溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家分析了Apache Zeppelin Notebook和R的示例分析的相關知識點,內容詳細易懂,操作細節合理,具有一定參考價值。如果感興趣的話,不妨跟著跟隨小編一起來看看,下面跟著小編一起深入學習“Apache Zeppelin Notebook和R的示例分析”的知識吧。
小編目的是幫助您開始使用 Apache Zeppelin Notebook,它可以滿足您用R做數據科學的需求。Zeppelin 是一個提供交互數據分析且基于Web的筆記本。方便你做出可數據驅動的、可交互且可協作的精美文檔,并且支持多種語言,包括 Scala(使用 Apache Spark)、Python(Apache Spark)、SparkSQL、 Hive、 Markdown、Shell等等。而且Zeppelin支持自己重寫各種語言的插件,是很方便擴展的。
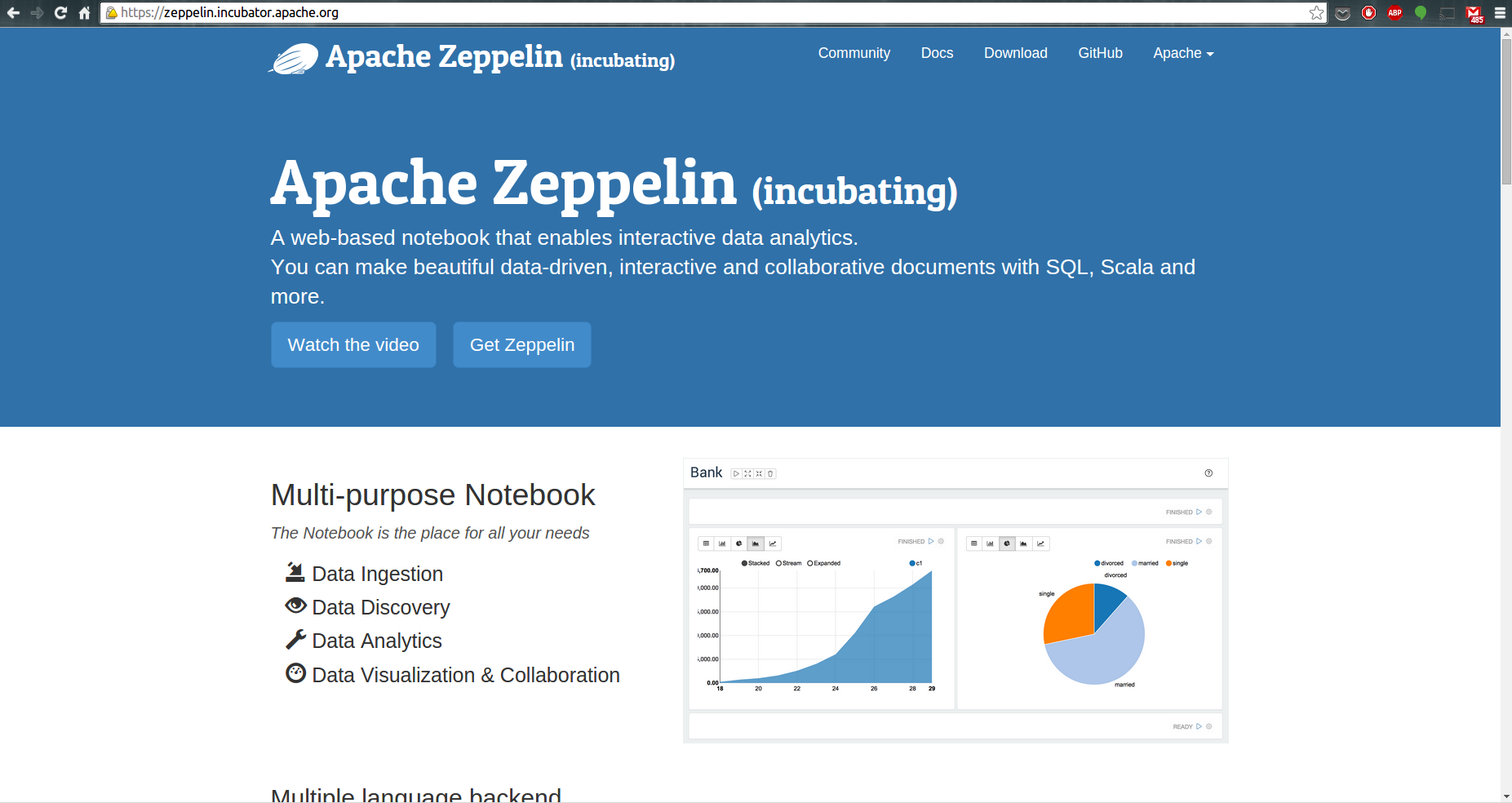
然而,最新的官方版本是0.5.0,還不支持R編程語言。幸運的是,NFLabs公司做了個開源項目,讓我提供了一個R的編譯器。這個編譯器是讓用戶可以使用自定義的語言做為數據處理后端的一個 Zeppelin 插件。例如在 Zeppelin 使用scala代碼,您需要一個 Spark編譯器。