溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關storm如何提高運行速,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
(1)要將系統中的算法調優。有可能一個算法浪費了一小部分時間,但由于數據量可能比較大,以至于整體上1秒的時間內可能浪費大量的時間。因此,算法的設計還是比較重要的。
(2)其次,就是調整系統中占用資源比較多、運算速度比較慢的那些spout和bolt。在進行topology設計時需要設計好每個bolt的并行度。對于運行速度比較慢的bolt,需要調大他們的并行度,是得更多的資源用到這些計算上面來。這里,bolt運行的快慢是可以從ui界面中看到的,如下圖:
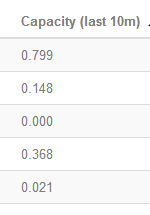
如上圖,其中,capacity表示一種容量,其實就是占用的資源的百分比。比如,0.799就表示占用了79.9%的分配給這個bolt的資源。這個數值越大,則表示的處理起來速度越慢,則更要加大它的并行度。
(3)然后就是設置acker的數量。acker是在bolt成功處理后,進行ack調用的線程(還是進程,我忘記了)。當數據量比較大時,需要使用這個線程的次數就比較多,因此有可能這個線程就是制約處理速度的因素。因此,可以適當調大acker的數量,用于進行ack的調用。系統中,如果不設置的話,acker的數量默認為1;可以通過以下語句在topology中進行設定:
conf.put(Config.TOPOLOGY_ACKER_EXECUTORS, 10);//設置acker的數量
(4)當集群中數據量比較大時,則最好能設置spout中的等待處理的數據量的大小。當集群中等待的數據量比較大時,也就是數據發送比較快,但是處理太慢。這個時候應該阻止spout的發送,否則可能會導致系統隊列爆掉。因此,設置以下:
conf.put(Config.TOPOLOGY_MAX_SPOUT_PENDING, 10000);//設置一個spout task上面最多有多少個沒有處理的tuple(沒有ack/failed)回復,以防止tuple隊列爆掉
(5)在Spout調用nextTuple方法時,如果沒有emit tuple,那么默認需要休眠1ms,這個具體的策略是可配置的,因此可以根據自己的具體場景,進行設置,以達到合理利用cpu資源。
topology.spout.wait.strategy "backtype.storm.spout.SleepSpoutWaitStrategy" topology.sleep.spout.wait.strategy.time.ms 1
關于“storm如何提高運行速”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





