溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關如何使用Cookie模擬登錄瀏覽網頁和資源,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
在實際情況中,很多網站的內容都是需要登錄之后才能看到,如此我們就需要進行模擬登錄,使用登錄后的狀態進行爬取。這里就需要使用到Cookie。
使用Cookie進行模擬登錄
現在大多數的網站都是使用Cookie跟蹤用戶的登錄狀態,一旦網站驗證了登錄信息,就會將登錄信息保存在瀏覽器的cookie中。網站會把這個cookie作為驗證的憑據,在瀏覽網站的頁面是返回給服務器。
因為cookie是保存在本地的,自然cookie就可以進行篡改和偽造,暫且不表,我們先來看看Cookie長什么樣子。
打開網頁調試工具,隨便打開一個網頁,在“network”選項卡,打開一個鏈接,在headers里面: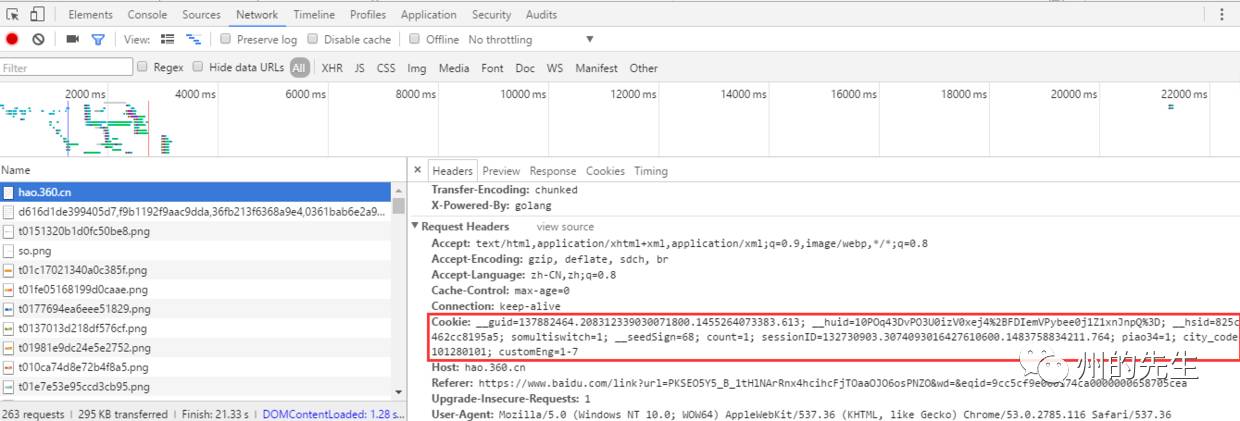
我們復制出來看看:
__guid=137882464.208312339030071800.1455264073383.613; __huid=10POq43DvPO3U0izV0xej4%2BFDIemVPybee0j1Z1xnJnpQ%3D; __hsid=825c7462cc8195a5; somultiswitch=1; __seedSign=68; count=1; sessionID=132730903.3074093016427610600.1483758834211.764; piao34=1; city_code=101280101; customEng=1-7
由一個個鍵值對組成。