所以,如果你像我一樣有足夠的耐心將R集成到Zeppelin中, 這個教程將告訴你怎樣從源碼開始配置 Zeppelin和R。
我們將通過Bash shell在Linux上安裝Zeppelin。如果您使用的是Windows操作系統,我建議您安裝和使用Cygwin終端(它提供功能類似于Windows上的Linux發行版)。
確保 Java 1.7 和 Maven 3.2.x 是已經安裝并且配置到環境變量中。
去這github分支下載源代碼,將這個鏈接復制并粘貼到你的瀏覽器:https://github.com/elbamos/incubator-zeppelin/tree/rinterpreter
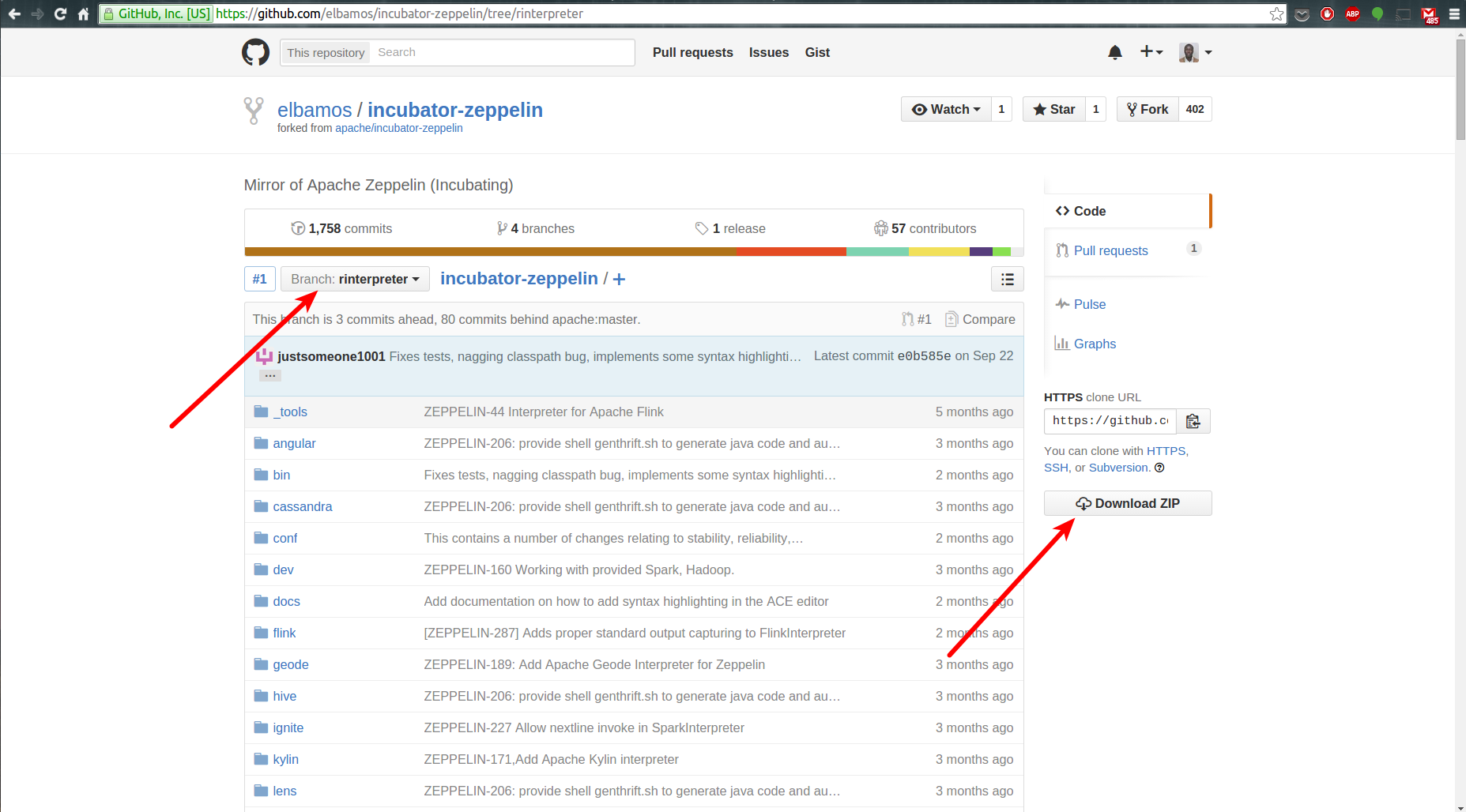
在我的例子中我已經下載并解壓文件夾在我的桌面
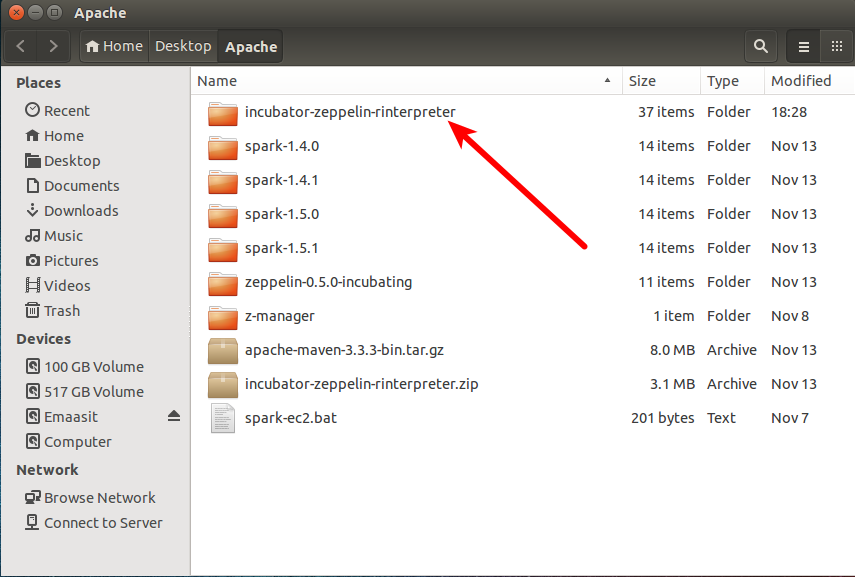
假設你是安裝在單機,打開你的Terminal,運行下面的代碼。如果你是安裝在一個集群,會稍微復雜一點,具體步驟 Zeppelin 的文檔中找到。
$ cd Desktop/Apache/incubator-zeppelin-rinterpreter $ mvn clean package -DskipTests

