溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
MapReduce源于Google一篇論文,它充分借鑒了“分而治之”的思想,將一個數據處理過程拆分為主要的Map(映射)與Reduce(歸約)兩步。簡單地說,MapReduce就是"任務的分解與結果的匯總"。
MapReduce (MR) 是一個基于磁盤運算的框架,賊慢,慢的主要原因:
1)MR是進程級別的,一個MR任務會創建多個進程(map task和reduce task都是進程),進程的創建和銷毀等過程需要耗很多的時間。?
2)磁盤I/O問題,? MapReduce作業通常都是數據密集型作業,大量的中間結果需要寫到磁盤上并通過網絡進行傳輸,這耗去了大量的時間。?
注:mapreduce 1.x架構有兩個進程:
JobTracker :負責資源管理、作業調度、監控TaskTracker。
TaskTracker:任務的執行者。運行 map task 和 reduce task。
在2.x的時候由yarn取代他們的工作了。
MapReduce工作流程:
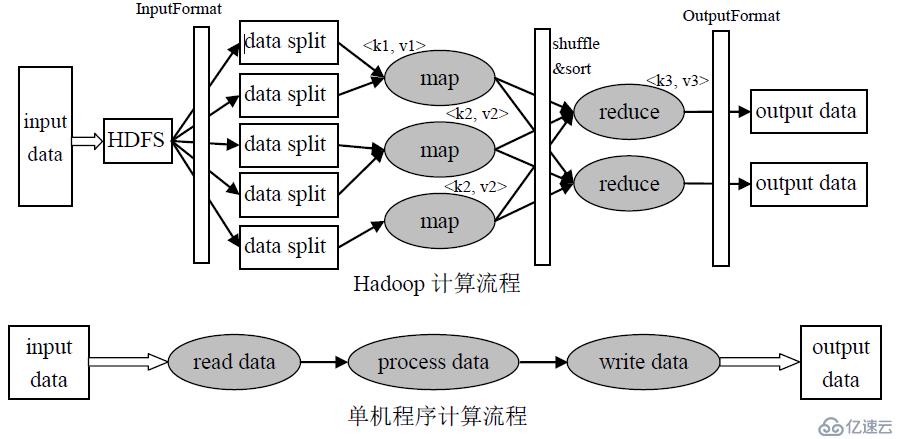
HDFS上的文件—>InputFormat—>Map階段—>shuffle階段(橫跨Mapper和Reducer,在Mapper輸出數據之前和Reducer接收數據之后都有進行)—>Reduce階段 —>OutputFormat —>HDFS:output.txt
InputFormat接口:將輸入數據進行分片(split),輸入分片的大小一般和hdfs的blocksize相同(128M)。
Map階段: Map會讀取輸入分片數據,一個輸入分片(input split)針對一個map任務,進行map邏輯處理(用戶自定義)
Reduce階段:對已排序輸出中的每個鍵調用reduce函數。reduce task 個數通過setNumReduceTasks設定,即mapreduce.job.reduces參數的默認值1。此階段的輸出直接寫到輸出文件系統,一般為hdfs。
MapReduce Shffle詳解
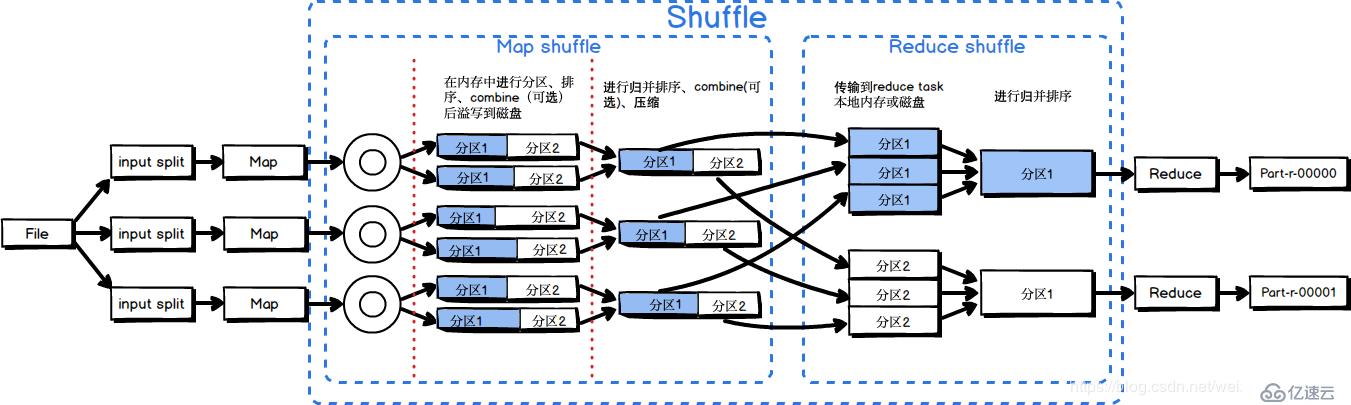
為了確保每個reducer的的輸入都是按鍵排序的,系統執行排序的過程,即將map task的輸出通過一定規則傳給reduce task,這個過程成為shuffle。
Shuffle階段一部分是在map task 中進行的, 這里稱為Map shuffle , 還有一部分是在reduce task 中進行的, 這里稱為Reduce shffle。
Map Shuffle階段
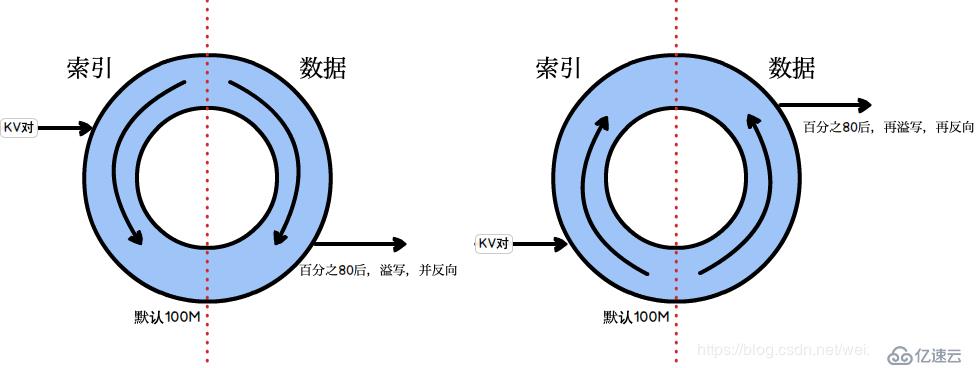
Map在做輸出時候會在內存里開啟一個環形緩沖區,默認大小是100M(參數:mapreduce.task.io.sort.mb),Map中的outputCollect會把輸出的所有kv對收集起來,存到這個環形緩沖區中。
