溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“如何深入理解java內存模型”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
在并發編程中,我們需要處理兩個關鍵問題:線程之間如何通信及線程之間如何同步(這里的線程是指并發執行的活動實體)。通信是指線程之間以何種機制來交換信息。在命令式編程中,線程之間的通信機制有兩種:共享內存和消息傳遞。
在共享內存的并發模型里,線程之間共享程序的公共狀態,線程之間通過寫-讀內存中的公共狀態來隱式進行通信。在消息傳遞的并發模型里,線程之間沒有公共狀態,線程之間必須通過明確的發送消息來顯式進行通信。
同步是指程序用于控制不同線程之間操作發生相對順序的機制。在共享內存并發模型里,同步是顯式進行的。程序員必須顯式指定某個方法或某段代碼需要在線程之間互斥執行。在消息傳遞的并發模型里,由于消息的發送必須在消息的接收之前,因此同步是隱式進行的。
在java中,所有實例域、靜態域和數組元素存儲在堆內存中,堆內存在線程之間共享(本文使用“共享變量”這個術語代指實例域,靜態域和數組元素)。局部變量(Local variables),方法定義參數(java語言規范稱之為formal method parameters)和異常處理器參數(exception handler parameters)不會在線程之間共享,它們不會有內存可見性問題,也不受內存模型的影響。
Java線程之間的通信由Java內存模型(本文簡稱為JMM)控制,JMM決定一個線程對共享變量的寫入何時對另一個線程可見。從抽象的角度來看,JMM定義了線程和主內存之間的抽象關系:線程之間的共享變量存儲在主內存(main memory)中,每個線程都有一個私有的本地內存(local memory),本地內存中存儲了該線程以讀/寫共享變量的副本。本地內存是JMM的一個抽象概念,并不真實存在。它涵蓋了緩存,寫緩沖區,寄存器以及其他的硬件和編譯器優化。Java內存模型的抽象示意圖如下:
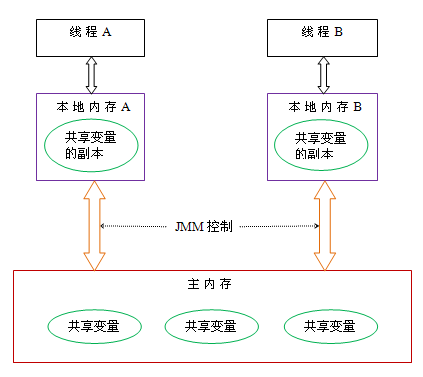
從上圖來看,線程A與線程B之間如要通信的話,必須要經歷下面2個步驟:
首先,線程A把本地內存A中更新過的共享變量刷新到主內存中去。
然后,線程B到主內存中去讀取線程A之前已更新過的共享變量。
下面通過示意圖來說明這兩個步驟:

如上圖所示,本地內存A和B有主內存中共享變量x的副本。假設初始時,這三個內存中的x值都為0。線程A在執行時,把更新后的x值(假設值為1)臨時存放在自己的本地內存A中。當線程A和線程B需要通信時,線程A首先會把自己本地內存中修改后的x值刷新到主內存中,此時主內存中的x值變為了1。隨后,線程B到主內存中去讀取線程A更新后的x值,此時線程B的本地內存的x值也變為了1。
從整體來看,這兩個步驟實質上是線程A在向線程B發送消息,而且這個通信過程必須要經過主內存。JMM通過控制主內存與每個線程的本地內存之間的交互,來為java程序員提供內存可見性保證。
在執行程序時為了提高性能,編譯器和處理器常常會對指令做重排序。重排序分三種類型:
編譯器優化的重排序。編譯器在不改變單線程程序語義的前提下,可以重新安排語句的執行順序。
指令級并行的重排序。現代處理器采用了指令級并行技術(Instruction-Level Parallelism, ILP)來將多條指令重疊執行。如果不存在數據依賴性,處理器可以改變語句對應機器指令的執行順序。
內存系統的重排序。由于處理器使用緩存和讀/寫緩沖區,這使得加載和存儲操作看上去可能是在亂序執行。
從java源代碼到最終實際執行的指令序列,會分別經歷下面三種重排序:

