溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何進行spark-shell的學習,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
今天我就給大家介紹一下spark-shell的的應用
spark-shell是spark的一種運行腳本。它已經初始化了sparkContext(sc)和SparkSesssion(Spark)
大家可以到spark的安裝路徑下
bin/spark-shell
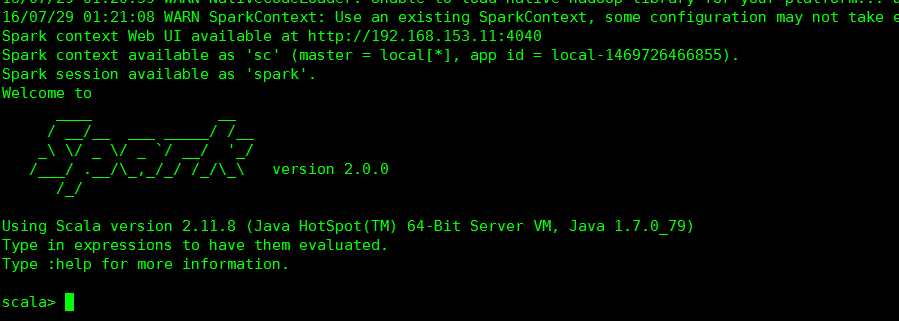
出現上圖就說明正確。下面就可以操作spark了
注意spark用的是scala語言
val text = sc.textFile("/usr/wordcount.txt")
text.count()

運行結果如果所示。注意這里我們是加載的本地文件,不是hdfs文件
下面我們對hdfs文件進行操作。寫出wordcount程序
首先,先上傳文件到hdfs
./hdfs dfs -put /usr/a.txt /user/spark
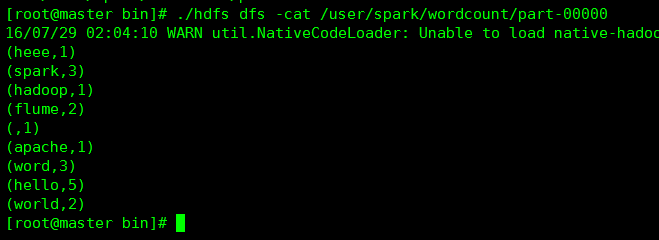
然后對數據進行操作
val text = sc.textFile("hdfs://192.168.153.11:9000/user/spark/a.txt")
val counts = text.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _)
counts.saveAsTextFile("hdfs://192.168.153.11:9000/user/spark/wordcount")
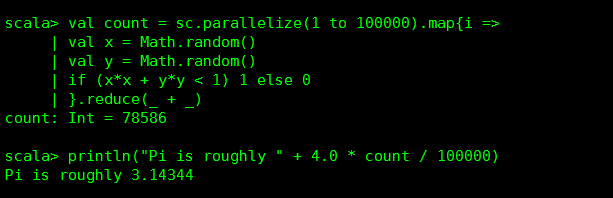
下面一個也是計算PI的demo
關于如何進行spark-shell的學習問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





