溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Spark Streaming中的架構設計和運行機制是什么”,在日常操作中,相信很多人在Spark Streaming中的架構設計和運行機制是什么問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Spark Streaming中的架構設計和運行機制是什么”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
RDD的模板是DStream,RDD DAG的模板是DStreamGraph,Spark Streaming是在RDD的基礎上加上時間維度,在Driver端會啟動一個定時器,間隔BatchDuration生成Job,在Executor端會啟動一個定時器,間隔200ms把接收到的數據放入BlockManager中,并把元數據信息上報給Driver端的ReceiverTracker,整個程序引擎是無時無刻在運行的。
JobGenerator類中有一個timer對象,其間隔BatchDuration發送GenerateJobs消息來生成Job。
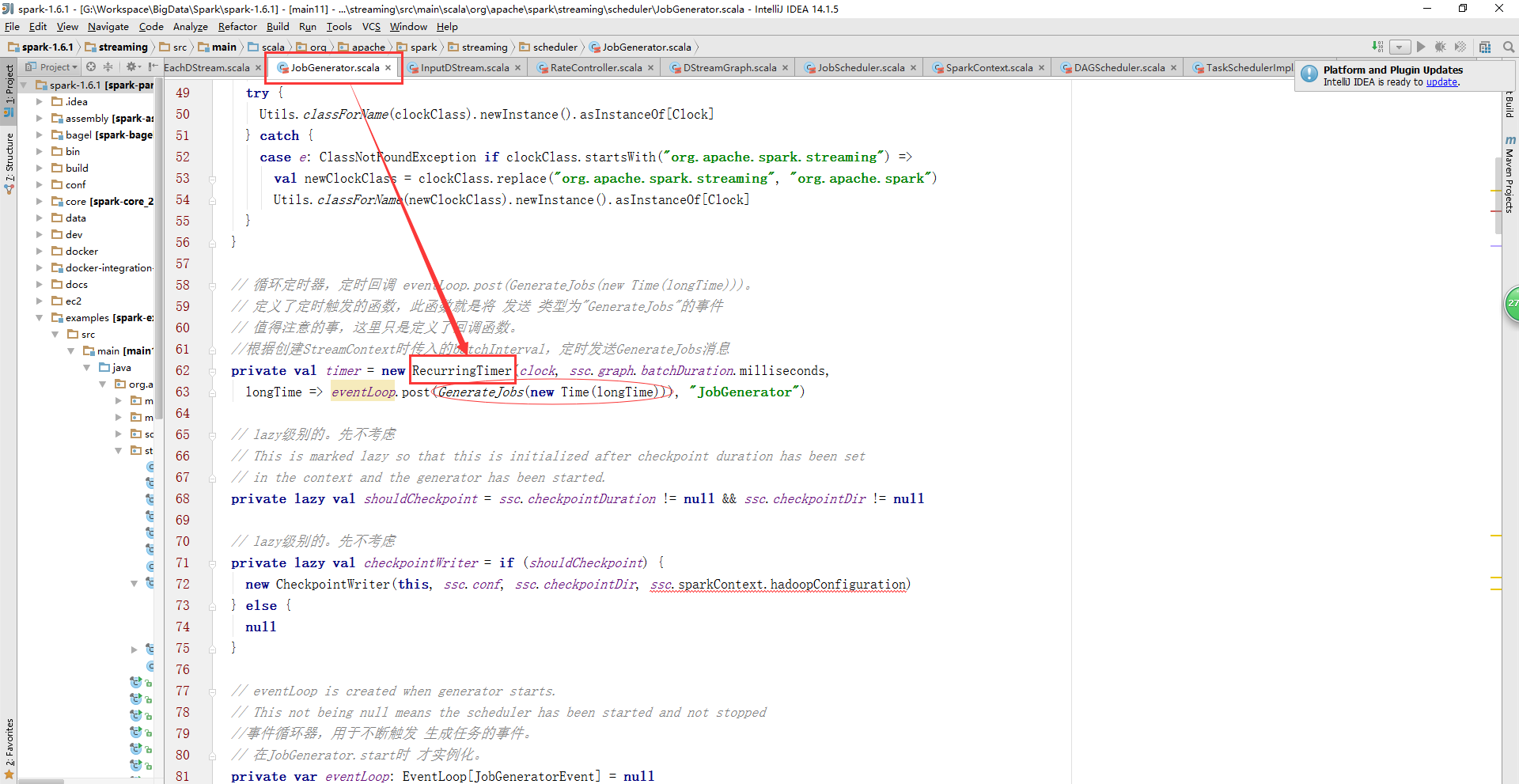
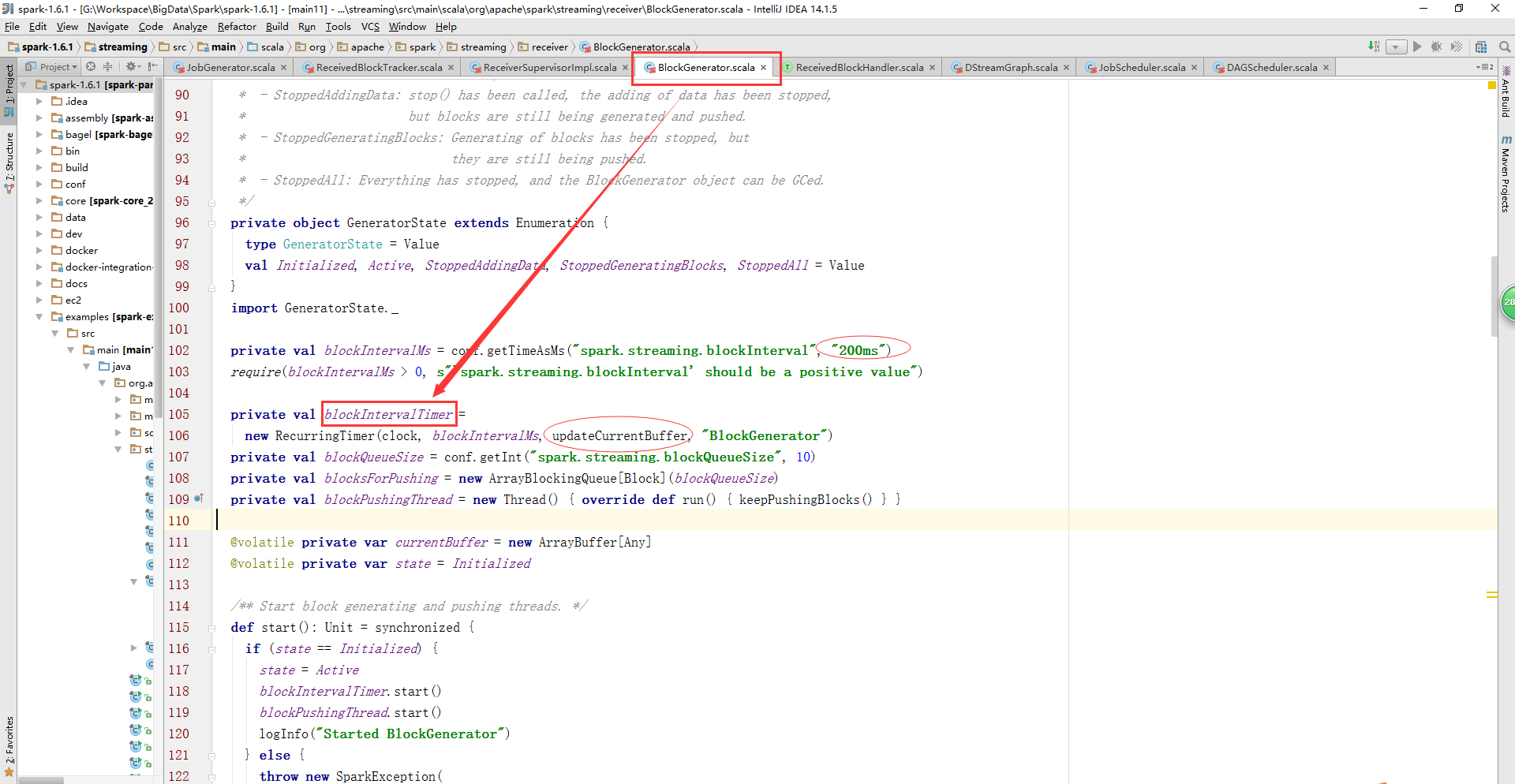
BlockGenerator類中有一個blockIntervalTimer對象,每隔200ms調用updateCurrentBuffer方法,把接收到的數據交給BlockManager進行存儲,并向ReceiverTracker上報元數據信息。
