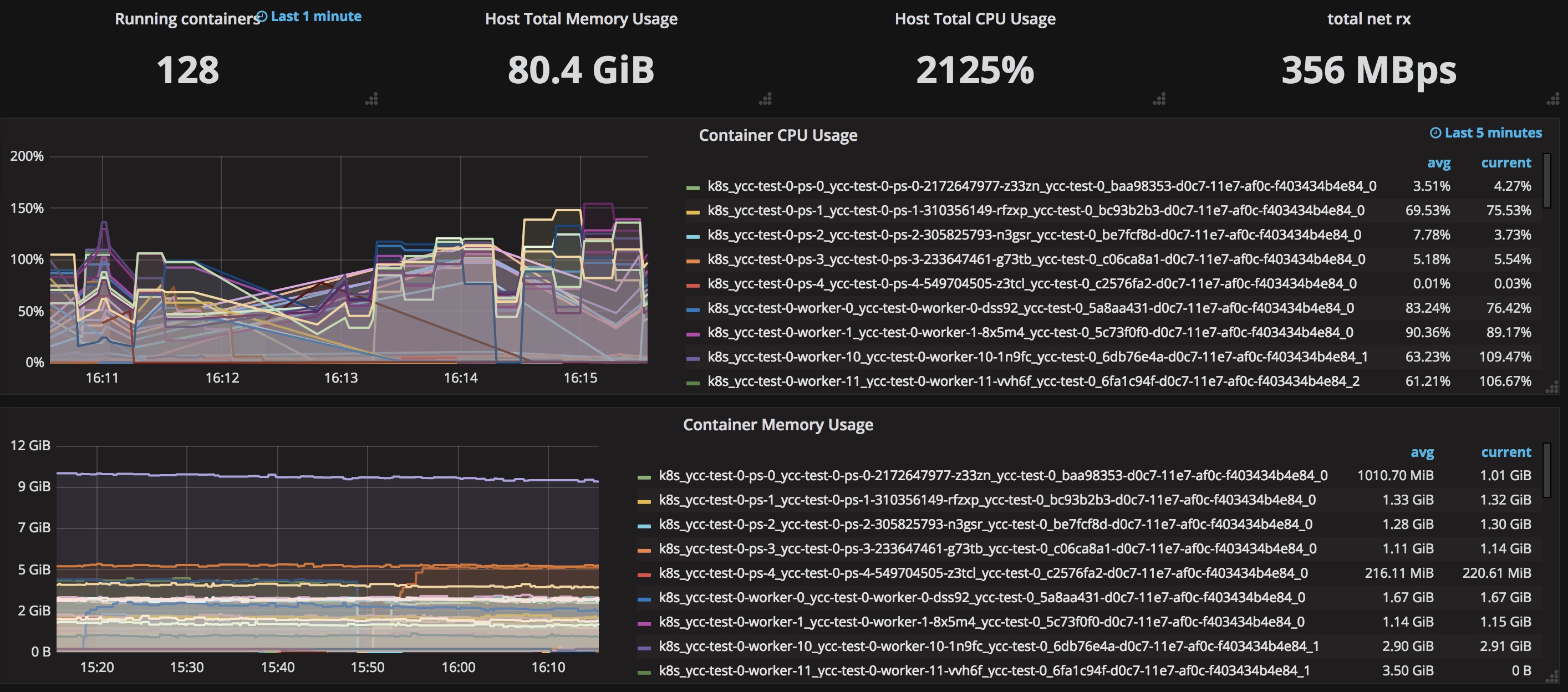
用例2的測試截圖:
| 用例ID | 服務器數 | worker數 | ps數 | 說明 |
|---|---|---|---|---|
| 1 | 2 | 10 | 1 | 一臺服務器部署10個worker,另外一臺部署1個ps |
| 2 | 10 | 20 | 5 | 5臺服務器分別部署10個worker,5臺服務器分別部署1個ps |
| 3 | 20 | 50 | 10 | 10臺服務器分別部署10個worker,10臺服務器分別部署1個ps |
| 4 | 40 | 200 | 20 | 20臺服務器分別部署10個worker,20臺服務器分別部署1個ps |
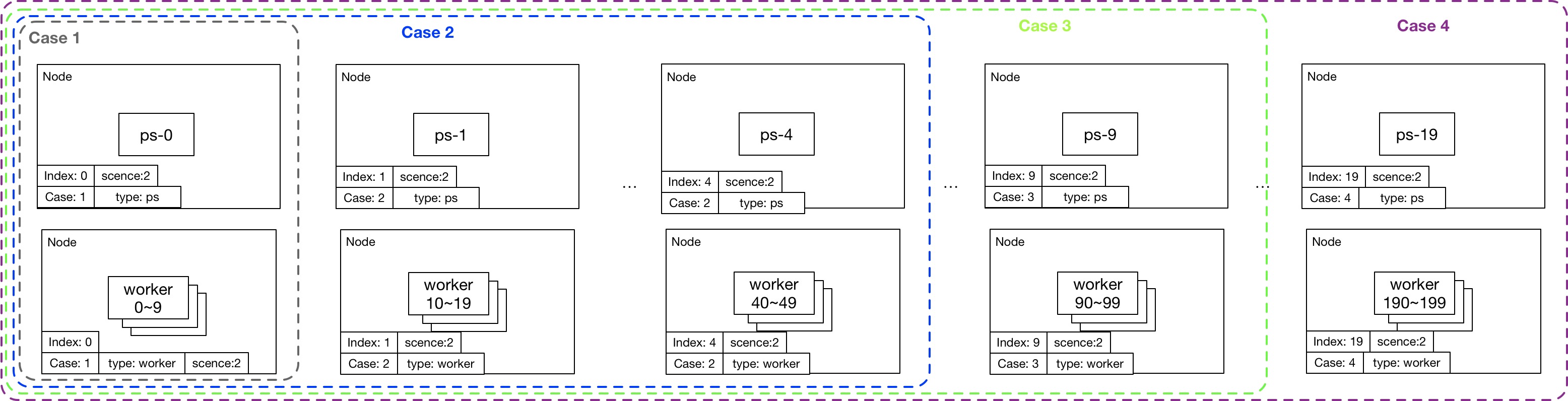
場景2的TensorFlow對象模板scene2.jinja
# scene2.jinja —— 對象模板
{%- set name = "##NAME##" -%}
{%- set worker_replicas = ##WN## -%}
{%- set ps_replicas = ##PN## -%}
{%- set script = "##SCRIPT##" -%}
{%- set case = "##CASE##" -%}
{%- set port = 2222 -%}
{%- set log_host_dir = "/var/log/tensorflow" -%}
{%- set log_container_dir = "/var/log" -%}
{%- set image = "registry.vivo.xyz:4443/bigdata_release/tensorflow1.3.0" -%}
{%- set replicas = {"worker": worker_replicas, "ps": ps_replicas} -%}
{%- macro worker_hosts() -%}
{%- for i in range(worker_replicas) -%}
{%- if not loop.first -%},{%- endif -%}
{{ name }}-worker-{{ i }}:{{ port }}
{%- endfor -%}
{%- endmacro -%}
{%- macro ps_hosts() -%}
{%- for i in range(ps_replicas) -%}
{%- if not loop.first -%},{%- endif -%}
{{ name }}-ps-{{ i }}:{{ port }}
{%- endfor -%}
{%- endmacro -%}
{%- for i in range( begin_index, end_index ) -%}
{%- if task_type == "worker" %}
---
kind: Service
