溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了openstack出錯怎么辦,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
控制節點:
查看云主機: nova list
詳細查看單個云主機: nova show [name]
查看各個節點狀態:nova-manage service list
計算節點:
查看節點狀態: service openstack-nova-compute status
重啟節點: service openstack-nova-compute restart
1.
虛擬機建立不起來的時候,有可能是,計算節點上的openstack服務down掉了,在控制節點上重啟openstack服務即可。
[root@controlNode01 network-scripts]# nova service-list
| 6 | nova-compute | computeNode01 | nova | enabled | down | 2016-02-26T06:47:45.000000 | None |
[root@controlNode01 network-scripts(keystone_ALUvRAN)]#openstack-service restart
2.
虛擬機刪掉了,但是volume還顯示in-use狀態,需要從數據庫里面重置volume的狀態。
[root@controlNode01]# mysql cinder
MariaDB [cinder]> SELECT id,status,attach_status,mountpoint,instance_uuid from volumes;
MariaDB [cinder]> UPDATE volumes SET status="available", attach_status="detached", mountpoint=NULL, instance_uuid=NULL WHERE id="336d3e1c-298e-437d-a469-c2872cbe1a3a";
3.
有時候碰到硬盤太大,比如需要創建80G的虛擬機,則會創建失敗,需要修改nova里面的vif超時參數。
vif_plugging_timeout=10
vif_plugging_is_fatal=False
4.
在運行“/etc/init.d/network restart”命令時,出現錯誤“Job for network.service failed. See 'systemctl status network.service' and 'journalctl -xn' for deta”,運行“cat /var/log/messages | grep network”命令查看日志中出現的與network相關的信息
我出現的錯誤,是由于外網的物理地址與eth0不一樣。后來將pub網指向eth0即可
7.14.2016
問題1:
控制節點與計算節點之間的時間不同步:
nova-manage service list檢測服務狀態原理:
最近更新時間,或者第一次創建時間與當前時間間隔少于CONF.service_down_time(60秒),則認為服務alive
從這里也可以得知為什么控制節點和計算節點的時間要一致。
http://blog.csdn.net/tantexian/article/details/39204993
問題 2:
Nova scheduler :Host has more disk space than database expected
原理:
宿主機 RAM 和 DISK 的使用率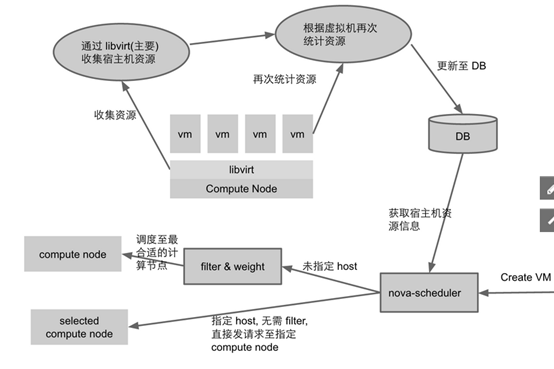 往往要小于虛擬機理論使用的 RAM 和 DISK,在剩余資源充足的條件下,libvirt 將成功創建虛擬機。
往往要小于虛擬機理論使用的 RAM 和 DISK,在剩余資源充足的條件下,libvirt 將成功創建虛擬機。
隨想:內存和磁盤超配雖然能提供更多數量的虛擬機,當該宿主機上大量虛擬機的負載都很高時,輕著影響虛擬機性能,重則引起 qemu-kvm 相關進程被殺,即虛擬機被關機。因此對于線上穩定性要求高的業務,建議不要超配 RAM 和 DISK,但可適當超配 CPU。建議這幾個參數設置為:
CPU: CONF.cpu_allocation_ratio = 4
RAM: CONF.ram_allocation_ratio = 1.0
DISK: CONF.disk_allocation_ratio = 1.0
RAM-Reserve: CONF.reserved_host_memory_mb = 2048
DISK-Reserve: CONF.reserved_host_disk_mb = 20480
http://blog.csdn.net/wsfdl/article/details/45418727
問題 3:
在nova-all.log日志中發現MessagingTimeout: Timed out waiting for a reply to message ID問題
日志中時不時出現”MessagingTimeout: Timed out waiting for a reply to message“, 來點絕的, 直接修改nova.conf文件,添加:
[conductor]
use_local=true
如果計算節點宕機了,但沒有在nova里將這個host disable掉,在 service_down_time and report_interval setting時間內nova-schedule會誤認為這個host仍然是alive的,從而出問題了。 另外也可能是olso的bug, https://bugs.launchpad.net/oslo.messaging/+bug/1338732
或者去掉RetryFilter,
scheduler_default_filters=AvailabilityZoneFilter,RamFilter,ComputeFilter,ComputeCapabilitiesFilter,Image
在neutron openswitch-agent .log 中發現
MessagingTimeout: Timed out waiting for a reply to message ID
neutron在同步路由信息時,會從neutron-server獲取所有router的信息,這個過程會比較長(130s左右,和網絡資源的多少有關系),而 在/etc/neutron/neutron.conf中會有一個配置項“rpc_response_timeout”,它用來配置RPC的超時時間,默認為60s,所以導致超時異常.解決方法為設置rpc_response_timeout=180.
延時是解決各種問題的大招啊。。。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“openstack出錯怎么辦”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





