溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
大數據開發過程中的5個學習通用步驟是什么,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
大數據的開發過程,如圖1-1所示。
圖 1-1大數據開發通用步驟圖
上圖只是一個簡化后的步驟和流程,實際開發中,有的步驟可能不需要,有的還需要增加步驟,有的流程可能更復雜,因具體情況而定。
下面以Google搜索引擎為例,來說明以上步驟。
如果你想要學好大數據最好加入一個好的學習環境,可以來這個Q群529867072 這樣大家學習的話就比較方便,還能夠共同交流和分享資料
大數據采集
Google的數據來源于互聯網上的網頁,它們由Google Spider(蜘蛛、爬蟲、機器人)來抓取,抓取的原理也很簡單,就是模擬我們人的行為,來訪問各個網頁,然后保存網頁內容。
Google Spider是一個程序,運行在全球各地的Google服務器之中,Spider們非常勤奮,日夜不停地工作。點擊領取免費資料及課
2008年Google數據表明,它們每天都會訪問大約200億個網頁,而在總量上,它們追蹤著300億個左右的獨立URL鏈接。
可以說,只要是互聯網上的網站,只要沒有在robots.txt文件禁止Spider訪問的話,其網頁基本上都會在很短的時間內,被抓取到Google的服務器上。
全球的網頁,這是典型的大數據。因此,Google Spider所做的就是典型的大數據采集工作。
大數據預處理
Google Spider爬取的網頁,無論是從格式還是結構等,都不統一,為了便于后續處理,需要先做一些處理,例如,在存儲之前,先轉碼,使用統一的格式對網頁進行編碼,這些工作就是預處理。
大數據存儲
網頁經過預處理后,就可以存儲到Google的服務器上。
2008年,Google已經索引了全世界1萬億個網頁,到2014年,這個數字變成了30萬億個。
為了減少開銷,節約空間,Google將多個網頁文件合并成一個大文件,文件大小通常在1GB以上。
這還是15年以前的數字,那時,主流臺式機硬盤也就是60GB左右,1GB的文件在當時可以說是大文件了。
為了實現這些大文件高效、可靠、低成本存儲,Google發明了一種構建在普通商業機器之上的分布式文件系統:Google File System,縮寫為GFS,用來存儲文件(又稱之為非結構化數據)。
網頁文件存儲下來后,就可以對這些網頁進行處理了,例如統計每個網頁出現的單詞以及次數,統計每個網頁的外鏈等等。
這些被統計的信息,就成為了數據庫表中的一個屬性,每個網頁最終就會成為數據庫表中的一條或若干條記錄。
由于Google存儲的網頁太多,30萬億個以上,因此,這個數據庫表也是超級龐大的,傳統的數據庫,像Oracle等,根本無法處理這么大的數據,因此Google基于GFS,發明了一種存儲海量結構化數據(數據庫表)的分布式系統Bigtable。
上述兩個系統(GFS和Bigtable)并未開源,Google僅通過文章的形式,描述了它們的設計思想。
所幸的是,基于Google的這些設計思想,時至今日,已經出現了不少開源海量數據分布式文件系統,如HDFS等,也出現了許多開源海量結構化數據的分布式存儲系統,如HBase、Cassandra等,它們分別用于不同類型大數據的存儲。
總之,如果采集過來的大數據需要存儲,要先判斷數據類型,再確定存儲方案選型;
如果不需要存儲(如有的流數據不需要存儲,直接處理),則直接跳過此步驟,進行處理。
在這里還是要推薦下我自己建的大數據學習交流群:529867072,群里都是學大數據開發的,如果你正在學習大數據 ,小編歡迎你加入,大家都是軟件開發黨,不定期分享干貨(只有大數據軟件開發相關的),包括我自己整理的一份最新的大數據進階資料和高級開發教程,歡迎進階中和進想深入大數據的小伙伴加入。4. 大數據處理
網頁存儲后,就可以對存儲的數據進行處理了,對于搜索引擎來說,主要有3步:
1)單詞統計:統計網頁中每個單詞出現的次數;
2)倒排索引:統計每個單詞所在的網頁URL(Uniform Resource Locator統一資源定位符,俗稱網頁網址)以及次數;
3)計算網頁級別:根據特定的排序算法,如PageRank,來計算每個網頁的級別,越重要的網頁,級別越高,以此決定網頁在搜索返回結果中的排序位置。
例如,當用戶在搜索框輸入關鍵詞“足球”后,搜索引擎會查找倒排索引表,得到“足球”這個關鍵詞在哪些網頁(URL)中出現,然后,根據這些網頁的級別進行排序,將級別最高的網頁排在最前面,返回給用戶,這就是點擊“搜索”后,看到的最終結果。
大數據處理時,往往需要從存儲系統讀取數據,處理完畢后,其結果也往往需要輸出到存儲。因此,大數據處理階段和存儲系統的交互非常頻繁。
大數據可視化
大數據可視化是將數據以圖形的方式展現出來,與純粹的數字表示相比,圖形方式更為直觀,更容易發現數據之間的規律。
例如,Google Analytics是一個網站流量分析工具,它統計每個用戶使用搜索引擎訪問網站的數據,然后得到每個網站的流量信息,包括網站每天的訪問次數,訪問量最多的頁面、用戶的平均停留時間、回訪率等,所有數據都以圖形的方式,直觀地顯示出來,如圖1-2所示
圖1-2 Google網站訪問量分析圖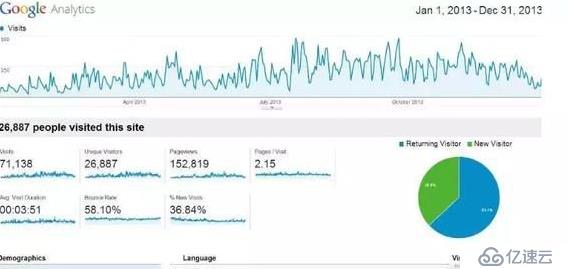
關于大數據開發過程中的5個學習通用步驟是什么問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





