溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要為大家展示了“如何閱讀kubernetes源代碼”,內容簡而易懂,條理清晰,希望能夠幫助大家解決疑惑,下面讓小編帶領大家一起研究并學習一下“如何閱讀kubernetes源代碼”這篇文章吧。
源代碼中包含了所有信息。寫開源軟件,從文檔和其他地方拿到的是二手的信息,代碼就是最直接的一手信息。代碼就是黑客帝國中neo看到的世界本源。
文本并不是代碼本身。文本只是在人類可讀的模式和編譯器可解析之間做了一個折中。代碼的本質是具有復雜拓撲的數據結構,就像樹或者電路一樣。所以讀代碼的過程是在腦中構建出這個世界,所謂腦補是也。
閱讀好的代碼是一種享受。我最喜歡閱讀的是redis的代碼,用C寫的,極端簡潔但又威力強大。幾句話就把最高效、精妙的數據結構完成出來,就像一篇福爾摩斯的偵探小說。在看的時候我常常想,如果讓我實現這個功能,是否能像他這么簡單高效?
以閱讀k8s其中的一個模塊,scheduler為例子,來講講我是怎么讀代碼的
scheduler是k8s的調度模塊,做的事情就是拿到pod之后在node中尋找合適的進行適配這么一個單純的功能。實際上,我已經多次編譯和構建這個程序并運行起來。在我的腦中,sheduler在整個系統中是這樣的:
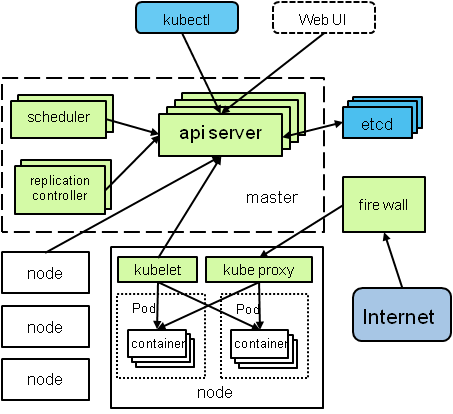
scheduler作為一個客戶端,從apiserver中讀取到需要分配的pod,和擁有的node,然后進行過濾和算分,最后把這個匹配信息通過apiserver寫入到etcd里面,供下一步的kubelet去拉起pod使用。這樣,立刻有幾個問題浮現出來
問1.scheduler讀取到的數據結構是怎么樣的?(輸入)
問2.scheduler寫出的的數據結構是怎么樣的?(輸出)
問3.在前面的測試中,scheduler成為了系統的瓶頸,為什么?
問4.社區有人說增加緩存能有效提高scheduler的效率,他的思路是可行的嗎?
kubernetes\plugin\cmd\kube-scheduler\scheduler.go
這段代碼比較短就全文貼出來了
package main
import (
"runtime"
"k8s.io/kubernetes/pkg/healthz"
"k8s.io/kubernetes/pkg/util"
"k8s.io/kubernetes/pkg/version/verflag"
"k8s.io/kubernetes/plugin/cmd/kube-scheduler/app"
"github.com/spf13/pflag"
)
func init() {
healthz.DefaultHealthz() //忽略……
}
func main() {
runtime.GOMAXPROCS(runtime.NumCPU()) //忽略……
s := app.NewSchedulerServer() //關注,實際調用的初始化
s.AddFlags(pflag.CommandLine) //忽略,命令行解析
util.InitFlags()
util.InitLogs()
defer util.FlushLogs() //忽略,開日志等
verflag.PrintAndExitIfRequested()
s.Run(pflag.CommandLine.Args()) //關注,實際跑的口子
}可以看到,對于細枝末節我一概忽略掉,進入下一層,但是,我并不是不提出問題,提出的問題會寫在這里,然后從腦子里面“忘掉”,以減輕前進的負擔
kubernetes\plugin\cmd\kube-scheduler\app\server.go
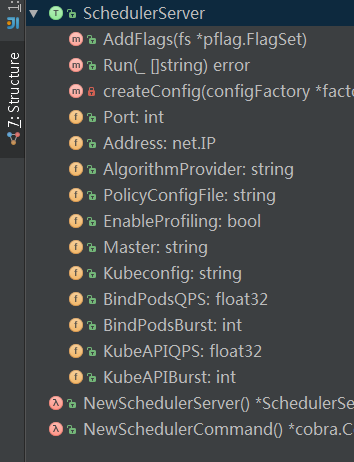
進入這個文件后,重點看的就是數據結構和方法:
SchedulerServer這個結構存放了一堆配置信息,裸的,可以看到里面幾個成員變量都是基本類型,int, string等
上一層調用的2個方法的主要目的是倒騰配置信息,從命令行參數和配置文件kubeconfig獲取信息后
Run方法啟動一些性能、健康的信息在http接口,然后實際調用的是下一層。
kubeconfig是為了kubeclient服務的。
還用了一個工廠模式,按照名稱AlgorithmProvider來創建具體算法的調度器。
再下一層的入口在:
sched := scheduler.New(config) sched.Run()
對于這層的問題是:
問5.幾個限流是怎么實現的?QPS和Brust有什么區別?
問6.算法提供者AlgorithmProvider是怎么被抽象出來的?需要完成什么事情?