接下來,我們以看看豆的一本書籍的詳情頁為例,講解一下Cookie的使用。
看看豆是一個電子書下載網站,自己Kindle上的書多是從這上面找尋到的。
示例網址為:https://kankandou.com/book/view/22353.html
正常情況下,未登錄用戶是看不到下載鏈接的,比如這樣:
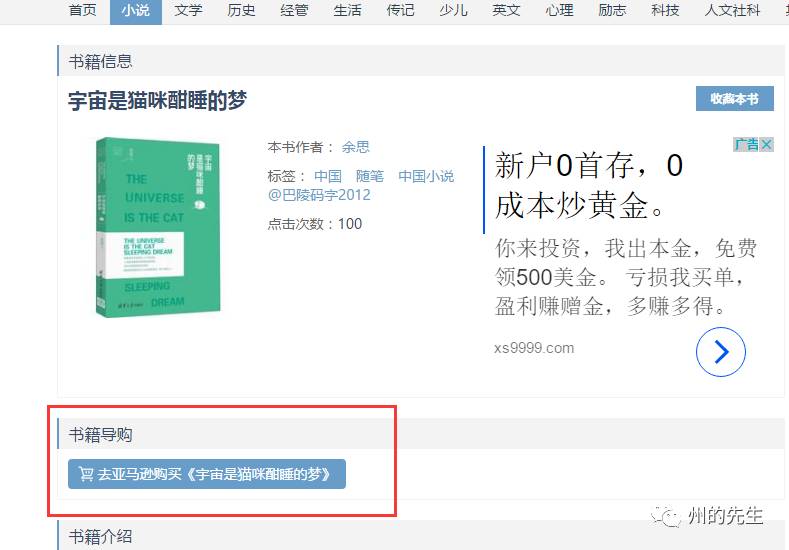
隱藏了書籍的下載鏈接。
其頭信息如下: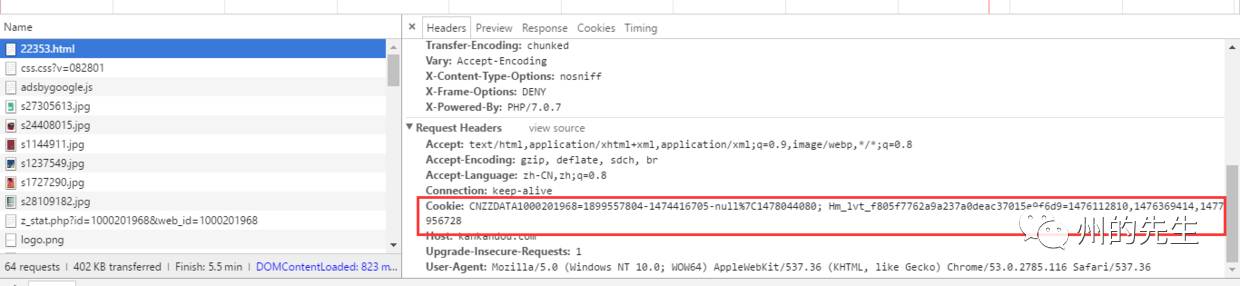
我們再看看登錄之后的頁面: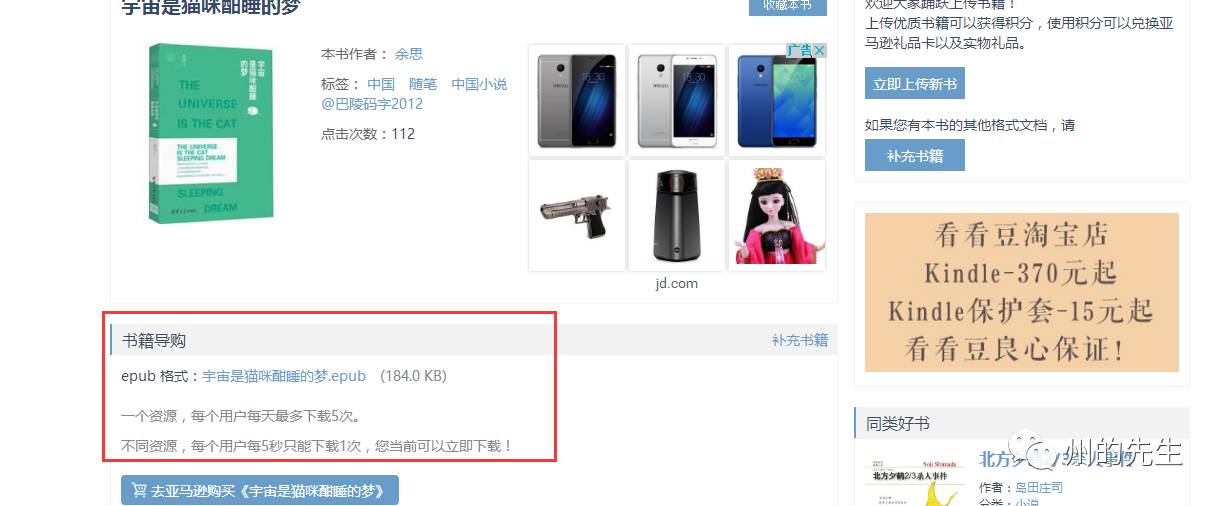
下載鏈接已經顯示出來了,我們看看頭信息的Cookie部分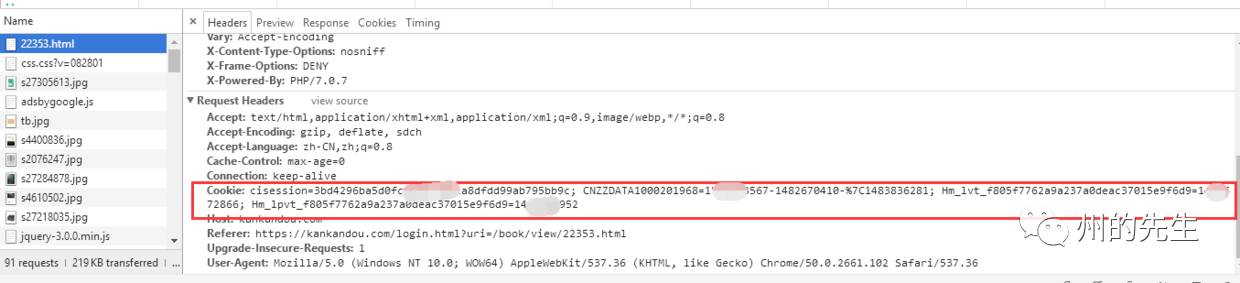
很明顯地與之前未登錄狀態下的Cookie有區別。
接下來,我們對示例網址進行HTTP請求:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
url = 'https://kankandou.com/book/view/22353.html'wbdata = requests.get(url).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)結果如下:
