溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關如何在生產過程中監控Kubernetes的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
監測Kubernetes集群不是一個簡單的事情。為了闡述可能會發生的錯誤的類型,這里是我們在AWS配置上的一個例子。
我們集群中的一個例子完美展示了用SkyDNS運行以及所有pods啟動的健康狀態,然而,在幾分鐘之后,SkyDNS就進入“CrashLoopBackoff”狀態了。應用程序容器已經是啟動的,但是還在功能失調階段,因為他們在第一次重新啟動的時候無法到達數據庫。
結果原來是集群宕機,但是我們只能盯著事件和pods狀態,對于發生了什么無法得到一個清晰的理解。
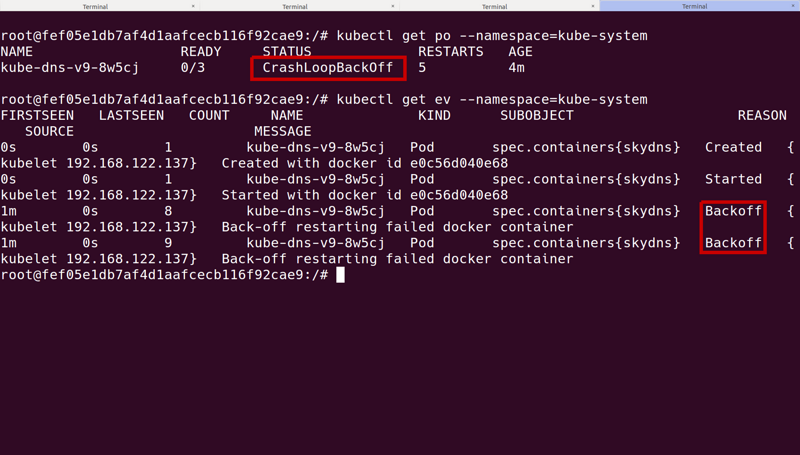
在聯系到主節點,看了SkyDNS pod的日志之后,他們用etcd揭露一個問題。SkyDNS無法連接,或者連接在它建立之后立刻變得不穩定了。etcd它本身就是在運行的,那么問題是出在哪里呢?
在做了相當一部分的調查之后,我們找到了answer。高延遲網絡連接磁盤導致讀寫錯誤,這就導致了etcd無法寫到文件系統。雖然它是正確配置而且也在運行工作,但是它并不是一直可為Kubernetes服務所用。
吸取教訓——即使你已經成功地建立起集群,但也不能保證它就可以像預期的那樣繼續工作。
那么在配置期間哪些問題比較容易出錯呢?問題主要有以下這些:
主機之間沒有聯系
etcd宕機或者不穩定/錯誤配置導致滯后
主機間的覆蓋網絡層損壞
單個節點中的任意一個都會宕機
Kubernetes API服務器或者控制器管理者宕機
Docker無法啟動容器
網絡分割會影響節點子集
我們在跟第一屆KubeCon的參加者交流了一些意見,頭腦風暴出以下可能的解決辦法:
你怎樣評估Kubernetes集群的健康?@klizhenas建議創建一個能夠給pods進行調度以及取消調度的app;有沒有人創建一下這個?