apiVersion: v1
metadata:
name: {{ name }}-{{ task_type }}-{{ i }}
namespace: {{ name }}
spec:
clusterIP: None
selector:
name: {{ name }}
job: {{ task_type }}
task: "{{ i }}"
ports:
- port: {{ port }}
targetPort: 2222
---
kind: Job
apiVersion: batch/v1
metadata:
name: {{ name }}-{{ task_type }}-{{ i }}
namespace: {{ name }}
spec:
template:
metadata:
labels:
name: {{ name }}
job: {{ task_type }}
task: "{{ i }}"
spec:
imagePullSecrets:
- name: harborsecret'
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "CASE"
operator: In
values:
- "{{ case }}"
- key: "INDEX"
operator: In
values:
- "{{ i // 10 }}"
- key: "SCENCE"
operator: In
values:
- "2"
- key: "TYPE"
operator: In
values:
- "worker"
containers:
- name: {{ name }}-{{ task_type }}-{{ i }}
image: {{ image }}
resources:
requests:
memory: "4Gi"
cpu: "300m"
ports:
- containerPort: 2222
command: ["/bin/sh", "-c", "export CLASSPATH=.:/usr/lib/jvm/java-1.8.0/lib/tools.jar:$(/usr/lib/hadoop-2.6.1/bin/hadoop classpath --glob); wget -r -nH -np --cut-dir=1 -R 'index.html*,*gif' {{ script }}; cd ./{{ name }}; sh ./run.sh {{ ps_hosts() }} {{ worker_hosts() }} {{ task_type }} {{ i }} {{ ps_replicas }} {{ worker_replicas }}"]
restartPolicy: OnFailure
{%- endif -%}
{%- if task_type == "ps" -%}
---
kind: Service
apiVersion: v1
metadata:
