溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關RocketMQ有什么特點的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
RocketMQ是一款分布式、隊列模型的消息中間件,具有以下特點:
1.能夠保證嚴格的消息順序
2.提供豐富的消息拉取模式
3.高效的訂閱者水平擴展能力
4.實時的消息訂閱機制
5.億級消息堆積能力
一.RocketMQ網絡部署特點
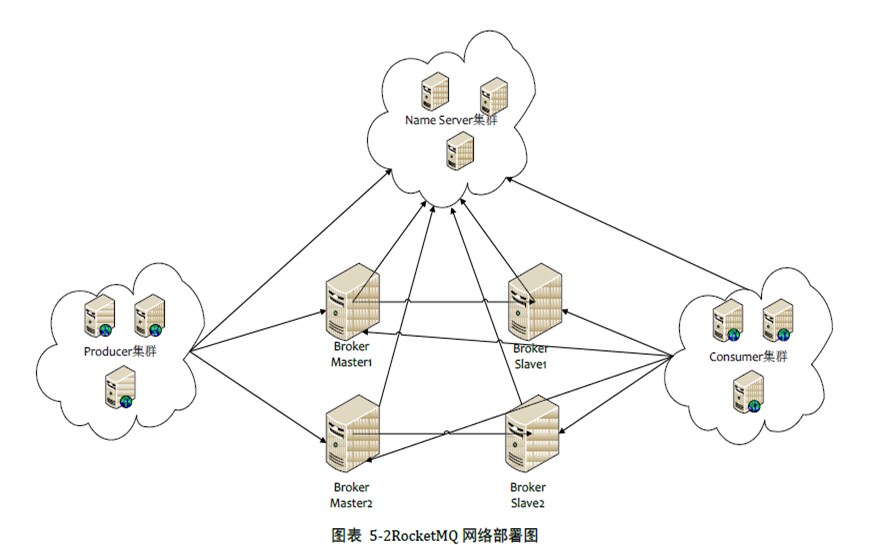
(1)NameServer是一個幾乎無狀態的節點,可集群部署,節點之間無任何信息同步
(2)Broker部署相對復雜,Broker氛圍Master與Slave,一個Master可以對應多個Slaver,但是一個Slaver只能對應一個Master,Master與Slaver的對應關系通過指定相同的BrokerName,不同的BrokerId來定義,BrokerId為0表示Master,非0表示Slaver。Master可以部署多個。每個Broker與NameServer集群中的所有節點建立長連接,定時注冊Topic信息到所有的NameServer
(3)Producer與NameServer集群中的其中一個節點(隨機選擇)建立長連接,定期從NameServer取Topic路由信息,并向提供Topic服務的Master建立長連接,且定時向Master發送心跳。Produce完全無狀態,可集群部署
