溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天小編給大家分享一下怎么用Python送愛心的相關知識點,內容詳細,邏輯清晰,相信大部分人都還太了解這方面的知識,所以分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后有所收獲,下面我們一起來了解一下吧。
有了想法之后就開始行動了,自然最先想到的就是用 Python 了,大體思路就是把微博數據爬下來,數據經過清洗加工后再進行分詞處理,處理后的數據交給詞云工具,配合科學計算工具和繪圖工具制作成圖像出來,涉及到的工具包有:
requests 用于網絡請求爬取微博數據,結巴分詞進行中文分詞處理,詞云處理庫 wordcloud,圖片處理庫 Pillow,科學計算工具 NumPy ,類似于 MATLAB 的 2D 繪圖庫 Matplotlib
安裝這些工具包時,不同系統平臺有可能出現不一樣的錯誤,wordcloud,requests,jieba 都可以通過普通的 pip 方式在線安裝,
pip install wordcloud pip install requests pip install jieba
在Windows 平臺安裝 Pillow,NumPy,Matplotlib 直接用 pip 在線安裝會出現各種問題,推薦的一種方式是在一個叫 Python Extension Packages for Windows 1 的第三方平臺下載 相應的 .whl 文件安裝。可以根據自己的系統環境選擇下載安裝 cp27 對應 python2.7,amd64 對應 64 位系統。下載到本地后進行安裝
pip install Pillow-4.0.0-cp27-cp27m-win_amd64.whl
pip install scipy-0.18.0-cp27-cp27m-win_amd64.whl
pip install numpy-1.11.3+mkl-cp27-cp27m-win_amd64.whl
pip install matplotlib-1.5.3-cp27-cp27m-win_amd64.whl其他平臺可根據錯誤提示 Google 解決。或者直接基于 Anaconda 開發,它是 Python 的一個分支,內置了大量科學計算、機器學習的模塊 。
新浪微博官方提供的 API 是個渣渣,只能獲取用戶最新發布的5條數據,退而求其次,使用爬蟲去抓取數據,抓取前先評估難度,看看是否有人寫好了,在GitHub逛了一圈,基本沒有滿足需求的。倒是給我提供了一些思路,于是決定自己寫爬蟲。使用 http://m.weibo.cn/ 移動端網址去爬取數據。發現接口 http://m.weibo.cn/index/my?format=cards&page=1 可以分頁獲取微博數據,而且返回的數據是 json 格式,這樣就省事很多了,不過該接口需要登錄后的 cookies 信息,登錄自己的帳號就可以通過 Chrome 瀏覽器 找到 Cookies 信息。
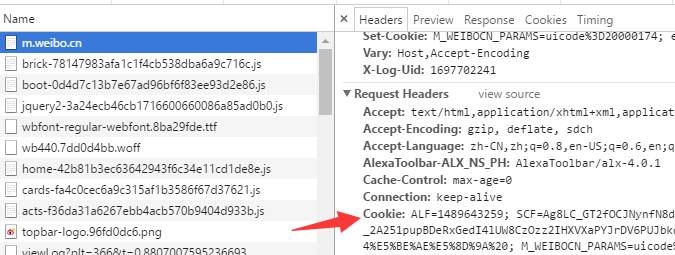
實現代碼:
def fetch_weibo():
api = "http://m.weibo.cn/index/my?format=cards&page=%s"
for i in range(1, 102):
response = requests.get(url=api % i, cookies=cookies)
data = response.json()[0]
groups = data.get("card_group") or []
for group in groups:
text = group.get("mblog").get("text")
text = text.encode("utf-8")
text = cleanring(text).strip()
yield text查看微博的總頁數是101,考慮到一次性返回一個列表對象太費內存,函數用 yield 返回一個生成器,此外還要對文本進行數據清洗,例如去除標點符號,HTML 標簽,“轉發微博”這樣的字樣。
數據獲取之后,我們要把它離線保存起來,方便下次重復使用,避免重復地去爬取。使用 csv 格式保存到 weibo.csv 文件中,以便下一步使用。數據保存到 csv 文件中打開的時候可能為亂碼,沒關系,用 notepad++查看不是亂碼。
def write_csv(texts):
with codecs.open('weibo.csv', 'w') as f:
writer = csv.DictWriter(f, fieldnames=["text"])
writer.writeheader()
for text in texts:
writer.writerow({"text": text})
def read_csv():
with codecs.open('weibo.csv', 'r') as f:
reader = csv.DictReader(f)
for row in reader:
yield row['text']從 weibo.csv 文件中讀出來的每一條微博進行分詞處理后再交給 wordcloud 生成詞云。結巴分詞適用于大部分中文使用場景,使用停止詞庫 stopwords.txt 把無用的信息(比如:的,那么,因為等)過濾掉。
def word_segment(texts):
jieba.analyse.set_stop_words("stopwords.txt")
for text in texts:
tags = jieba.analyse.extract_tags(text, topK=20)
yield " ".join(tags)數據分詞處理后,就可以給 wordcloud 處理了,wordcloud 根據數據里面的各個詞出現的頻率、權重按比列顯示關鍵字的字體大小。生成方形的圖像,如圖:

是的,生成的圖片毫無美感,畢竟是要送人的,要拿得出手才好炫耀對吧,那么我們找一張富有藝術感的圖片作為模版,臨摹出一張漂亮的圖出來。我在網上搜到一張“心”型圖:

生成圖片代碼:
def generate_img(texts):
data = " ".join(text for text in texts)
mask_img = imread('./heart-mask.jpg', flatten=True)
wordcloud = WordCloud(
font_path='msyh.ttc',
background_color='white',
mask=mask_img
).generate(data)
plt.imshow(wordcloud)
plt.axis('off')
plt.savefig('./heart.jpg', dpi=600)需要注意的是處理時,需要給 matplotlib 指定中文字體,否則會顯示亂碼,找到字體文件夾:C:\Windows\Fonts\Microsoft YaHei UI復制該字體,拷貝到 matplotlib 安裝目錄:C:\Python27\Lib\site-packages\matplotlib\mpl-data\fonts\ttf 下
差不多就這樣。

以上就是“怎么用Python送愛心”這篇文章的所有內容,感謝各位的閱讀!相信大家閱讀完這篇文章都有很大的收獲,小編每天都會為大家更新不同的知識,如果還想學習更多的知識,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