這將需要約16分鐘構建Zeppelin、Spark,所有引擎包括R,markdown,shell,hive等。(見下圖)。
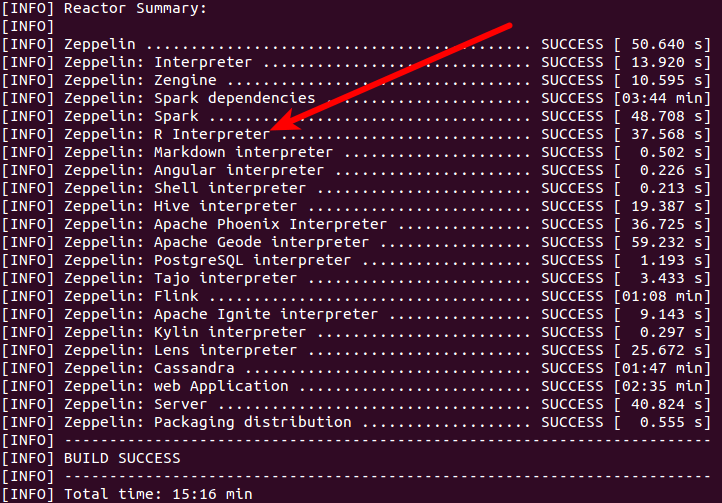
運行以下命令啟動Zeppelin:
$ ./bin/zeppelin-daemon.sh start
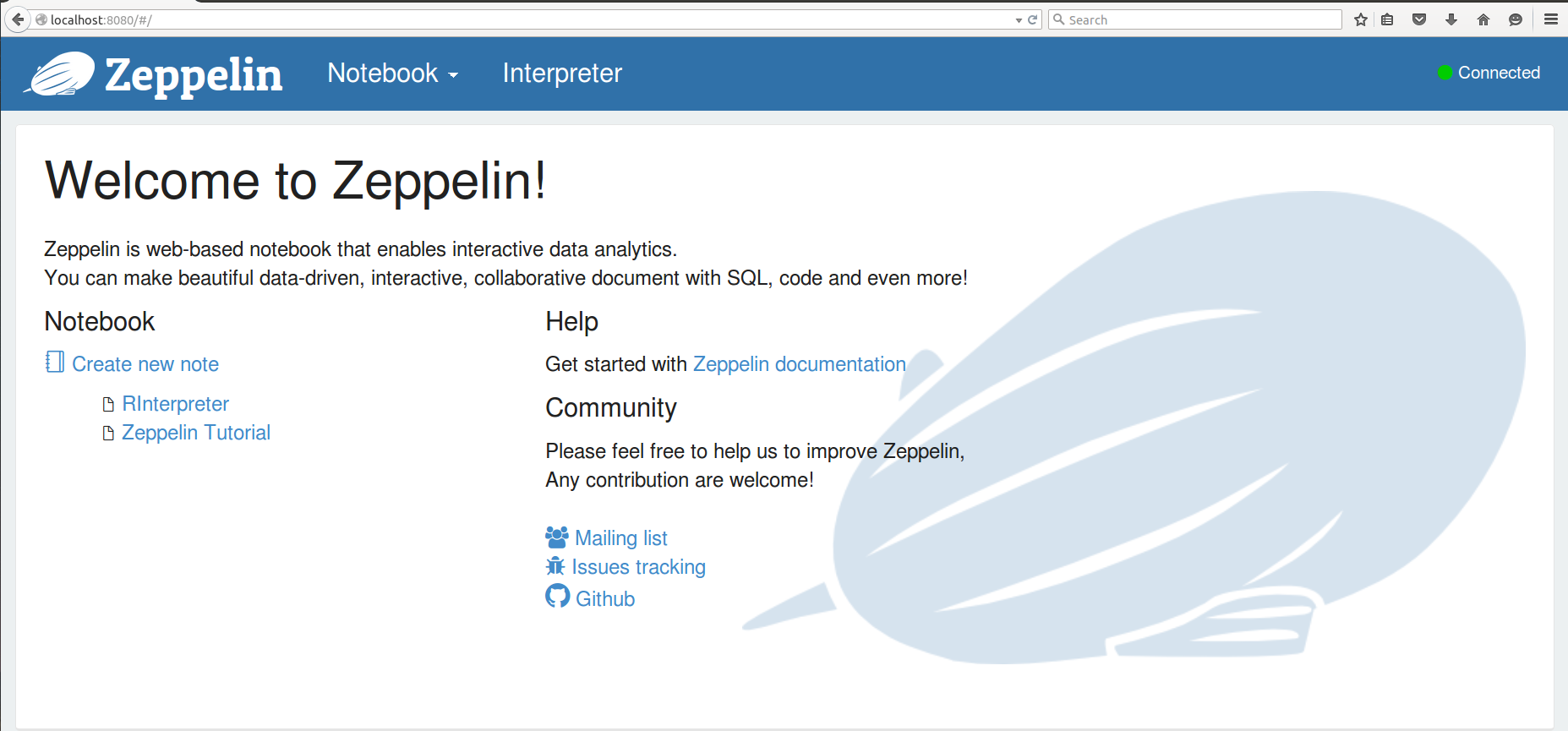
 打開web瀏覽器,訪問http://localhost:8080。此時,您已經準備好開始在 Zeppelin 用代碼創建交互筆記本。
打開web瀏覽器,訪問http://localhost:8080。此時,您已經準備好開始在 Zeppelin 用代碼創建交互筆記本。