答5.在翻了限流的代碼后,發現來自于kubernetes\Godeps\_workspace\src\github.com\juju\ratelimit,實現的是一個令牌桶的算法,burst指的是在n個請求內保持qps平均值的度量。詳見這篇文章
kubernetes\plugin\pkg\scheduler\scheduler.go
答2:在這里我看到了輸出的數據結構為:
b := &api.Binding{
ObjectMeta: api.ObjectMeta{Namespace: pod.Namespace, Name: pod.Name},
Target: api.ObjectReference{
Kind: "Node",
Name: dest,
},
}這個文件最重要的數據結構是:
type Config struct {
// It is expected that changes made via modeler will be observed
// by NodeLister and Algorithm.
Modeler SystemModeler
NodeLister algorithm.NodeLister
Algorithm algorithm.ScheduleAlgorithm
Binder Binder
// Rate at which we can create pods
// If this field is nil, we don't have any rate limit.
BindPodsRateLimiter util.RateLimiter
// NextPod should be a function that blocks until the next pod
// is available. We don't use a channel for this, because scheduling
// a pod may take some amount of time and we don't want pods to get
// stale while they sit in a channel.
NextPod func() *api.Pod
// Error is called if there is an error. It is passed the pod in
// question, and the error
Error func(*api.Pod, error)
// Recorder is the EventRecorder to use
Recorder record.EventRecorder
// Close this to shut down the scheduler.
StopEverything chan struct{}
}數據結構是什么?數據結構就是舞臺上的角色,而函數方法就是這些角色之間演出的一幕幕戲。對象是有生命的,從創建到數據流轉,從產生到消亡。而作為開發者來說,首先是搞懂這些人物設定,是關公還是秦瓊,是紅臉還是黑臉?看懂了人,就看懂了戲。
這段代碼里面,結合下面的方法,我可以得出這么幾個印象:
Modeler是個所有node節點的模型,但具體怎么做pod互斥還不懂
NodeLister是用來列表節點的
Algorithm是用來做調度的
Binder是用來做實際綁定操作的
其他的,Ratelimiter說了是做限流,其他的都不是很重要,略過
問7.結合觀看了modeler.go之后,發現這是在綁定后處理的,所謂的assuemPod,就是把綁定的pod放到一個隊列里面去,不是很理解為什么這個互斥操作是放在bind之后做?
問8.Binder是怎么去做綁定操作的?
下一層入口:
dest, err := s.config.Algorithm.Schedule(pod, s.config.NodeLister)
kubernetes\plugin\pkg\scheduler\generic_scheduler.go
在調到這一層的時候,我發現自己走過頭了,上面s.config.Algorithm.Schedule并不會直接調用generic_scheduler.go。對于一門面向對象的語言來說,最后的執行可能是一層接口套一層接口,而接口和實現的分離也造成了當你閱讀到某個地方之后就無法深入下去。或者說,純粹的自頂向下的閱讀方式并不適合面向對象的代碼。所以,目前我的閱讀方法開始變成了碎片式閱讀,先把整個代碼目錄樹給看一遍,然后去最有可能解釋我心中疑問的地方去尋找答案,然后一片片把真相拼合起來。
問9.generic_scheduler.go是怎么和scehduler.go產生關系的?
這是代碼目錄樹:
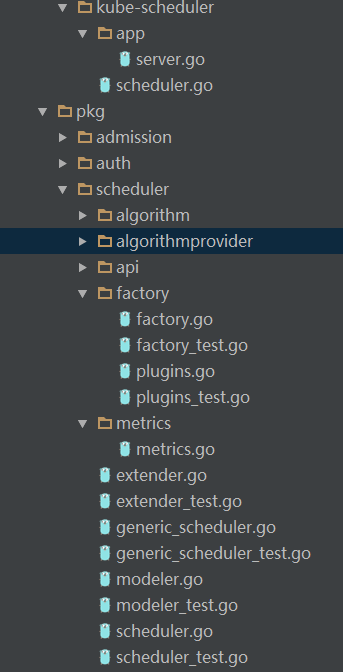
從目錄樹中,可以看出調度算法的目錄在algrorithem和algrorithemprovider里面,而把對象組裝在一起的關鍵源代碼是在:
答8.Binder的操作其實很簡單,就是把pod和node的兩個字段放到http請求中發送到apiserver去做綁定,這也和系統的整體架構是一致的
factory的最大作用,就是從命令行參數中獲取到--algorithm和--policy-config-file來獲取到必要算法名稱和調度策略,來構建Config,Config其實是調度程序的核心數據結構。schduler這整個程序做的事情可以概括為:獲取配置信息——構建Config——運行Config。這個過程類似于java中的sping組裝對象,只不過在這里是通過代碼顯式進行的。從裝配工廠中,我們看到了關鍵的一行
algo := scheduler.NewGenericScheduler(predicateFuncs, priorityConfigs, extenders, f.PodLister, r)
這樣就把我上面的問9解答了
答9.scheduler.go是形式,generic_scheduler.go是內容,通過factory組裝
也解答了問6
答6.factoryProvider僅僅是一個算法注冊的鍵值對表達地,大部分的實現還是放在generic_scheduler里面的
這就涉及到調度的核心邏輯,就2行
filteredNodes, failedPredicateMap, err := findNodesThatFit().... priorityList, err := PrioritizeNodes()...
先過濾,尋找不引起沖突的合法節點
從合法節點中去打分,尋找分數最高的節點去做綁定
為了避免分數最高的節點被幾次調度撞車,從分數高的隨機找一個出來
這里我就不詳細敘述細節了,讀者可以按照我的路子去自己尋找答案。
以上是“如何閱讀kubernetes源代碼”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