(4)Consumer與NameServer集群中的其中一個節點(隨機選擇)建立長連接,定期從NameServer取Topic路由信息,并向提供Topic服務的Master、Slaver建立長連接,且定時向Master、Slaver發送心跳。Consumer即可從Master訂閱消息,也可以從Slave訂閱消息,訂閱規則由Broker配置決定
二.RocketMQ儲存特點
(1)零拷貝原理:Consumer消費消息過程,使用了零拷貝,零拷貝包括一下2中方式,RocketMQ使用第一種方式,因小塊數據傳輸的要求效果比sendfile方式好
a )使用mmap+write方式
優點:即使頻繁調用,使用小文件塊傳輸,效率也很高
缺點:不能很好的利用DMA方式,會比sendfile多消耗CPU資源,內存安全性控制復雜,需要避免JVM Crash問題
b)使用sendfile方式
優點:可以利用DMA方式,消耗CPU資源少,大塊文件傳輸效率高,無內存安全新問題
缺點:小塊文件效率低于mmap方式,只能是BIO方式傳輸,不能使用NIO
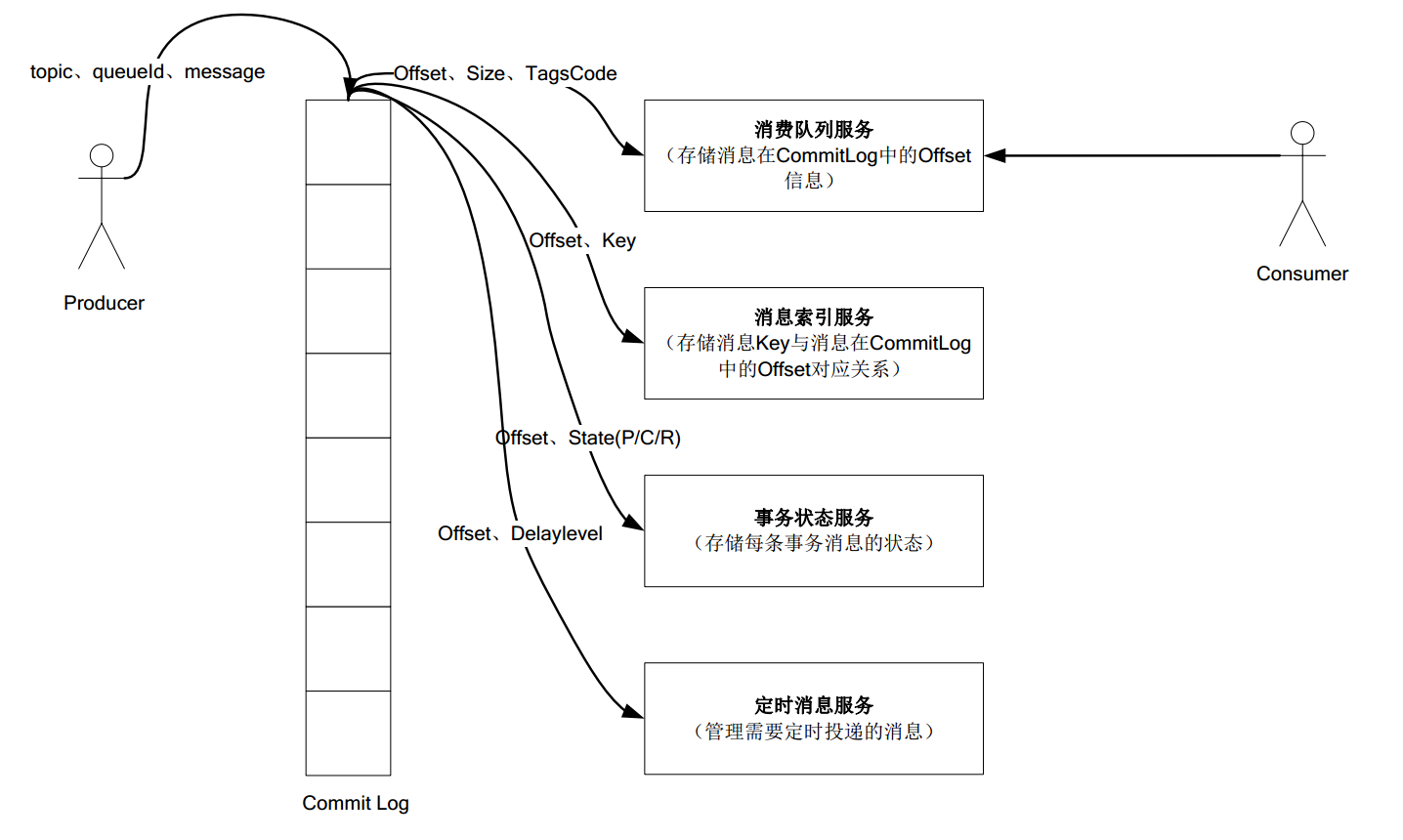
(2)數據存儲結構
三.RocketMQ關鍵特性
1.單機支持1W以上的持久化隊列
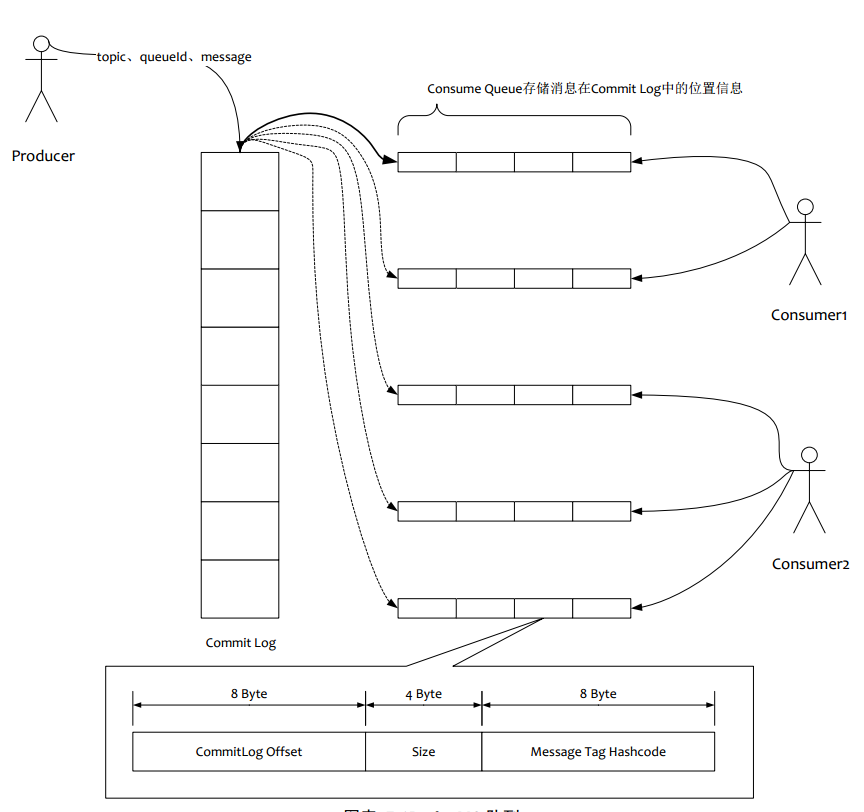
(1)所有數據單獨儲存到commit Log ,完全順序寫,隨機讀
(2)對最終用戶展現的隊列實際只儲存消息在Commit Log 的位置信息,并且串行方式刷盤
這樣做的好處:
(1)隊列輕量化,單個隊列數據量非常少
(2)對磁盤的訪問串行話,避免磁盤競爭,不會因為隊列增加導致IOWait增高
每個方案都有優缺點,他的缺點是:
(1)寫雖然是順序寫,但是讀卻變成了隨機讀
(2)讀一條消息,會先讀Consume Queue,再讀Commit Log,增加了開銷