上述的1屬于編譯器重排序,2和3屬于處理器重排序。這些重排序都可能會導致多線程程序出現內存可見性問題。對于編譯器,JMM的編譯器重排序規則會禁止特定類型的編譯器重排序(不是所有的編譯器重排序都要禁止)。對于處理器重排序,JMM的處理器重排序規則會要求java編譯器在生成指令序列時,插入特定類型的內存屏障(memory barriers,intel稱之為memory fence)指令,通過內存屏障指令來禁止特定類型的處理器重排序(不是所有的處理器重排序都要禁止)。
JMM屬于語言級的內存模型,它確保在不同的編譯器和不同的處理器平臺之上,通過禁止特定類型的編譯器重排序和處理器重排序,為程序員提供一致的內存可見性保證。
現代的處理器使用寫緩沖區來臨時保存向內存寫入的數據。寫緩沖區可以保證指令流水線持續運行,它可以避免由于處理器停頓下來等待向內存寫入數據而產生的延遲。同時,通過以批處理的方式刷新寫緩沖區,以及合并寫緩沖區中對同一內存地址的多次寫,可以減少對內存總線的占用。雖然寫緩沖區有這么多好處,但每個處理器上的寫緩沖區,僅僅對它所在的處理器可見。這個特性會對內存操作的執行順序產生重要的影響:處理器對內存的讀/寫操作的執行順序,不一定與內存實際發生的讀/寫操作順序一致!為了具體說明,請看下面示例:
| Processor A | Processor B |
|---|---|
| a = 1; //A1 x = b; //A2 | b = 2; //B1 y = a; //B2 |
| 初始狀態:a = b = 0 處理器允許執行后得到結果:x = y = 0 |
假設處理器A和處理器B按程序的順序并行執行內存訪問,最終卻可能得到x = y = 0的結果。具體的原因如下圖所示:
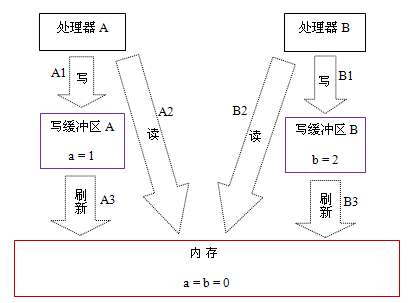
這里處理器A和處理器B可以同時把共享變量寫入自己的寫緩沖區(A1,B1),然后從內存中讀取另一個共享變量(A2,B2),最后才把自己寫緩存區中保存的臟數據刷新到內存中(A3,B3)。當以這種時序執行時,程序就可以得到x = y = 0的結果。
從內存操作實際發生的順序來看,直到處理器A執行A3來刷新自己的寫緩存區,寫操作A1才算真正執行了。雖然處理器A執行內存操作的順序為:A1->A2,但內存操作實際發生的順序卻是:A2->A1。此時,處理器A的內存操作順序被重排序了(處理器B的情況和處理器A一樣,這里就不贅述了)。
這里的關鍵是,由于寫緩沖區僅對自己的處理器可見,它會導致處理器執行內存操作的順序可能會與內存實際的操作執行順序不一致。由于現代的處理器都會使用寫緩沖區,因此現代的處理器都會允許對寫-讀操做重排序。
下面是常見處理器允許的重排序類型的列表:
| Load-Load | Load-Store | Store-Store | Store-Load | 數據依賴 | |
| sparc-TSO | N | N | N | Y | N |
| x86 | N | N | N | Y | N |
| ia64 | Y | Y | Y | Y | N |
| PowerPC | Y | Y | Y | Y | N |
上表單元格中的“N”表示處理器不允許兩個操作重排序,“Y”表示允許重排序。
從上表我們可以看出:常見的處理器都允許Store-Load重排序;常見的處理器都不允許對存在數據依賴的操作做重排序。sparc-TSO和x86擁有相對較強的處理器內存模型,它們僅允許對寫-讀操作做重排序(因為它們都使用了寫緩沖區)。
※注1:sparc-TSO是指以TSO(Total Store Order)內存模型運行時,sparc處理器的特性。
※注2:上表中的x86包括x64及AMD64。
※注3:由于ARM處理器的內存模型與PowerPC處理器的內存模型非常類似,本文將忽略它。
※注4:數據依賴性后文會專門說明。
