溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Hadoop常見面試題有哪些,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
hadoop-env.sh JAVA_HOME,HADOOP_CONF_DIR,HADOOP_LOG_DIR,HADOOP_PID_DIR,HADOOP_CLASSPATH,hadoop相關進程JVM參數 其他 core-site.xml fs.defaultFS,hadoop.tmp.dir,ha.zookeeper.quorum,io.compression.codecs,io.file.buffer.size hdfs-site.xml namenode的url信息,dfs.name.dir,dfs.data.dir,dfs.replication,dfs.namenode.shared.edits.dir, dfs.journalnode.edits.dir,dfs.hosts.exclude slaves datanode列表 mapred-site.xml mapreduce.framework.name,mapreduce.map.output.compress.codec yarn-site.xml resourcemanager信息 excludes 排除節點列表
2 hdfs存儲機制是什么
1. HDFS開創性地設計出一套文件存儲方式,即對文件分割后分別存放; 2. HDFS將要存儲的大文件進行分割,分割后存放在既定的存儲塊(Block)中,并通過預先設定的優化處理,模式對存儲的數據進行預處理,從而解決了大文件儲存與計算的需求; 3. 一個HDFS集群包括兩大部分,即NameNode與DataNode。一般來說,一個集群中會有一個NameNode和多個DataNode共同工作; 4. NameNode是集群的主服務器,主要是用于對HDFS中所有的文件及內容數據進行維護,并不斷讀取記錄集群中DataNode主機情況與工作狀態,并通過讀取與寫入鏡像日志文件的方式進行存儲; 5. DataNode在HDFS集群中擔任任務具體執行角色,是集群的工作節點。文件被分成若干個相同大小的數據塊,分別存儲在若干個DataNode上,DataNode會定期向集群內NameNode發送自己的運行狀態與存儲內容,并根據NameNode發送的指令進行工作; 6. NameNode負責接受客戶端發送過來的信息,然后將文件存儲位置信息發送給提交請求的客戶端,由客戶端直接與DataNode進行聯系,從而進行部分文件的運算與操作。 7. Block是HDFS的基本存儲單元,默認大小是64M(hadoop2中時128M); 8. HDFS還可以對已經存儲的Block進行多副本備份,將每個Block至少復制到3個相互獨立的硬件上,這樣可以快速恢復損壞的數據; 9. 用戶可以使用既定的API接口對HDFS中的文件進行操作; 10. 當客戶端的讀取操作發生錯誤的時候,客戶端會向NameNode報告錯誤,并請求NameNode排除錯誤的DataNode后后重新根據距離排序,從而獲得一個新的DataNode的讀取路徑。如果所有的DataNode都報告讀取失敗,那么整個任務就讀取失敗; 11. 對于寫出操作過程中出現的問題,FSDataOutputStream并不會立即關閉。客戶端向NameNode報告錯誤信息,并直接向提供備份的DataNode中寫入數據。備份DataNode被升級為首選DataNode,并在其余2個DataNode中備份復制數據。NameNode對錯誤的DataNode進行標記以便后續對其進行處理。
3 怎么查看,刪除,移動,拷貝hadoop文件
hdfs dfs -text ... hdfs dfs -rm ... hdfs dfs -mv ... hdfs dfs -cp ...