環形緩沖區:本質上是一個首尾相連的數組,這個數組會被一分為二,一邊用來寫索引,一邊用來寫數據。一旦這個環形緩沖區中的內容達到閾值(默認是0.8,參數:mapreduce.map.sort.spill.percent),一個后臺線程就會把內容溢寫(spill)到磁盤上,在這過程中,map輸出并不會停止往緩沖區寫入數據(反向寫,到達閾值后,再反向,以此類推),但如果在此期間緩沖區被寫滿,map會被阻塞直到寫磁盤過程完成。溢寫過程按照輪詢方式將緩沖區的內容寫到mapred.local.dir指定的作業特定子目錄中的目錄中,map任務結束后刪除。
相關概念了解:
Combiner: 本地的reducer,運行combiner使得map輸出結果更緊湊,可以減少寫到磁盤的數據和傳遞給reducer的數據。可通過編程自定義(沒有定義默認沒有)。適用場景:求和、次數等 (做 ‘’+‘’ 法的場景) 【如平均數等場景不適合用】。
Partitioner:分區,按照一定規則,把數據分成不同的區,Partitioner決定map task輸出的數據交由哪個reduce task處理, 分區規則可通過編程自定義,一般自定義一個partition對應一個reduce task,默認是按照key的hashcode進行分區。注:默認reduce task 設置為1,所以不執行partition,執行partition操作時會先判斷reduce task是否大于1 。
Spill:每次溢寫會生成一個溢寫文件(spill file),因此在map任務寫完其最后一個輸出記錄之后,會有多個溢寫文件。在Map 任務完成前,所有的spill file將會進行歸并排序為一個分區且有序的文件。這是一個多路歸并過程,最大歸并路數由默認是10(參數:mapreduce.task.io.sort.factor)。如果有定義combiner,且至少存在3個(參數:mapreduce.map.combine.minspills )溢出文件時,則combiner就會在輸出文件寫到磁盤之前再次運行。當spill 文件歸并完畢后,Map 將刪除所有的臨時spill 文件,通知appmaster, map task已經完成。
Map階段壓縮:在將壓縮map輸出寫到磁盤的過程中對它進行壓縮加快寫磁盤的速度、更加節約時間、減少傳給reducer的數據量。將mapreduce.map.output.compress設置為true(默認為false),就可以啟用這個功能。使用的壓縮庫由參數mapreduce.map.output.compress.codec指定。注:此時建議優先使用效率比較高的壓縮模式。
Reduce Shuffle階段
????Reducer是通過HTTP的方式得到輸出文件的分區。使用netty進行數據傳輸(RPC協議),默認情況下netty的工作線程數是處理器數的2倍。一個reduce task 對應一個分區。
????