——Brandon Philips(@Brandon Philips)2015年11月11日
我們評估一下來監控Kubernetes的方法:
典型監測;
面向應用的冒煙測試
傳統的監控監測方法還沒有出現短缺。這個種類之中最好的選擇之一就是monit。
這是一個極其輕便精簡(單個執行文件),而且久經戰場的后臺程序運行在成千上萬臺機器上面——為小的起步但是是限制到監測單個系統。這是它最大的缺點。
使用monit過程中發現的問題之一就是一組測試執行有限和拓展性的缺乏。雖然可配置,但是我們還是不得不通過寫腳本來拓展它的功能,或者通過微弱的界面來使特殊目的程序得到控制。
更加重要的是,我們發現,連接幾個monit實例到一個高可用系統和彈性網絡是非常難的,而且系統和網絡還要代理收集自己分享的信息,然后協同工作來另這些信息保持更新。
“冒煙測試”這個術語的定義:
“一系列初步的測試來揭示一些簡單的故障的嚴重性,以此來拒絕預期中軟件的發布。它通常包含一個子集的測試,測試覆蓋了大多數重要的作用來確定重要作用在按照預期運行。冒煙測試最頻繁的特點就是它運行的很快,通常是秒級的。”
以我們已有的Kubernetes知識,我們堅信我們可以使用冒煙測試用以下特點來創建一個監視系統:
輕量級定期測試
高可用性和彈性網絡分區
零故障操作環境
時間序列作為健康數據的歷史
不管故障容易發生的抽象層次,就算是應用程序故障,或者是低層次網絡錯誤,這個系統都能夠追蹤他們以查到實際的原因。
我們的高層次解決方案是一系列程序Agent,一個集群中的一個節點駐留在另一個節點上。他們互相之間通過一個Serf提供的gossip協議來交流:
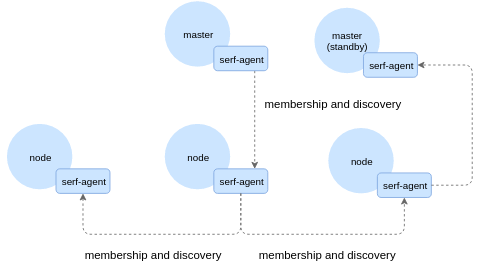
Kubernetes關鍵組件的Agents監控狀態——etcd,scheduler,API服務器和另外一些東西,還有一些執行冒煙程序——創建可以互相交流的輕量級容器。
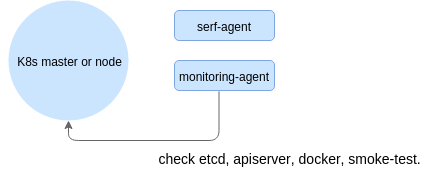
Agent定期同步數據,這樣每個節點都是隨時更新關于集群作為一個整體的信息。由于Serf提供的一致性保證比較弱,導致更新信息也不是很嚴格。定期測試結果保存到后端——這可以很簡單,就如同一個SQLite數據庫或者InfluxDB等一系列實時數據庫。
擁有一個對等系統對偵測故障和監測信息十分有幫助,即使系統中的關鍵部分部分宕機也沒有關系。在下面的例子中,主要節點以及大部分的節點都已經宕機,這就導致etcd也出了故障。然而,我們仍然可以得到關于集群連接到以下任意一個節點的診斷信息:
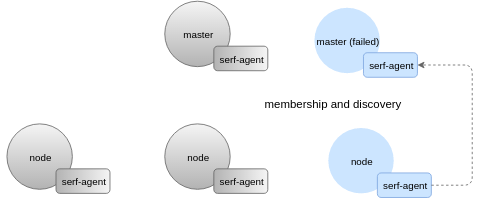
這里是在部分損壞的系統截圖:
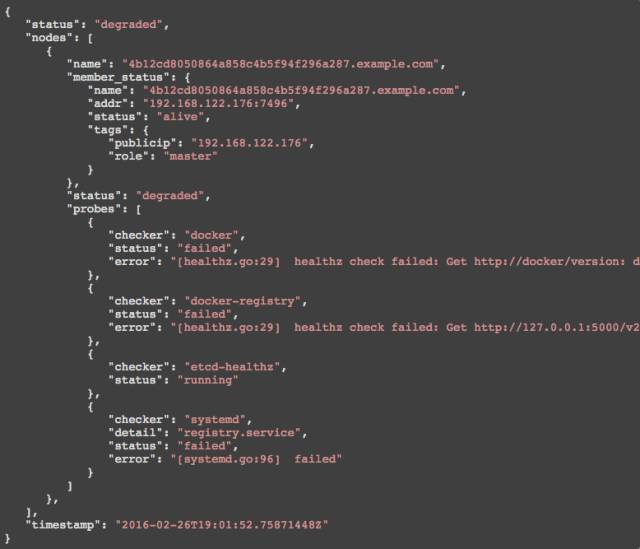
由于它的簡易,目前的模型就有了一定的限制。如果是為更小一些的集群(比如8個節點)就可以運行,然而,在一個再大一點的集群,你就不想每個節點都可以互相交流了。這個解決方式就是我們計劃采取的方案是創建一個特殊的聚合器,從Skype的超級節點那里或者是從Consul的“anti-entropy catelogs上面借鑒一些想法。
監測Kubernetes集群的狀態不是直接使用傳統監測工具就可以了的。手動故障排除有一定的復雜性,在集群里有一個自動反饋循環的話,就可以消除很大部分的復雜性。Satellite項目已經證明當操作集群的時候對我們是有用的,所以我們決定對它進行開源,希望它可以成為一個幫助提升kubernetes發現錯誤系統。
感謝各位的閱讀!關于“如何在生產過程中監控Kubernetes”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