(3)要保證Commit Log 與 Consume Queue完全的一致,增加了編程的復雜度
以上缺點如何客服:
(1)隨機讀,盡可能讓讀命中pagecache,減少IO操作,所以內存越大越好。如果系統中堆積的消息過多,讀數據要訪問硬盤會不會由于隨機讀導致系統性能急劇下降,答案是否定的。
a)訪問pagecache時,即使只訪問1K的消息,系統也會提前預讀出更多的數據,在下次讀時就可能命中pagecache
b)隨機訪問Commit Log 磁盤數據,系統IO調度算法設置為NOOP方式,會在一定程度上將完全的隨機讀變成順序跳躍方式,而順序跳躍方式讀較完全的隨機讀性能高5倍
(2)由于Consume Queue存儲數量極少,而且順序讀,在pagecache的與讀取情況下,Consume Queue的讀性能與內存幾乎一直,即使堆積情況下。所以可以認為Consume Queue完全不會阻礙讀性能
(3)Commit Log中存儲了所有的元信息,包含消息體,類似于MySQl、Oracle的redolog,所以只要有Commit Log存在, Consume Queue即使丟失數據,仍可以恢復出來
2.刷盤策略
rocketmq中的所有消息都是持久化的,先寫入系統pagecache,然后刷盤,可以保證內存與磁盤都有一份數據,訪問時,可以直接從內存讀取
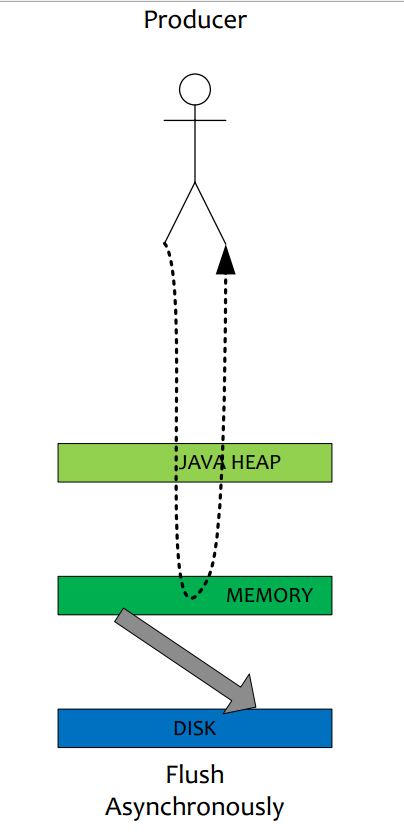
2.1異步刷盤
在有 RAID 卡, SAS 15000 轉磁盤測試順序寫文件,速度可以達到 300M 每秒左右,而線上的網卡一般都為千兆網卡,寫磁盤速度明顯快于數據網絡入口速度,那么是否可以做到寫完 內存就向用戶返回,由后臺線程刷盤呢?