為了保證內存可見性,java編譯器在生成指令序列的適當位置會插入內存屏障指令來禁止特定類型的處理器重排序。JMM把內存屏障指令分為下列四類:
| 屏障類型 | 指令示例 | 說明 |
| LoadLoad Barriers | Load1; LoadLoad; Load2 | 確保Load1數據的裝載,之前于Load2及所有后續裝載指令的裝載。 |
| StoreStore Barriers | Store1; StoreStore; Store2 | 確保Store1數據對其他處理器可見(刷新到內存),之前于Store2及所有后續存儲指令的存儲。 |
| LoadStore Barriers | Load1; LoadStore; Store2 | 確保Load1數據裝載,之前于Store2及所有后續的存儲指令刷新到內存。 |
| StoreLoad Barriers | Store1; StoreLoad; Load2 | 確保Store1數據對其他處理器變得可見(指刷新到內存),之前于Load2及所有后續裝載指令的裝載。StoreLoad Barriers會使該屏障之前的所有內存訪問指令(存儲和裝載指令)完成之后,才執行該屏障之后的內存訪問指令。 |
StoreLoad Barriers是一個“全能型”的屏障,它同時具有其他三個屏障的效果。現代的多處理器大都支持該屏障(其他類型的屏障不一定被所有處理器支持)。執行該屏障開銷會很昂貴,因為當前處理器通常要把寫緩沖區中的數據全部刷新到內存中(buffer fully flush)。
從JDK5開始,java使用新的JSR -133內存模型(本文除非特別說明,針對的都是JSR- 133內存模型)。JSR-133提出了happens-before的概念,通過這個概念來闡述操作之間的內存可見性。如果一個操作執行的結果需要對另一個操作可見,那么這兩個操作之間必須存在happens-before關系。這里提到的兩個操作既可以是在一個線程之內,也可以是在不同線程之間。 與程序員密切相關的happens-before規則如下:
程序順序規則:一個線程中的每個操作,happens- before 于該線程中的任意后續操作。
監視器鎖規則:對一個監視器鎖的解鎖,happens- before 于隨后對這個監視器鎖的加鎖。
volatile變量規則:對一個volatile域的寫,happens- before 于任意后續對這個volatile域的讀。
傳遞性:如果A happens- before B,且B happens- before C,那么A happens- before C。
注意,兩個操作之間具有happens-before關系,并不意味著前一個操作必須要在后一個操作之前執行!happens-before僅僅要求前一個操作(執行的結果)對后一個操作可見,且前一個操作按順序排在第二個操作之前(the first is visible to and ordered before the second)。happens- before的定義很微妙,后文會具體說明happens-before為什么要這么定義。
happens-before與JMM的關系如下圖所示:
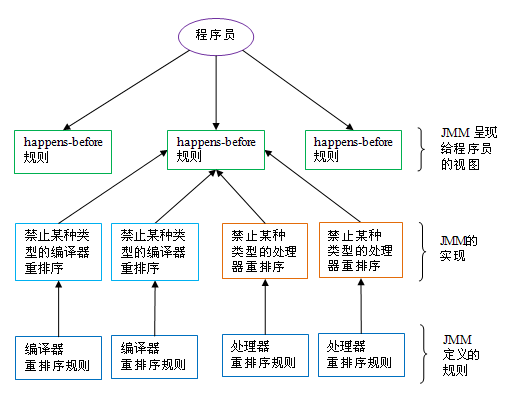
如上圖所示,一個happens-before規則通常對應于多個編譯器重排序規則和處理器重排序規則。對于java程序員來說,happens-before規則簡單易懂,它避免程序員為了理解JMM提供的內存可見性保證而去學習復雜的重排序規則以及這些規則的具體實現。
“如何深入理解java內存模型”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