????在reduce端獲取所有的map輸出之前,Reduce端的線程會周期性的詢問appmaster 關于map的輸出。App Master是知道map的輸出和host之間的關系。在reduce端獲取所有的map輸出之前,Reduce端的線程會周期性的詢問master 關于map的輸出。Reduce并不會在獲取到map輸出之后就立即刪除hosts,因為reduce有可能運行失敗。相反,是等待appmaster的刪除消息來決定刪除host。
????
????當map任務的完成數占總map任務的0.05(參數:mapreduce.job.reduce.slowstart.completedmaps),reduce任務就開始復制它的輸出,復制階段把Map輸出復制到Reducer的內存或磁盤。復制線程的數量由mapreduce.reduce.shuffle.parallelcopies參數來決定,默認是 5。
????
????如果map輸出相當小,會被復制到reduce任務JVM的內存(緩沖區大小由mapreduce.reduce.shuffle.input.buffer.percent屬性控制,指定用于此用途的堆空間的百分比,默認為0.7),如果緩沖區空間不足,map輸出會被復制到磁盤。一旦內存緩沖區達到閾值(參數:mapreduce.reduce.shuffle.merge.percent,默認0.66)或達到map的輸出閾值(參數:mapreduce.reduce.merge.inmem.threshold,默認1000)則合并后溢寫到磁盤中。如果指定combiner,則在合并期間運行它已降低寫入磁盤的數據量。隨著磁盤上副本的增多,后臺線程會將它們合并為更大的,排序好的文件。注:為了合并,壓縮的map輸出都必須在內存中解壓縮。
????復制完所有的map輸出后,reduce任務進入歸并排序階段,這個階段將合并map的輸出,維持其順序排序。這是循環進行的。目標是合并最小數據量的文件以便最后一趟剛好滿足合并系數(參數:mapreduce.task.io.sort.factor,默認10)。
????
????因此,如果有40個文件(包括磁盤和內存),不會在四趟中每趟合并10個文件而得到4個文件,再將4個文件合并到reduce。而是第一趟只合并4個文件,隨后的三塘合并10個文件。最后一趟中,4個已經合并的文件和剩余的6個文件合計十個文件直接合并到reduce。
????
????這并沒有改變合并的次數,它只是一個優化措施,盡量減少寫到磁盤的數據量。因為最后一趟總是直接合并到reduce,沒有磁盤往返。
????至此,Shuffle階段結束。
Shuffle總結
????1)map task收集map()方法輸出的kv對,放到內存環形緩沖區中
????2)從內存環形緩沖區不斷將文件經過分區、排序、combine(可選)溢寫(spill)到本地磁盤
????3)多個溢出文件會歸并排序成大的spill file
????4)reduce task根據自己的分區號,去各個map task機器上取相應的結果分區數據
????5)reduce task會取到同一個分區的來自不同maptask的結果文件,reduce task會將這些文件再進行歸并排序
????6)合并成大文件后,shuffle過程結束
MapReduce調優
輸入階段:處理小文件問題:
Map階段:
? ? 1)減少溢寫(spill)次數。
? ? 2)減少合并(merge)次數。
? ? 3)不影響業務邏輯前提下,設置combine。
? ? 4)啟用壓縮。
Reduce階段:
? ? 1)合理設置map和reduce數。
? ? 2)合理設置map、reduce共存。
? ? 3)規避使用reduce:因為reduce在用于連接數據集的時候將會產生大量的網絡消耗。
? ? 4)合理設置reduce端的buffer:默認情況下,數據達到一個閾值的時候,buffer中的數據就會寫入磁盤,然后reduce會從磁盤中獲得所有的數據。也就是說,buffer和reduce是沒有直接關聯的,中間多個一個寫磁盤->讀磁盤的過程,既然有這個弊端,那么就可以通過參數來配置,使得buffer中的一部分數據可以直接輸送到reduce,從而減少IO開銷。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