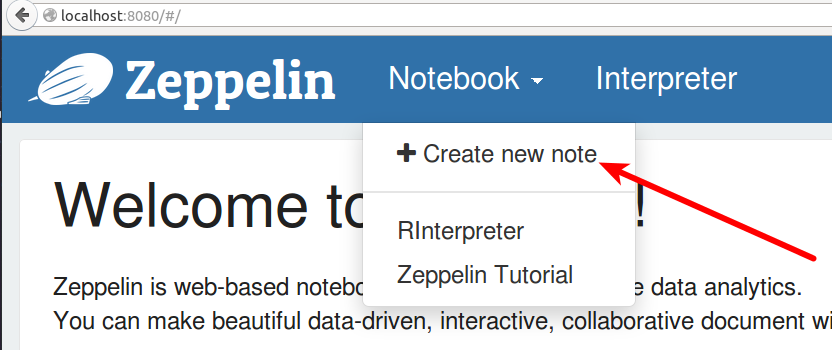
單擊下拉箭頭旁邊的“筆記本”頁面,點擊“創建新報告”。
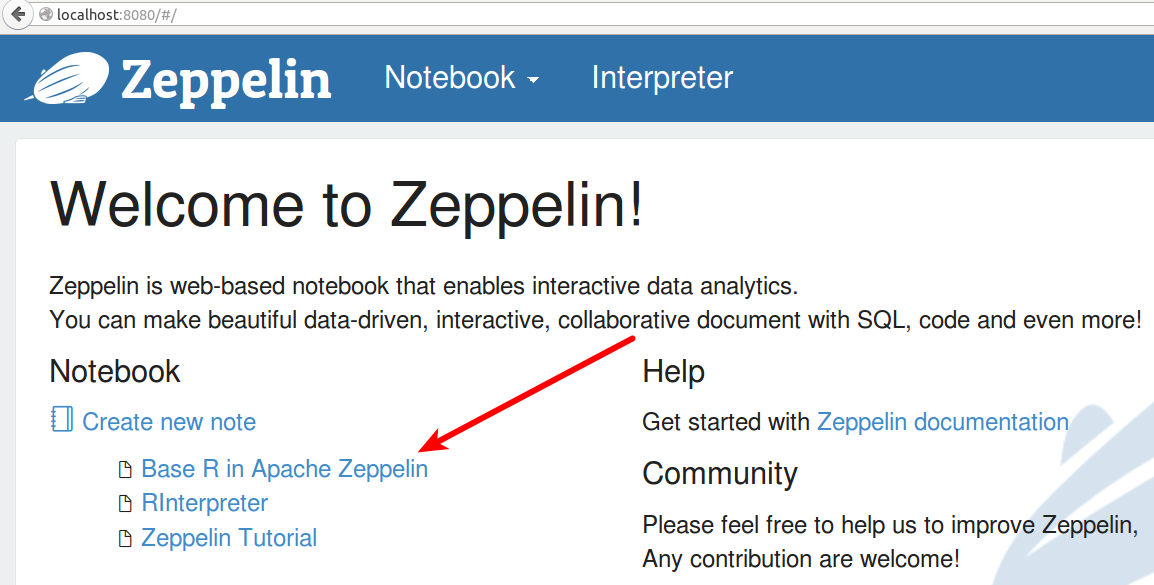
給你的筆記本命名或您可以使用指定的缺省名稱。我命名為“Base R in Apache Zeppelin”。
如下圖所示,調用R可以用“%spark.r”或“%spark.knitr”標簽。首先讓我們用 markdown 寫一些介紹。

根據我們可能需要我們的分析,現在讓我們來安裝一些包。
我們將使用“flights”數據集顯示2013年離開紐約的航班,現在讓我們讀取數據集。