name: {{ name }}-{{ task_type }}-{{ i }}
namespace: {{ name }}
spec:
clusterIP: None
selector:
name: {{ name }}
job: {{ task_type }}
task: "{{ i }}"
ports:
- port: {{ port }}
targetPort: 2222
---
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: {{ name }}-{{ task_type }}-{{ i }}
namespace: {{ name }}
spec:
replicas: 1
template:
metadata:
labels:
name: {{ name }}
job: {{ task_type }}
task: "{{ i }}"
spec:
imagePullSecrets:
- name: harborsecret
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: "CASE"
operator: In
values:
- "{{ case }}"
- key: "INDEX"
operator: In
values:
- "{{ i }}"
- key: "SCENCE"
operator: In
values:
- "2"
- key: "TYPE"
operator: In
values:
- "ps"
containers:
- name: {{ name }}-{{ task_type }}-{{ i }}
image: {{ image }}
resources:
requests:
memory: "4Gi"
cpu: "2"
ports:
- containerPort: 2222
command: ["/bin/sh", "-c","export CLASSPATH=.:/usr/lib/jvm/java-1.8.0/lib/tools.jar:$(/usr/lib/hadoop-2.6.1/bin/hadoop classpath --glob); wget -r -nH -np --cut-dir=1 -R 'index.html*,*gif' {{ script }}; cd ./{{ name }}; sh ./run.sh {{ ps_hosts() }} {{ worker_hosts() }} {{ task_type }} {{ i }} {{ ps_replicas }} {{ worker_replicas }}"]
restartPolicy: Always
{%- endif -%}
{%- endfor -%}Label Nodes
選擇對應的節點打上對應的Label。
kubectl label node $node_name SCENCE=1 CASE=? INDEX=? TYPE=?
