溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Storm的Transactional Topology怎么配置”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Storm的Transactional Topology怎么配置”吧!
○ 是一個每個tuple僅被處理一次的框架
○ 由Storm0.7引入,于Storm0.9被棄用,被triden取而代之
○ 底層依靠spout\bolt\topology\stream抽象的一個特性
基于Storm處理tuple失敗時會重發(replay),如何確保replay的記錄不被重復記錄,換句話說就是如何保證tuple僅被處理一次,這就依賴于一個稱作強順序性的思想。
強順序性:每個tuple與一個transaction id相關聯,transaction id實際就是一個數字,每一個tuple都有一個按照順序的transaction id(例如:tuple1的transaction id 為 1,tuple2的transaction id 為 2,...以此類推),只有當前的tuple處理并存儲完畢,下一個tuple(處于等待狀態)才能進行存儲,tuple被存儲時連同transaction id一并存儲,此時考慮兩種情況:
tuple處理失敗時:重新發送一個和原來一模一樣的transaction id
tuple處理成功時:發送的transaction id會和存儲的transaction id對比,如果不存在transaction id,表示第一次記錄,直接存儲;如果發現存在,則忽略該tuple。
這一思想是由Kafka開發者提出來的。
基于上面的一個優化,將一批tuple直接打包成一個batch,然后分配一個transaction id ,讓batch與batch之間保證強順序性,且batch內部的tuples可以并行。
兩個步驟:
1、并行計算batch中的tuple數量
2、batch強順序性存儲
在batch強順序性存儲的同時讓其他等待存儲的batch內部進行并行運算,不必等到下一個batch存儲時才進行內部運算。
在Storm上面的兩個步驟表現為processing階段和commit階段。
使用Transactional Topology時,storm提供如下操作:
將需要處理的狀態如:transaction id 、batch meta等狀態信息放在zookeeper
指定某個時間段執行processing操作和commit操作
storm使用acking框架自動檢測batch被成功或失敗處理,然后相應的重發(replay)
通過對普通的bolt進行包裝,提供一套對batch處理的API、協調工作(即某個時刻處理某個processing或者commit),并且storm會自動清除中間結果
Transactional Topology是可以完全重發一個特定batch的消息隊列系統,在 Kakfa中正是有這樣的需求,為此Storm在storm-contrib里面的Storm-Kafka中為Kafka實現了一個事務性的spout。
計算來自輸入流中tuple的個數
MemoryTransactionalSpout spout = new MemoryTransactionalSpout(DATA, new Fields("word"), PARTITION_TAKE_PER_BATCH);
TransactionalTopologyBuilder builder = new TransactionalTopologyBuilder("global-count", "spout", spout, 3);
builder.setBolt("partial-count", new BatchCount(), 5)
.shuffleGrouping("spout");
builder.setBolt("sum", new UpdateGlobalCount())
.globalGrouping("partial-count");○ 通過TransactionalTopologyBuilder類構建Transactional
參數:
Transaction ID:transactional topology的ID,在zookeeper中用于保存進度狀態,重啟topology時可以直接從執行的進度開始執行而不用重頭到尾又執行一遍
Spout ID:位于整個Topology的Spout的ID
Spout Object:Transactional中的Spout對象
Spout:Trasactional中的Spout的并行數
○ MemoryTransactionalSpout用于從一個內存變量中讀取數據
DATA:數據
tuple fields:字段
tupleNum:在batch中最大的tuple數
○ Bolts
第一個Bolt采用隨機分組的方式隨機分發到各個task
public static class BatchCount extends BaseBatchBolt {
Object _id;
BatchOutputCollector _collector;
int _count = 0;
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, Object id) {
_collector = collector;
_id = id;
}
@Override
public void execute(Tuple tuple) {
_count++;
}
@Override
public void finishBatch() {
_collector.emit(new Values(_id, _count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "count"));
}
}BatchBolt對象運行在BatchBoltExecutor中,BatchBoltExecutor負責BatchBolt對象的創建和清理
BatchBolt的ID在context對象中,該ID是一個TransactionAttempt對象.
BatchBolt在DRPC中也可以使用,只是txid類型不一樣,如果在Transactional Topology中使用BatchBolt,可以繼承BaseTransactionalBolt.
