溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Spark集群怎么部署”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
本文將接受 Spark 集群的部署方式,包括無 HA、Spark Standalone HA 和 基于 ZooKeeper 的 HA 三種。
環境:CentOS6.6 、 JDK1.7.0_80 、 關閉防火墻 、 配置好 hosts 和 SSH 免密碼、Spark1.5.0
一. 無 HA 方式
1. 主機名與角色的對應關系:
node1.zhch Master
node2.zhch Slave
node3.zhch Slave
2. 解壓 Spark 部署包(可以從官網直接下載部署包,也可從官網下載源碼再
編譯出部署包)
[yyl@node1 program]$ tar -zxf spark-1.5.0-bin-2.5.2.tgz
3. 修改配置文件
[yyl@node1 program]$ cd spark-1.5.0-bin-2.5.2/conf/ [yyl@node1 conf]$ cp slaves.template slaves [yyl@node1 conf]$ vim slaves node2.zhch node3.zhch [yyl@node1 conf]$ cp spark-env.sh.template spark-env.sh [yyl@node1 conf]$ vim spark-env.sh export JAVA_HOME=/usr/lib/java/jdk1.7.0_80 export SPARK_MASTER_IP=node1.zhch export SPARK_MASTER_PORT=7077 export SPARK_WORKER_CORES=1 export SPARK_WORKER_INSTANCES=1 export SPARK_WORKER_MEMORY=1g
說明:
SPARK_MASTER_IP :Master節點地址
SPARK_MASTER_PORT :Master端口號
SPARK_WORKER_CORES :每個worker的核心數,一般設置成主機的CPU核心數
SPARK_WORKER_INSTANCES :每臺主機上運行的worker數量
SPARK_WORKER_MEMORY :Spark作業允許使用的內存總量(每個作業自己的內存空間由屬性 spark.executor.memory 決定)
4. 分發 Spark
[yyl@node1 program]$ scp -rp spark-1.5.0-bin-2.5.2 node2.zhch:~/program/
[yyl@node1 program]$ scp -rp spark-1.5.0-bin-2.5.2 node3.zhch:~/program/
5. 啟動與停止命令
./sbin/start-master.sh - 啟動 Master
./sbin/start-slaves.sh - 啟動所有的 Slave
./sbin/start-slave.sh spark://IP:PORT - 啟動本機的 Slave
./sbin/start-all.sh - 啟動所有的 Master 和 Slave
./sbin/stop-master.sh - 停止 Master
./sbin/stop-slaves.sh - 停止所有的 Slave
./sbin/stop-slave.sh - 停止本機的 Slave
./sbin/stop-all.sh - 停止所有的 Master 和 Slave
./bin/spark-shell --master spark://IP:PORT - 運行 Spark Shell
./bin/spark-submit --class packageName.MainClass --master spark://IP:PORT path/jarName.jar - 提交作業
二. Spark Standalone HA
只需要在無 HA 的基礎上修改 conf/spark-env.sh 文件,添加如下一行即可:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/home/yyl/program/spark-1.5.0-bin-2.5.2/recovery"
說明:
spark.deploy.recoveryMode -- FILESYSTEM,表示開啟基于文件系統的單節點恢復模式 ,默認為 NONE
spark.deploy.recoveryDirectory -- Spark 保存恢復狀態的目錄
三. 基于 ZooKeeper 的 HA
1. 主機名與角色的對應關系:
node1.zhch Master、ZooKeeper
node2.zhch Master、ZooKeeper
node3.zhch Slave、ZooKeeper
node4.zhch Slave
node5.zhch Slave
2.