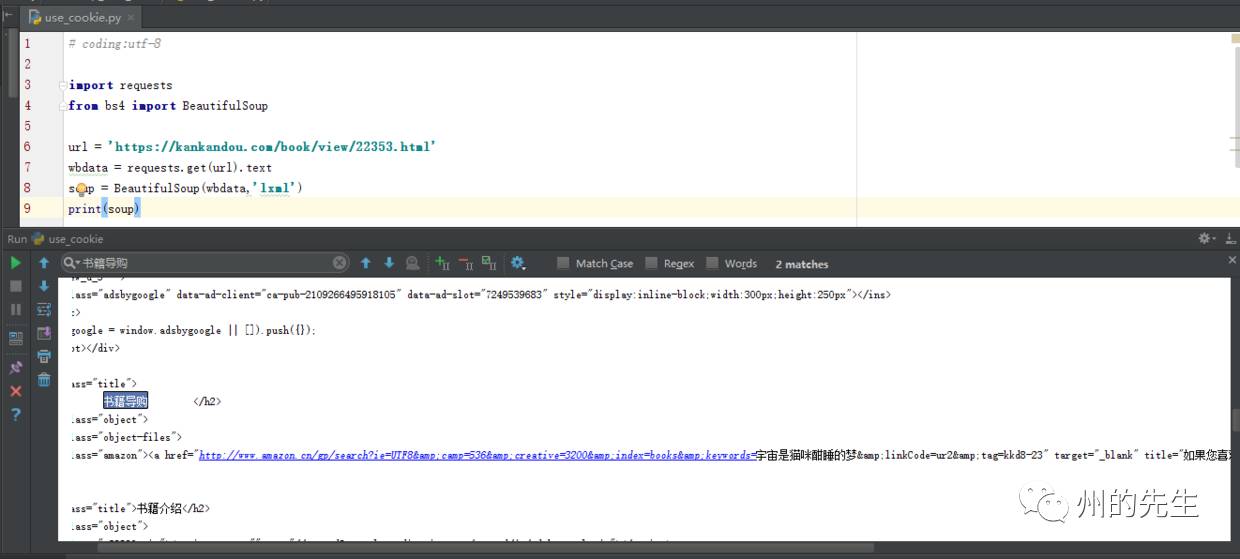
我們從中找到下載鏈接存在的欄目“書籍導購”的HTML代碼:
<h3 class="title">書籍導購</h3><div class="object"><div class="object-files"><div class="amazon"><a href="http://www.amazon.cn/gp/search?ie=UTF8&camp=536&creative=3200&index=books&keywords=宇宙是貓咪酣睡的夢&linkCode=ur2&tag=kkd8-23" target="_blank" title="如果您喜歡《宇宙是貓咪酣睡的夢》這本書,請去亞馬遜購買。">去亞馬遜購買《宇宙是貓咪酣睡的夢》</a></div></div></div>
如同我們在未登錄狀態使用瀏覽器訪問這個網址一樣,只顯示了亞馬遜的購買鏈接,而沒有電子格式的下載鏈接。
我們嘗試使用以下登錄之后的Cookie:
使用Cookie有兩種方式,
1、直接在header頭部寫入Cookie
完整代碼如下:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
cookie = '''cisession=19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60;CNZZDATA1000201968=1815846425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