用例2的測試截圖:
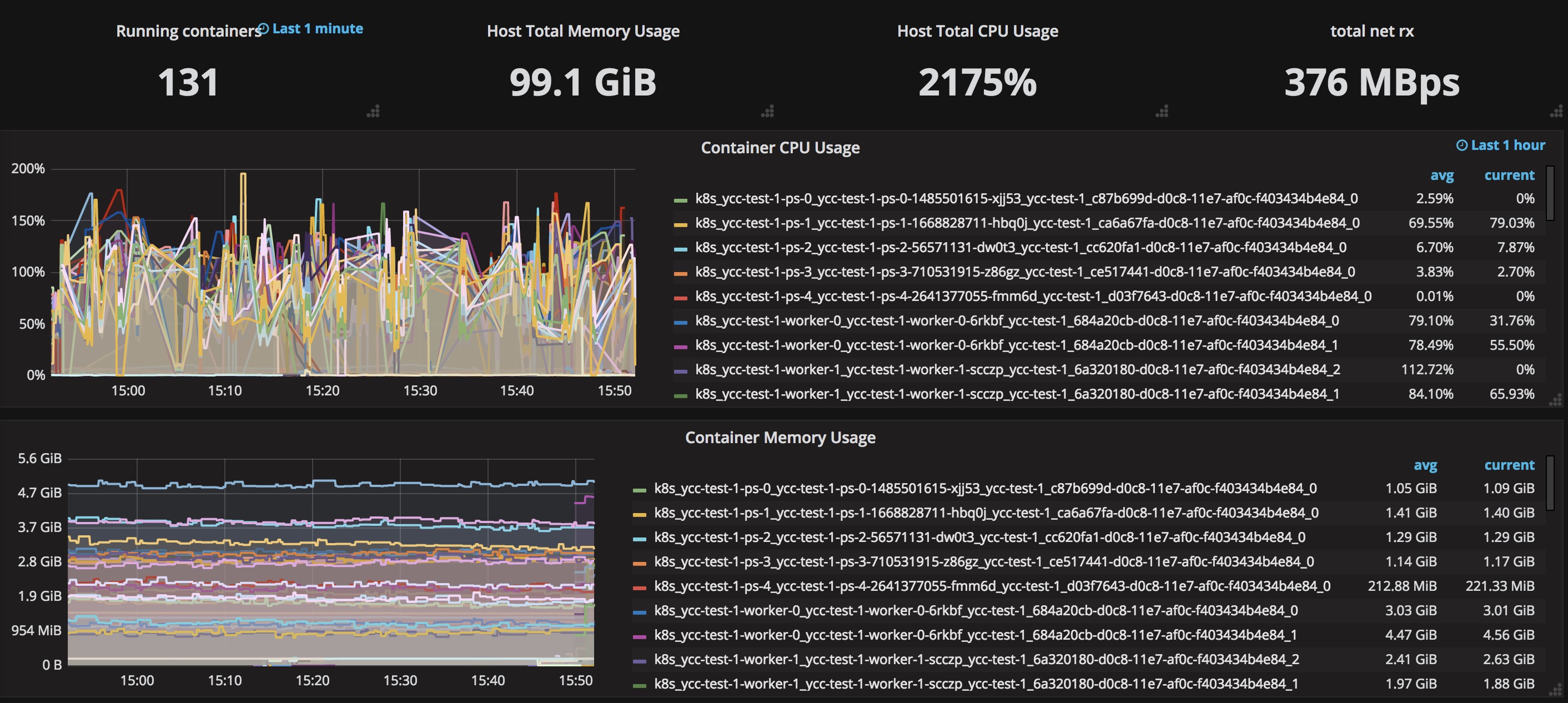
對比兩種不同場景下用例2(5個ps,50個worker)的監控數據,發現如下現象:
兩種場景下,雖然創建了5個ps,但是實際上只有一個ps的負載比較高,其他的ps要么cpu usage在10%以下,要么甚至幾乎為0。
兩種場景下同樣的worker number和ps number,整個tensorflow cluster消耗的cpu和內存差別很小。
分布式tensorflow中,每個worker選擇哪個ps作為自己的參數服務器跟我們如何強制分布ps和worker的布局無關,由分布式tensorflow內部自己控制(跟tf.train.replica_device_setter()設置的strategy有關)。
為什么這個訓練中,多個ps中只有一個ps在工作?是算法只有一個Big參數?如果是,那么默認按照Round-Robin策略只會使用一個ps,就能解釋這個問題了。這需要算法的兄弟進行確認。
如果將Big參數拆分成眾多Small參數,使用RR或LB或Partition策略之一,應該都能利用多個ps進行參數更新明顯提升訓練性能。
通過這次折騰,也不是一無所獲,至少發現我們對于Distributed TensorFlow的內部工作原理還不甚了解,非常有必要深入到源碼進行分析。
“TensorFlow on Kubernetes性能怎么理解”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