安裝 ZooKeeper 集群
3. 配置
與無 HA 模式相比,conf/slaves 文件中仍然是配置所有的 Slave 節點地址;不同的是 conf/spark-env.sh 中 SPARK_MASTER_IP 不用配置,但要增加 SPARK_DAEMON_JAVA_OPTS 配置,內容如下:
export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1.zhch:2181,node2.zhch:2181,node3.zhch:2181 -Dspark.deploy.zookeeper.dir=/spark"
說明:
spark.deploy.recoveryMode -- ZOOKEEPER,表示開啟基于 ZooKeeper 的 HA
park.deploy.zookeeper.url -- ZooKeeper URL
spark.deploy.zookeeper.dir -- ZooKeeper 保存恢復狀態的目錄,缺省為 /spark
配置好 HA 后,由于 master 有多個,在用到 spark url 的地方列出所有的 master,例如:
./bin/spark-shell --master spark://host1:port1,host2:port2,host3:port3
5. 驗證 HA
首先啟動 Zookeeper 集群;然后在 node1 節點上運行 sbin/start-all.sh 命令啟動 Spark 集群。最后使用 jps 命令查看,只在 node1 節點上發現了 Master 進程,而 node2 節點上沒有,這時需要在 node2 節點上使用 sbin/start-master.sh 命令來啟動備 Master 進程,這樣便實現了 Master HA
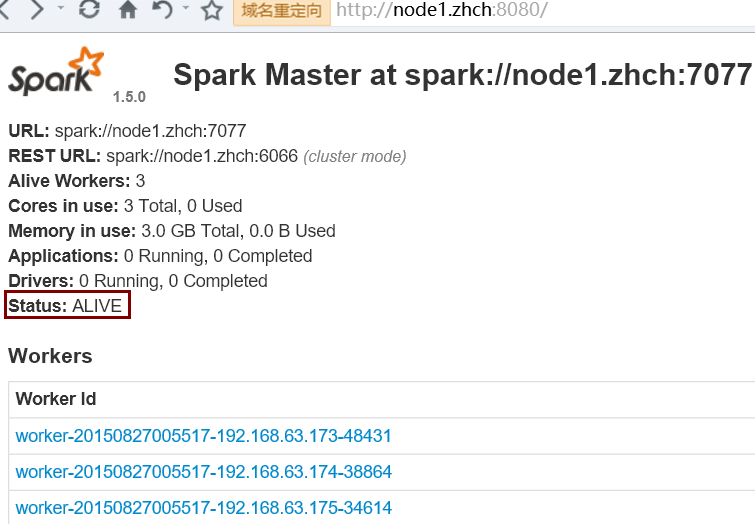
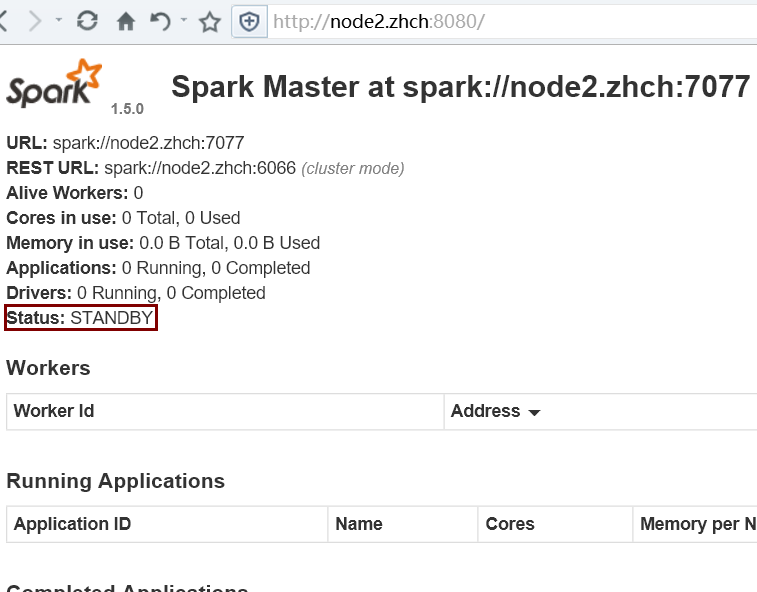
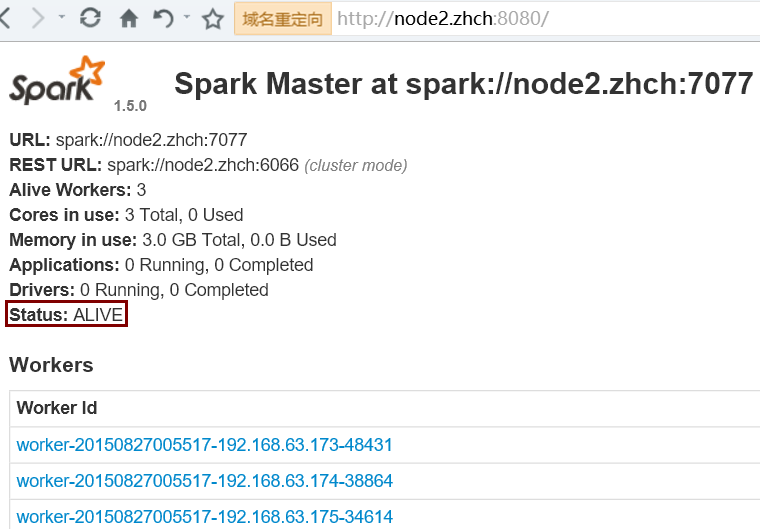
kill 掉 node1 節點上的 master 進程后:
“Spark集群怎么部署”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