483922031;Hm_lvt_f805f7762a9a237a0deac37015e9f6d9=1482722012,1483926313;Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9=1483926368'''header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36',
'Connection': 'keep-alive',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Cookie': cookie}
url = 'https://kankandou.com/book/view/22353.html'wbdata = requests.get(url,headers=header).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)上述代碼返回了對頁面的響應,
我們搜索響應的代碼,
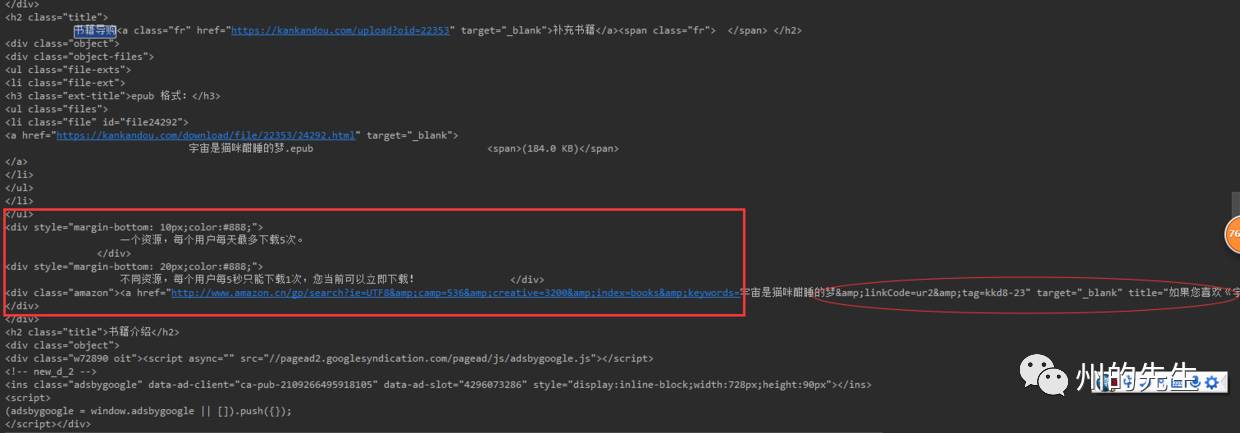
紅色橢圓的部分與未帶Cookie訪問是返回的HTML一致,為亞馬遜的購買鏈接,
紅色矩形部分則為電子書的下載鏈接,這是在請求中使用的Cookie才出現的
對比實際網頁中的模樣,與用網頁登錄查看的顯示頁面是一致的。
功能完成。接下來看看第二種方式
2、使用requests的cookies參數
完整代碼如下:
# coding:utf-8
import requests