(1). 由于磁盤速度大于網卡速度,那么刷盤的進度肯定可以跟上消息的寫入速度。
(2). 萬一由于此時系統壓力過大,可能堆積消息,除了寫入 IO,還有讀取 IO,萬一出現磁盤讀取落后情況,會不會導致系統內存溢出,答案是否定的,原因如下:
a) 寫入消息到 PAGECACHE 時,如果內存不足,則嘗試丟棄干凈的 PAGE,騰出內存供新消息使用,策略是 LRU 方式。
b) 如果干凈頁不足,此時寫入 PAGECACHE 會被阻塞,系統嘗試刷盤部分數據,大約每次嘗試 32 個 PAGE,來找出更多干凈 PAGE。
綜上,內存溢出的情況不會出現
2.2同步刷盤:
同步刷盤與異步刷盤的唯一區別是異步刷盤寫完 PAGECACHE 直接返回,而同步刷盤需要等待刷盤完成才返回,同步刷盤流程如下:
(1)寫入 PAGECACHE 后,線程等待,通知刷盤線程刷盤。
(2)刷盤線程刷盤后,喚醒前端等待線程,可能是一批線程。
(3)前端等待線程向用戶返回成功。
3.消息查詢
3.1按照MessageId查詢消息
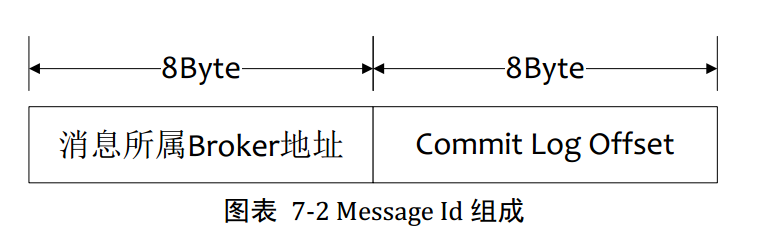
MsgId總共16個字節,包含消息儲存主機地址,消息Commit Log Offset。從MsgId中解析出Broker的地址和Commit Log 偏移地址,然后按照存儲格式所在位置消息buffer解析成一個完整消息
3.2按照Message Key查詢消息
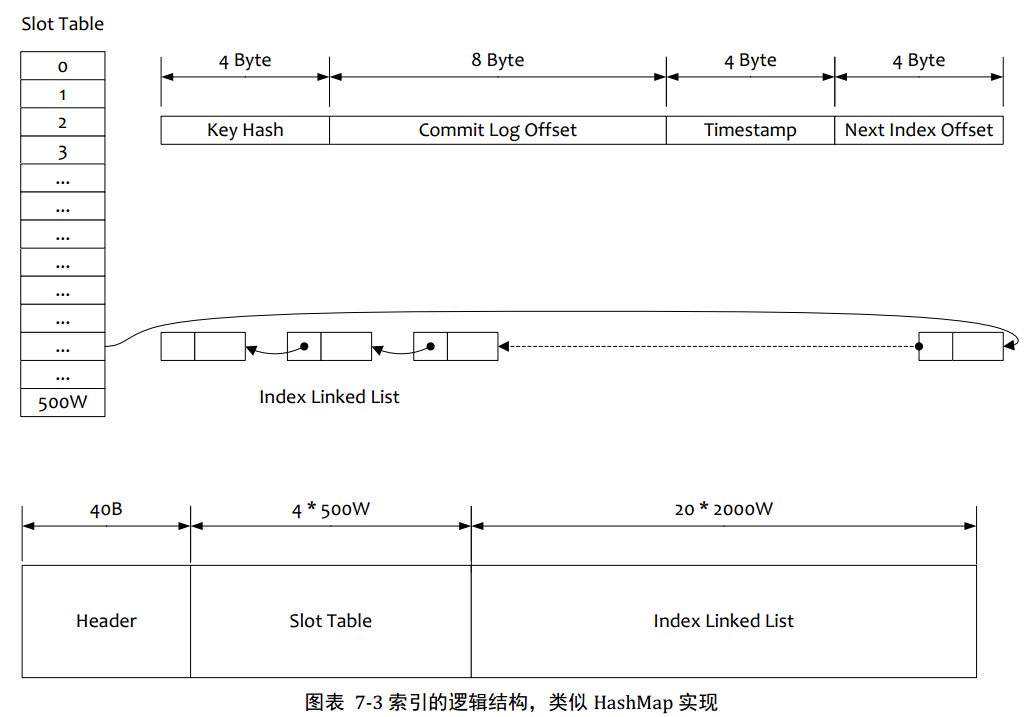
1.根據查詢的key的hashcode%slotNum得到具體的槽位置 (slotNum是一個索引文件里面包含的最大槽目數目,例如圖中所示slotNum=500W)