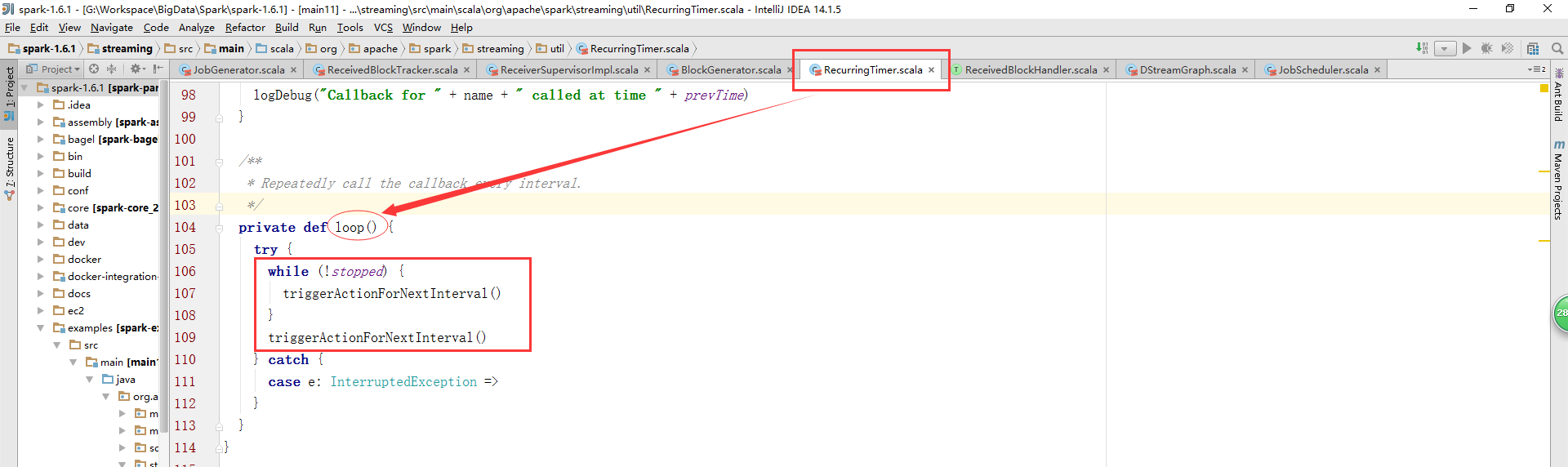
RecurringTimer類中的loop方法是一個死循環,一直執行,間隔一定的周期回調傳入的方法。
此外,默認的并行度具有遺傳性,父RDD的partition個數會遺傳給子RDD,當RDD中每個partition中數據較少時,為了提高效率,可以先調用coalesce方法合并到指定的partition個數。Spark Streaming中存在空RDD,即RDD里面沒有數據,此時也會生成Job,Job的生成是定時觸發的,不關心RDD中是否有數據,這是為了使整個框架能正常運行。
到此,關于“Spark Streaming中的架構設計和運行機制是什么”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