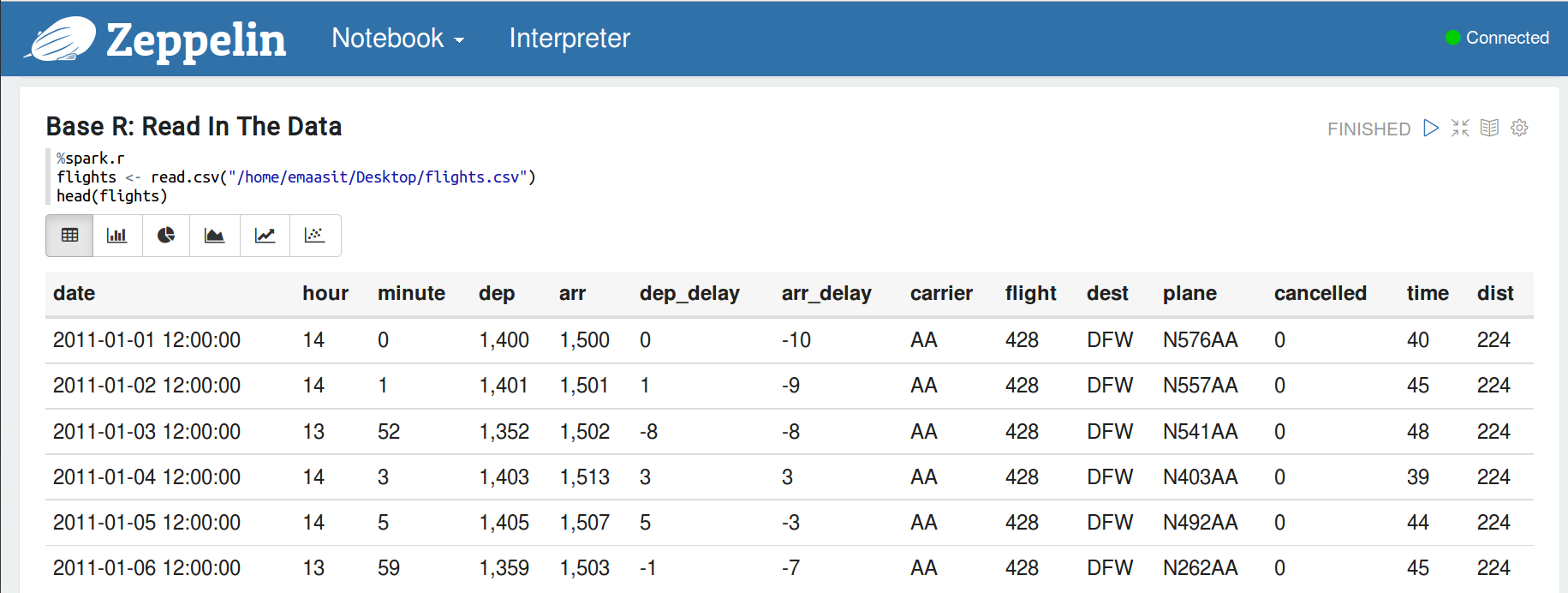
現在,讓我們使用dplyr(用管道符)做一些數據操作。
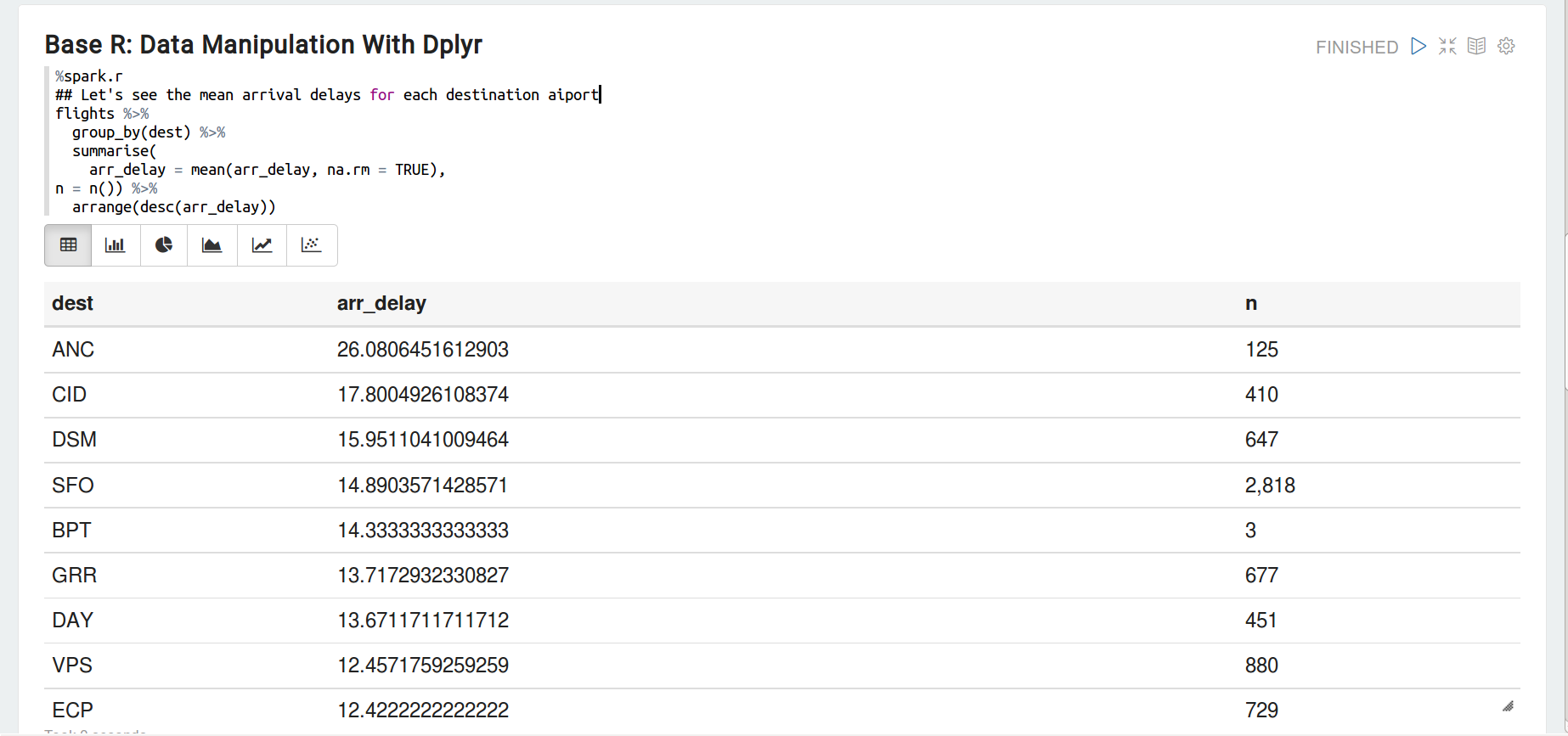
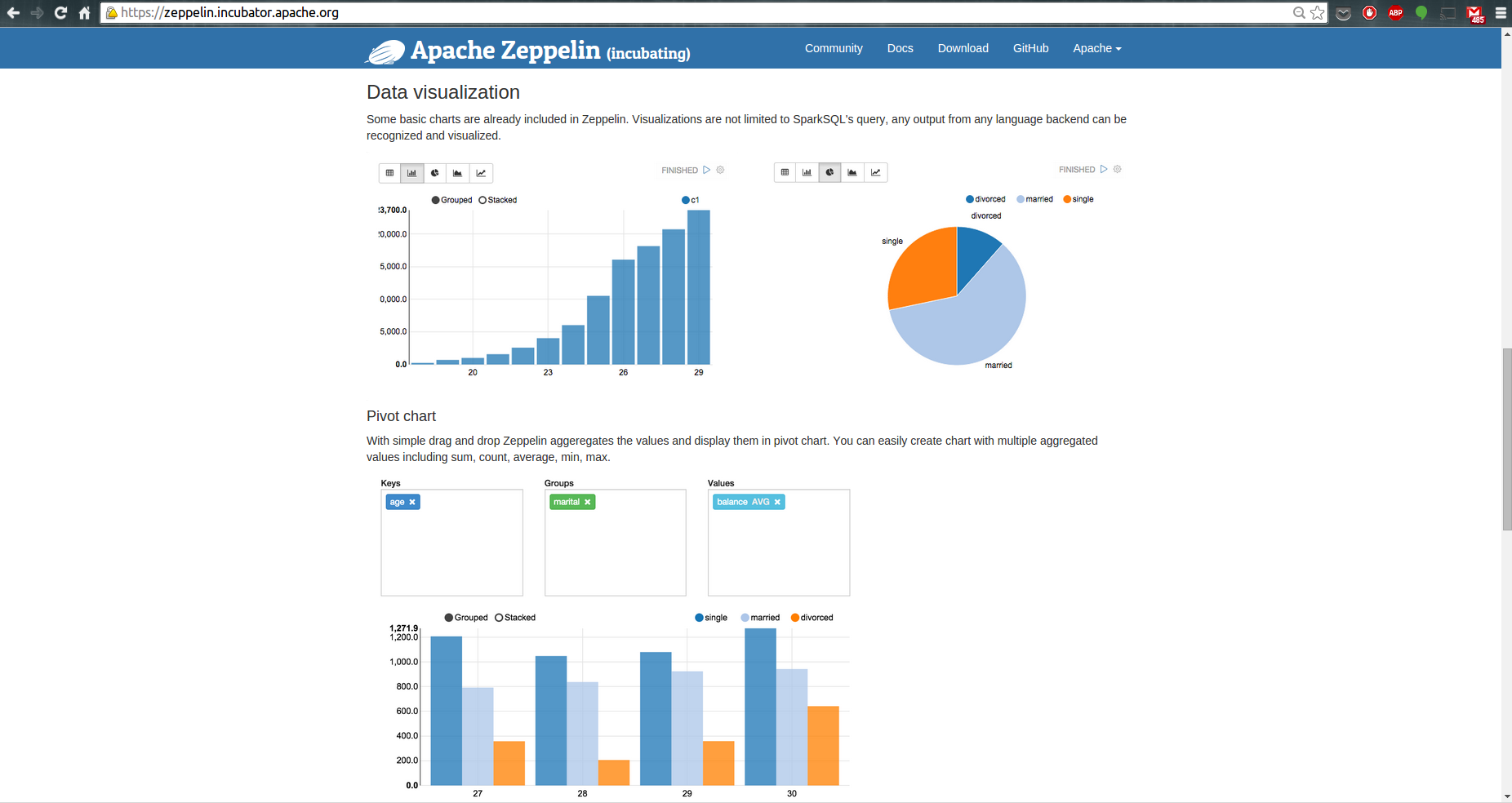
您還可以使用條形圖和餅圖來可視化一些描述性統計數據。
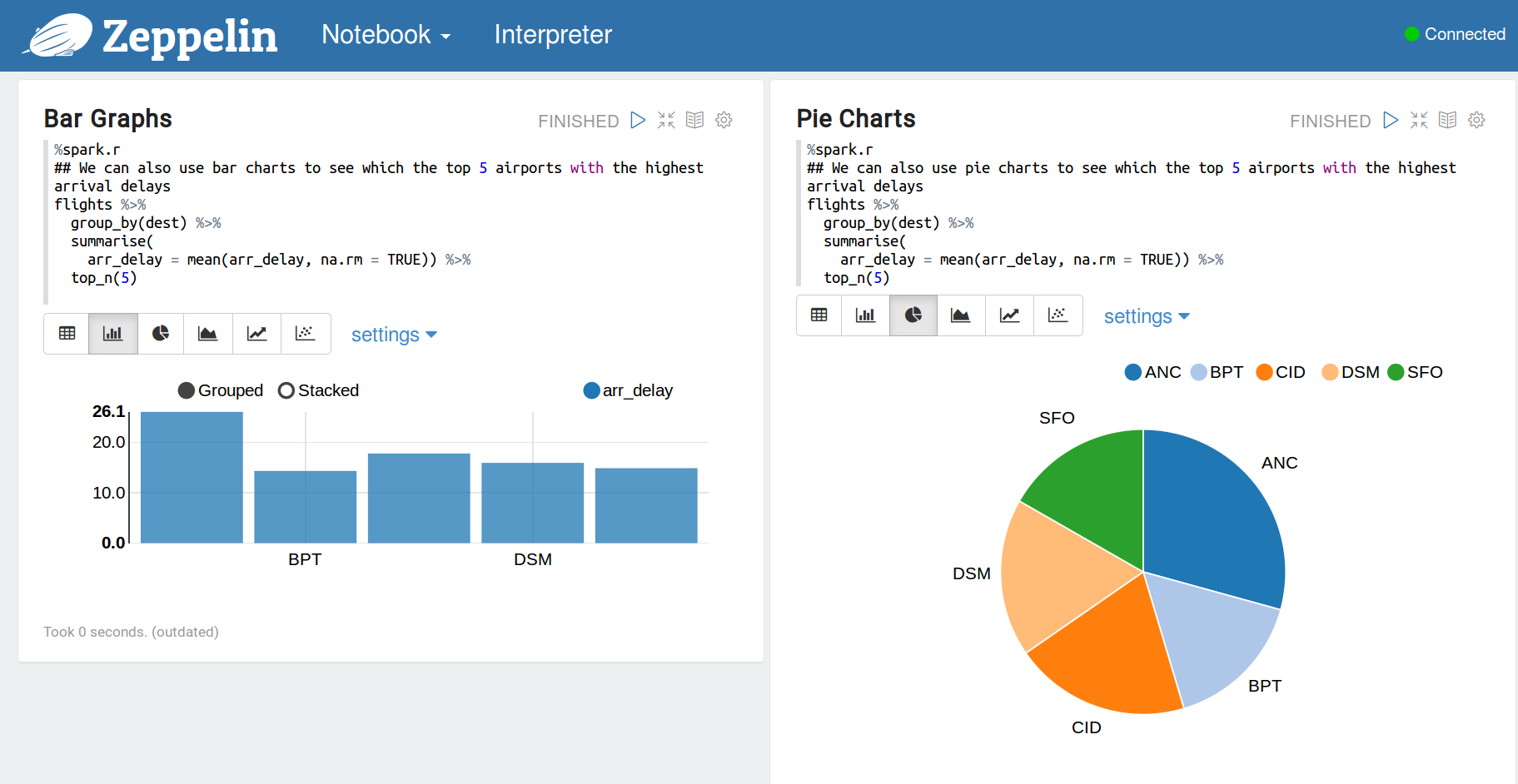
現在,讓我們與ggplot2共舞。
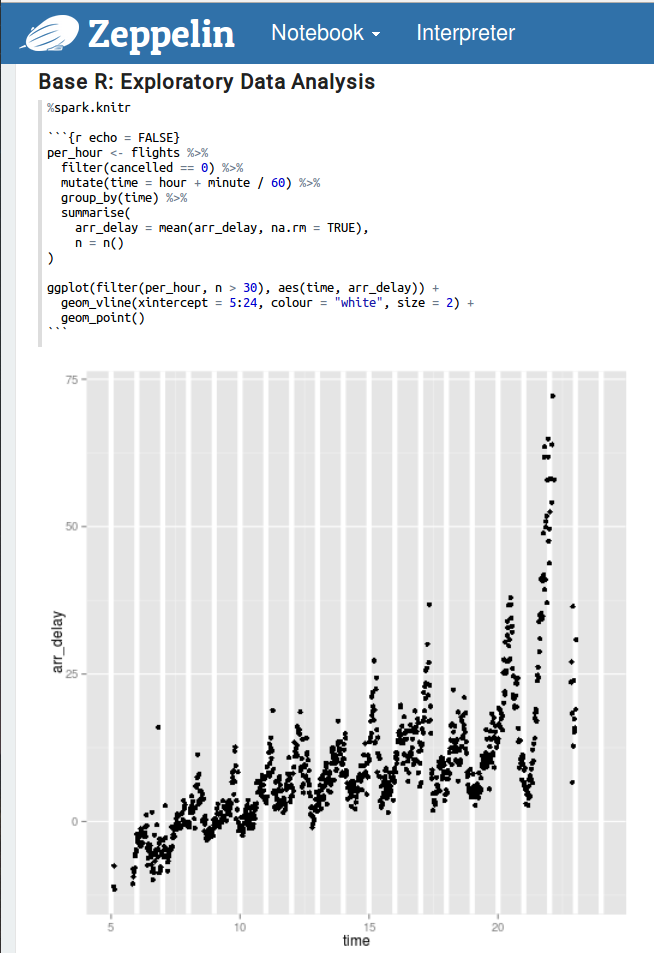