2.根據slotValue(slot對應位置的值)查找到索引項列表的最后一項(倒序排列,slotValue總是指向最新的一個索引項)
3.遍歷索引項列表返回查詢時間范圍內的結果集(默認一次最大返回的32條記錄)
4.Hash沖突,尋找key的slot位置時相當于執行了兩次散列函數,一次key的hash,一次key的hash取值模,因此這里存在兩次沖突的情況;第一種,key的hash值不同但模數相同,此時查詢的時候會在比較第一次key的hash值(每個索引項保存了key的hash值),過濾掉hash值不想等的情況。第二種,hash值相等key不想等,出于性能的考慮沖突的檢測放到客戶端處理(key的原始值是存儲在消息文件中的,避免對數據文件的解析),客戶端比較一次消息體的key是否相同
5.存儲,為了節省空間索引項中存儲的時間是時間差值(存儲時間——開始時間,開始時間存儲在索引文件頭中),整個索引文件是定長的,結構也是固定的
4.服務器消息過濾
RocketMQ的消息過濾方式有別于其他的消息中間件,是在訂閱時,再做過濾,先來看下Consume Queue存儲結構
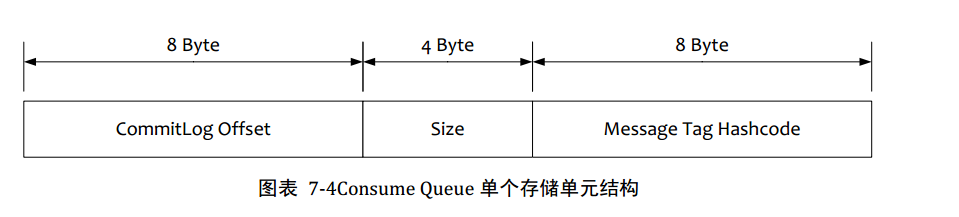
1.在Broker端進行Message Tag比較,先遍歷Consume Queue,如果存儲的Message Tag與訂閱的Message Tag不符合,則跳過,繼續比對下一個,符合則傳輸給Consumer。注意Message Tag是字符串形式,Consume Queue中存儲的是其對應的hashcode,比對時也是比對hashcode
2.Consumer收到過濾消息后,同樣也要執行在broker端的操作,但是比對的是真實的Message Tag字符串,而不是hashcode
為什么過濾要這么做?