4 hadoop中combiner作用
1、combiner類似本地的reduce功能.實現本地key的聚合,減清到reduce的io壓力
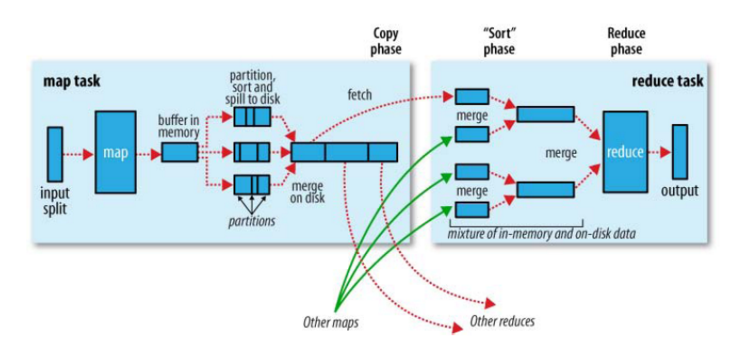
5 mr工作原理,距離說明mr是怎樣運行的
不確定是不是回答這個圖
hive處理數據量較大,高延遲,基于hdfs,hql轉換成mr執行,不支持數據修改 oracle處理數據量相對較小,有所有,低延遲,支持數據修改
create '表名稱','列族名稱1','列名族稱2','列名族稱N' put '表名','行名','列名','值' get '表名','行名' delete '表名','行名稱','列名稱'
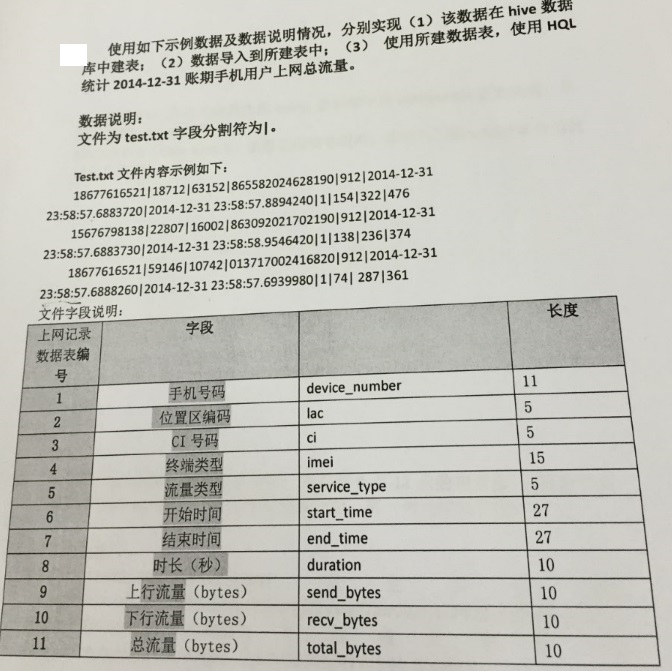
//建表 create table net_info (device_number int,lac int,ci int,imei bigint,start_time timestamp,end_time timestamp,duration int,send_bytes int,recv_bytes int,total_bytes int) row format delimited fields terminated by '|'; //加載數據 load data local inpath '/home/hadoop/text.txt' into table net_info; select * from net_info; //統計 select sum(total_bytes) from net_info where start_time>='2014-12-31' and end_time<'2015-1-1' //順便復習下修改列 alter table net_info change start_time start_time timestamp;
Hive可以允許用戶編寫自己定義的函數UDF,來在查詢中使用。Hive中有3種UDF:
1)UDF:操作單個數據行,產生單個數據行。
2)UDAF:操作多個數據行,產生一個數據行。
3)UDTF:操作一個數據行,產生多個數據行一個表作為輸出。
用戶構建的UDF使用過程如下:
第一步:繼承UDF或者UDAF或者UDTF,實現特定的方法。
第二步:將寫好的類打包為jar。如hivefirst.jar。
第三步:進入到Hive外殼環境中,利用add jar /home/hadoop/hivefirst.jar 注冊該jar文件。
該例實現網上找了個作參考:
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorUtils;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.IntObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.StringObjectInspector;
import org.joda.time.LocalDate;
import org.joda.time.format.DateTimeFormat;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
public class AddMonth extends GenericUDF {
@Override
public ObjectInspector initialize(ObjectInspector[] arguments) throws UDFArgumentException {
if (arguments.length != 2) {
throw new UDFArgumentLengthException("The function add_month(local_date, months_to_add) requires 2 arguments.");
}
ObjectInspector localDateVal = arguments[0];
ObjectInspector monthsToAddVal = arguments[1];
if (!(localDateVal instanceof StringObjectInspector)) {
throw new UDFArgumentException("First argument must be of type String (local_date as String)");
}
if (!(monthsToAddVal instanceof IntObjectInspector)) {
throw new UDFArgumentException("Second argument must be of type int (Month to add)");
}
return PrimitiveObjectInspectorFactory.writableStringObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] arguments) throws HiveException {
String localDateVal = (String) ObjectInspectorUtils.copyToStandardJavaObject(arguments[0].get(),
PrimitiveObjectInspectorFactory.javaStringObjectInspector);
IntWritable monthsToAddVal = (IntWritable) ObjectInspectorUtils.copyToStandardJavaObject(arguments[1].get(),
PrimitiveObjectInspectorFactory.javaIntObjectInspector);
LocalDate localDate = null;
try {
localDate = LocalDate.parse(localDateVal, DateTimeFormat.forPattern("yyyy-MM-dd"));
} catch (Exception ex) {
return null;
}
return new Text(localDate.plusMonths(monthsToAddVal.get().toString());
}
@Override
public String getDisplayString(String[] arguments) {
assert (arguments.length == 2);
return "add_month(" + arguments[0] + ", " + arguments[1] + ")";
}
}
關于“Hadoop常見面試題有哪些”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





