溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下HBase架構的示例分析,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
通常認為,Hadoop主要包含以下四大組件:
分布式鎖服務 Zookeeper
分布式文件系統 HDFS
分布式計算框架 MapReduce
分布式數據庫 HBase
其中,Zookeeper是HDFS、MapReduce、HBase都要依賴的基礎組件,它為分布式系統中的一致性問題的提供解決方案。
狹義的Hadoop,就是指HDFS和MapReduce;廣義的Hadoop,包括HDFS、MapReduce、HBase,甚至也包括這個生態圈中的Hive、Spark等。
關于Hadoop生態圈的內容,見:http://www.36dsj.com/archives/23504
Hbase構建于HDFS之上,它依賴HDFS和Zookeeper。
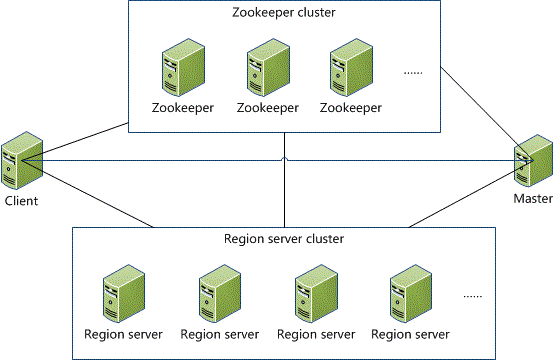
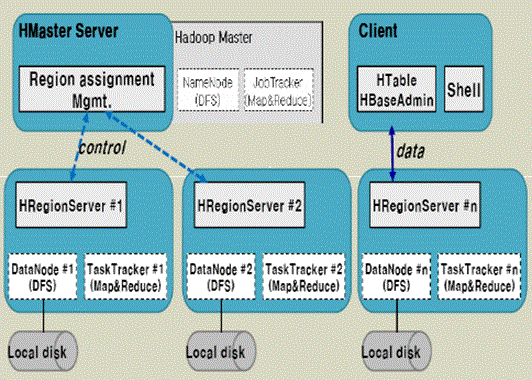
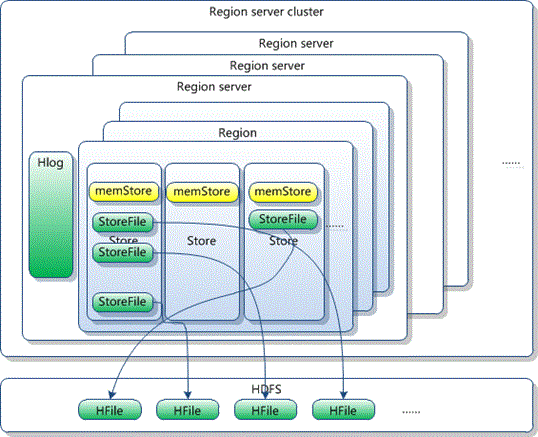
下面分別介紹各類結點的作用:
Client包含訪問HBase的接口,并維護著一些Cache來加快對HBase的訪問,比如regione的位置信息。
保證任何時候,集群中只有一個master;實現Master主從節點的failover。
實時監控Region Server的狀態,將Region Server的上線和下線信息實時通知給Master。
存儲Region的尋址入口。
存儲HBase的schema,包括有哪些table,每個table有哪些column family。
負責RegionServer的負載均衡。
管理和分配Region,比如在region split時分配新的Region;在Region Server退出時遷移其內的region到其它Region Server上。
負責schema的更新請求,實現DDL操作(如對table、column familiy的create、drop等),并將schema的更新同步到Zookeeper。
權限控制(ACL)。
維護Master分配給它的region,處理對這些region的IO請求。
負責切分在運行過程中變得過大的region。
Client通過Zookeeper、Region Server尋址,找到用戶talbe、RowKey所在的Region Server后,就直接從該Region Server讀寫數據了。這個過程不需要Master的參與,Master只是維護table和region的元數據信息,負載很低。
HBase有個特殊的表:.META. ,它存儲了所有用戶table對應的Region位置信息,它是不可split的;而ZooKeeper節點(/hbase/meta-region-server)存儲了.META.表的位置。
客戶端在第一次訪問用戶table的流程為:
從ZooKeeper(/hbase/meta-region-server)中獲取hbase:meta的位置(HRegionServer的位置),緩存該位置信息。
從Region Server中查詢用戶table對應請求的RowKey所在的Region Server,緩存該位置信息。
從查詢到的Region Server讀取Row。
從這個過程中,我們發現客戶會緩存這些位置信息,然而第二步它只是緩存當前RowKey對應的HRegion的位置,因而如果下一個要查的RowKey不在同一個HRegion中,則需要繼續查詢hbase:meta所在的HRegion,然而隨著時間的推移,客戶端緩存的位置信息越來越多,以至于不需要再次查找hbase:meta Table的信息,除非某個Region因為宕機或split被移動,此時需要重新查詢并且更新緩存。
以上是“HBase架構的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