1.Message Tag存儲hashcode,是為了在Consume Queue定長方式存儲,節約空間
2.過濾過程中不會訪問Commit Log 數據,可以保證堆積情況下也能高效過濾
3.即使存在hash沖突,也可以在Consumer端進行修正,保證萬無一失
5.單個JVM進程也能利用機器超大內存
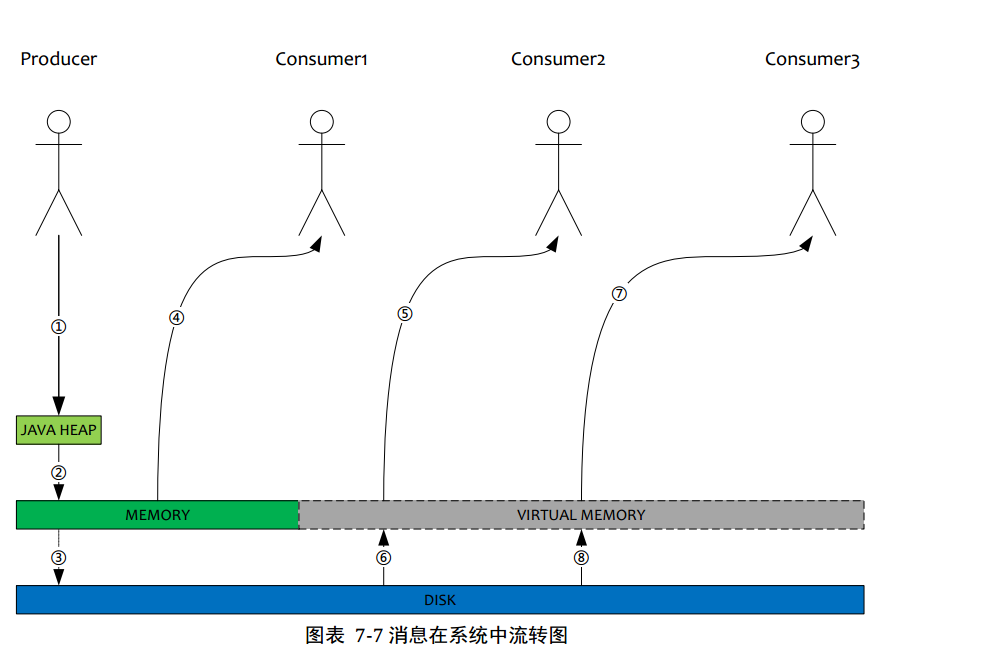
1.Producer發送消息,消息從socket進入java 堆
2.Producer發送消息,消息從java堆進入pagecache,物理內存
3.Producer發送消息,由異步線程刷盤,消息從pagecache刷入磁盤
4.Consumer拉消息(正常消費),消息直接從pagecache(數據在物理內存)轉入socket,到達Consumer,不經過java堆。這種消費場景最多,線上96G物理內存,按照1K消息算,可以物理緩存1億條消息
5.Consumer拉消息(異常消費),消息直接從pagecache轉入socket
6.Consumer拉消息(異常消費),由于socket訪問了虛擬內存,產生缺頁中斷,此時會產生磁盤IO,從磁盤Load消息到pagecache,然后直接從socket發出去
7.同5
8.同6
6.消息堆積問題解決辦法
1 消息的堆積容量、依賴磁盤大小
2 發消息的吞吐量大小受影響程度、無Slave情況,會受一定影響、有Slave情況,不受影響
3 正常消費的Consumer是否會受影響、無Slave情況,會受一定影響、有Slave情況,不受影響
4 訪問堆積在磁盤的消息時,吞吐量有多大、與訪問的并發有關,最終會降到5000左右
在有Slave情況下,Master一旦發現Consumer訪問堆積在磁盤的數據時,回想Consumer下達一個重定向指令,令Consumer從Slave拉取數據,這樣正常的發消息與正常的消費不會因為堆積受影響,因為系統將堆積場景與非堆積場景分割在了兩個不同的節點處理。這里會產生一個問題,Slave會不會寫性能下降,答案是否定的。因為Slave的消息寫入只追求吞吐量,不追求實時性,只要整體的吞吐量高就行了,而Slave每次都是從Master拉取一批數據,如1M,這種批量順序寫入方式使堆積情況,整體吞吐量影響相對較小,只是寫入RT會變長。
感謝各位的閱讀!關于“RocketMQ有什么特點”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