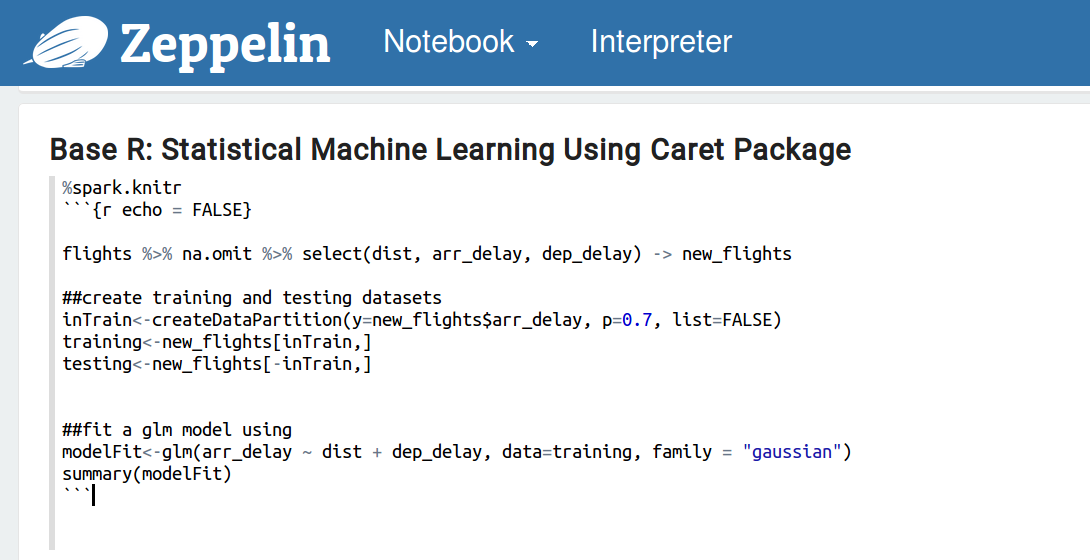
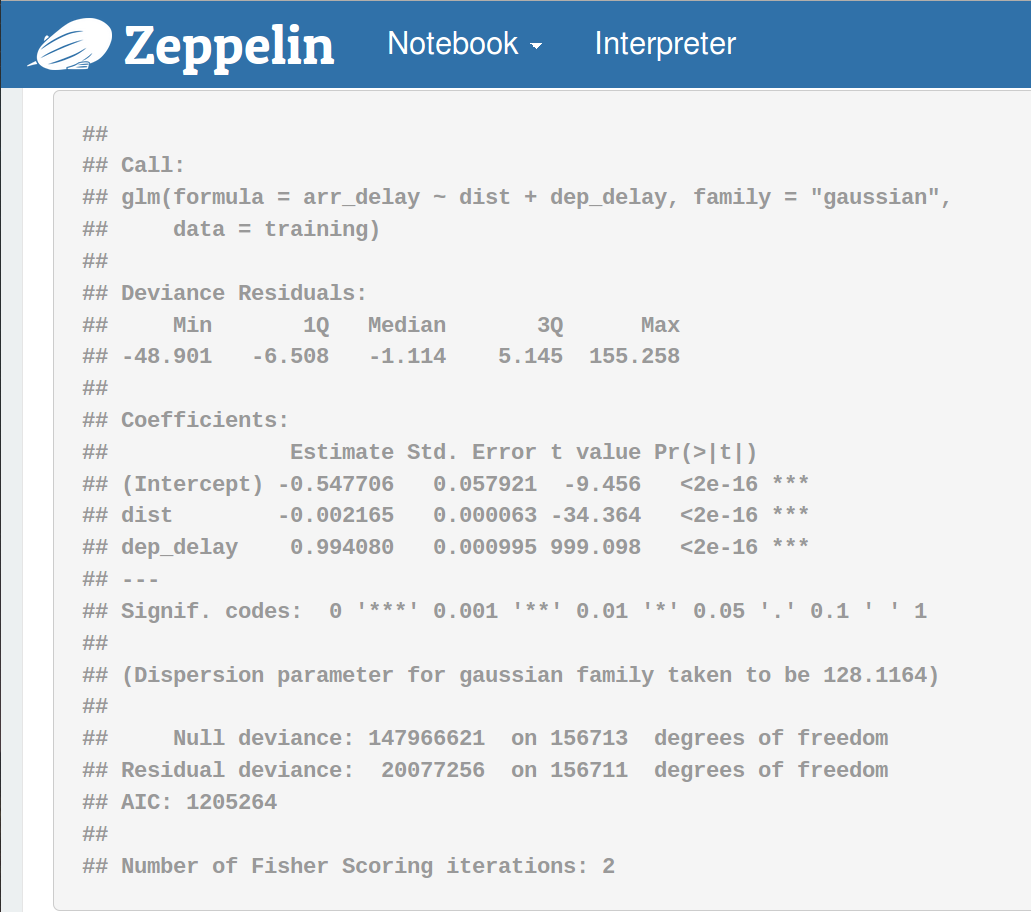
現在,讓我們用caret包做一些統計的機器學習。
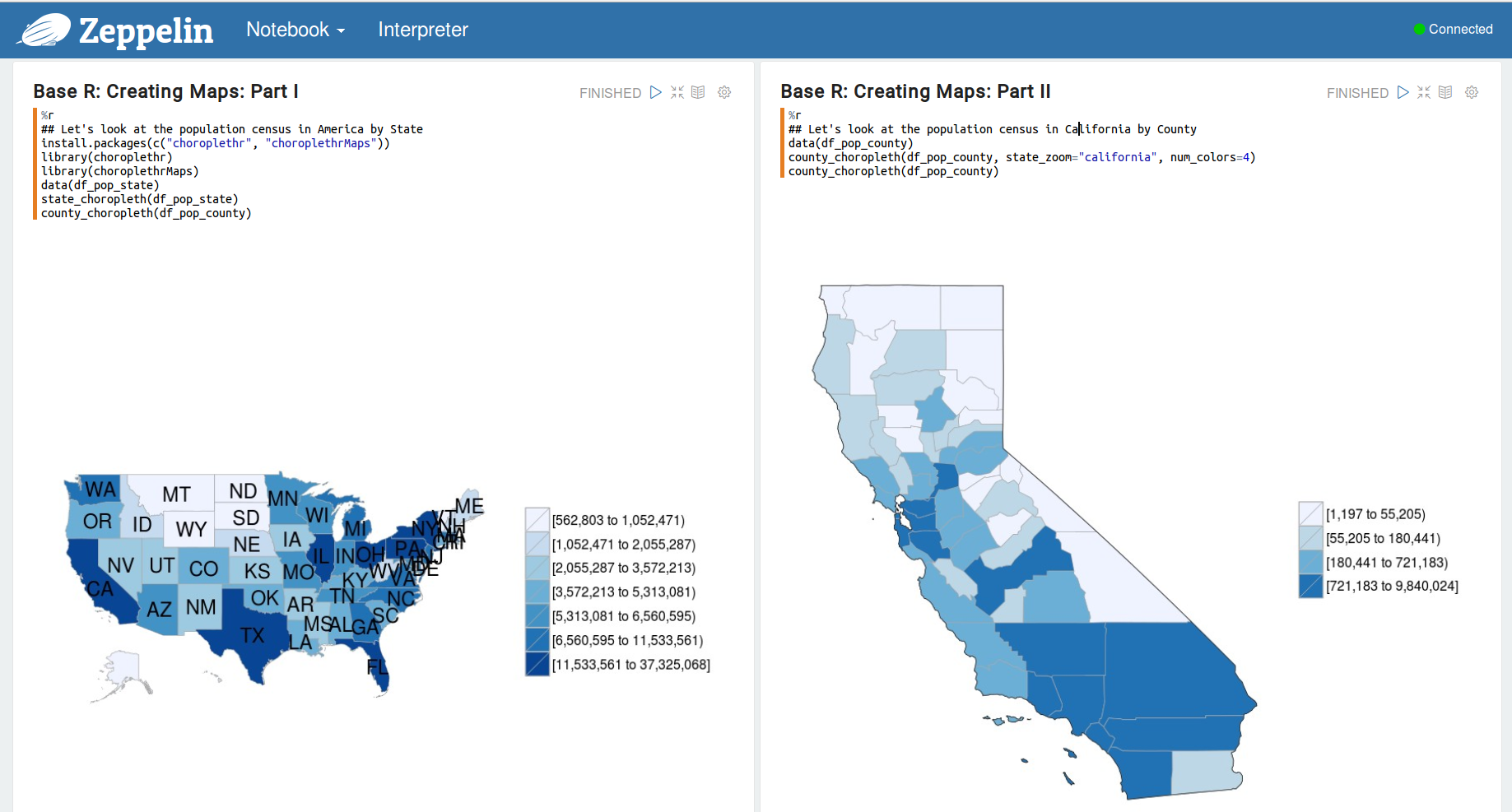
最后,繪制幾個地圖。
關于“Apache Zeppelin Notebook和R的示例分析”就介紹到這了,更多相關內容可以搜索億速云以前的文章,希望能夠幫助大家答疑解惑,請多多支持億速云網站!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