from bs4 import BeautifulSoup
cookie = {"cisession":"19dfd70a27ec0eecf1fe3fc2e48b7f91c7c83c60",
"CNZZDATA100020196":"1815846425-1478580135-https%253A%252F%252Fwww.baidu.com%252F%7C1483922031",
"Hm_lvt_f805f7762a9a237a0deac37015e9f6d9":"1482722012,1483926313",
"Hm_lpvt_f805f7762a9a237a0deac37015e9f6d9":"1483926368"}
url = 'https://kankandou.com/book/view/22353.html'
wbdata = requests.get(url,cookies=cookie).text
soup = BeautifulSoup(wbdata,'lxml')
print(soup)如此獲取到的也是登錄后顯示的HTML:
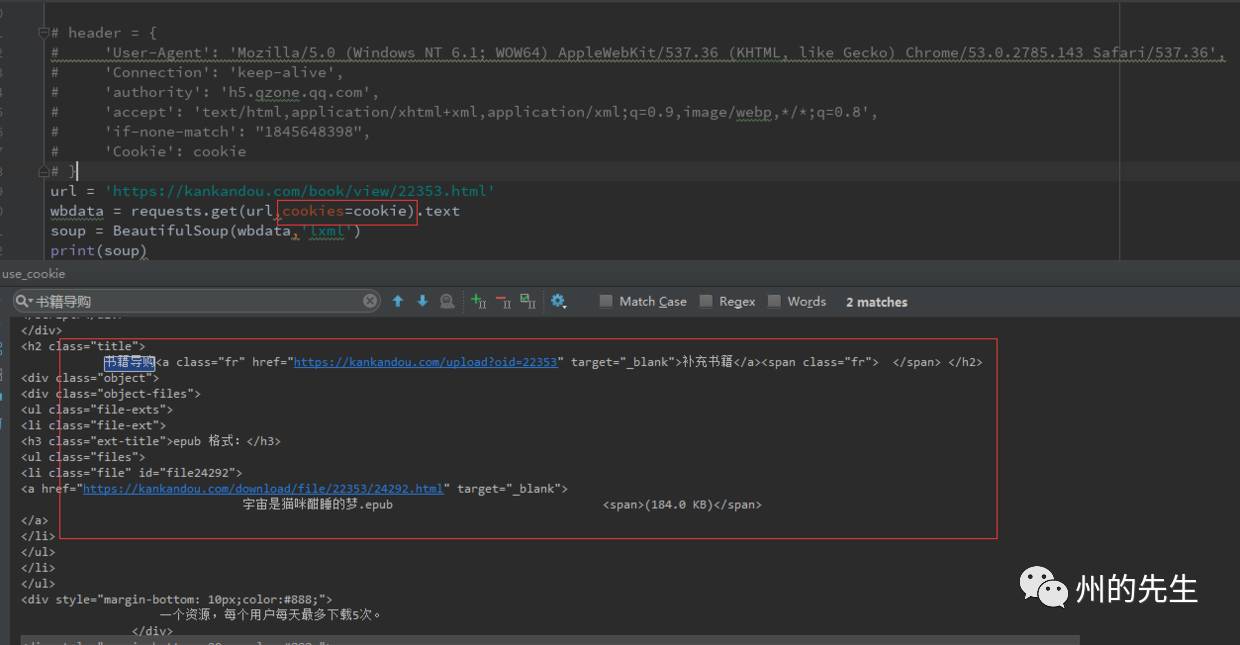
這樣,我們就輕松的使用Cookie獲取到了需要登錄驗證后才能瀏覽到的網頁和資源了。
關于Cookie如何獲取,手動復制是一種辦法,通過代碼獲取,需要使用到Selenium。
關于如何使用Cookie模擬登錄瀏覽網頁和資源就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