在Tranasctional Topology中所有的Tuple都必須以TransactionAttempt作為第一個field,然后storm才能根據該field判斷Tuple所屬的BatchBolt,所以在發射Tuple必須滿足此條件。
TransactionAttempt對象中有兩個屬性:
transaction id:強順序性,無論重發多少次都是一樣的數字
attempt id:對每一個Batch標識的ID,每次重發都其值不一致,通過該ID可以區分每次重發的Tuple的不同版本
第二個Bolt使用GlobalGrouping匯總batch中的tuple數
public static class UpdateGlobalCount extends BaseTransactionalBolt implements ICommitter {
TransactionAttempt _attempt;
BatchOutputCollector _collector;
int _sum = 0;
@Override
public void prepare(Map conf, TopologyContext context, BatchOutputCollector collector, TransactionAttempt attempt) {
_collector = collector;
_attempt = attempt;
}
@Override
public void execute(Tuple tuple) {
_sum+=tuple.getInteger(1);
}
@Override
public void finishBatch() {
Value val = DATABASE.get(GLOBAL_COUNT_KEY);
Value newval;
if(val == null || !val.txid.equals(_attempt.getTransactionId())) {
newval = new Value();
newval.txid = _attempt.getTransactionId();
if(val==null) {
newval.count = _sum;
} else {
newval.count = _sum + val.count;
}
DATABASE.put(GLOBAL_COUNT_KEY, newval);
} else {
newval = val;
}
_collector.emit(new Values(_attempt, newval.count));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("id", "sum"));
}
}ICommitter接口:實現該接口的Bolt會在commit階段調用finishBatch方法,該方法的調用會按照強順序性,此外還可以使用TransactionalTopologyBuilder的setCommiterBolt來添加Bolt實現和該接口一樣的功能。
executor方法:在processing階段和commit階段都可以執行。
關于更多的transactional topology例子可以看看storm-starter中的TransactionalWords類,該例子會在一個事務中更新多個數據庫
BaiscBolt:該Bolt不跟batch中的tuples交互,僅基于單個傳來的tuple和產生新的tuple
BatchBolt:該Bolt處理batch中的tuples,對于每一個tuple調用executor方法,整個batch完成時調用finishBatch方法
被Committer標記的Bolt:在commit階段才調用finishBatch方法,commit具有強順序性,標記Bolt為commit階段執行finishBatch的方法有兩種:1、實現ICommiter接口。2、TransactionalTopologyBuilder的setCommiterBolt來添加Bolt。
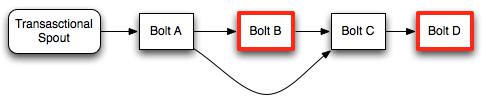
紅色輪廓的Bolt被標記過為commit
Spout向Bolt A發送整個Batch
Bolt A處理完整個Batch之后調用finishBatch方法分別向Bolt B 和 Bolt C發送Batch
Bolt B接收到Bolt A傳遞過來的tuple進行處理(此時還尚未處理完畢)不會調用finishBatch方法
Bolt C接口Bolt A傳遞的tuple,盡管處理完Bolt A傳遞來的tuple,但是由于Bolt B還尚未commit,所以Bolt C處于等待Bolt B commit的狀態,不會調用finishBatch方法
Bolt D接收來自Bolt C調用executor方法時發送的所有tuple
此時一旦Bolt B進行commit進行finishBatch操作,那么Bolt C就會確認接收到所有Bolt B的tuple,Bolt C也調用finishBatch方法,最終Bolt D也接收到所有來自Bolt C的batch。
在這里盡管Bolt D是一個committer,它在接收到整個batch的tuple之后不需要等待第二個commit信號。因為它是在commit階段接收到的整個batch,它會調用finishBatch來完成整個事務。
注意,當使用transactional topology的時候你不需要顯式地去做任何的acking或者anchoring,storm在背后都做掉了。(storm對transactional topolgies里面的acking機制進行了高度的優化)
在使用普通bolt的時候, 你可以通過調用OutputCollector的fail方法來fail這個tuple所在的tuple樹。Transactional Topology對用戶隱藏了acking框架, 它提供一個不同的機制來fail一個batch(從而使得這個batch被replay):只要拋出一個FailedException就可以了。跟普通的異常不一樣, 這個異常只會導致當前的batch被replay, 而不會使整個進程崩潰掉。
TransactionalSpout接口跟普通的Spout接口完全不一樣。一個TransactionalSpout的實現會發送一批一批(batch)的tuple, 而且必須保證同一批次tuples的transaction id始終一樣。
在transactional topology運行的時候, transactional spout看起來是這樣的一個結構:
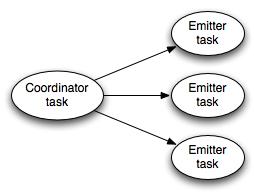
coordinator是一個普通的storm的spout——它一直為事務的batch發射tuple。
Emitter則像一個普通的storm bolt,它負責為每個batch實際發射tuple,emitter以all grouping的方式訂閱coordinator的”batch emit”流。
關于如何實現一個TransactionalSpout的細節可以參見Javadoc
一種常見的TransactionalSpout是那種從多個queue broker讀取數據然后再發射的tuple。比如TransactionalKafkaSpout就是這樣工作的。IPartitionedTransactionalSpout把這些管理每個分區的狀態以保證可以replay的冪等性的工作都自動化掉了。更多可以參考Javadoc。
Transactional Topologies有兩個重要的配置:
Zookeeper:默認情況下,transactional topology會把狀態信息保存在一個zookeeper里面(協調集群的那個)。你可以通過這兩個配置來指定其它的zookeeper:”transactional.zookeeper.servers” 和 “transactional.zookeeper.port“。
同時活躍的batch數量:你必須設置同時處理的batch數量,你可以通過”topology.max.spout.pending” 來指定, 如果你不指定,默認是1。
Transactional Topologies的實現是非常優雅的。管理提交協議,檢測失敗并且串行提交看起來很復雜,但是使用storm的原語來進行抽象是非常簡單的。
1、transactional spout是一個子topology, 它由一個coordinator spout和一個emitter bolt組成。
2、coordinator是一個普通的spout,并行度為1;emitter是一個bolt,并行度為P,使用all分組方式連接到coordinator的“batch”流上。
3、coordinator使用一個acking框架決定什么時候一個batch被成功執行(process)完成,然后去決定一個batch什么時候被成功提交(commit)。
感謝各位的閱讀,以上就是“Storm的Transactional Topology怎么配置”的內容了,經過本文的學習后,相信大家對Storm的Transactional Topology怎么配置這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





