溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
怎么分析消息系統Kafka,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
Kafka是Linkedin于2010年12月份開源的消息系統,它主要用于處理活躍的流式數據。活躍的流式數據在web網站應用中非常常見,這些數據包括網站的pv、用戶訪問了什么內容,搜索了什么內容等。 這些數據通常以日志的形式記錄下來,然后每隔一段時間進行一次統計處理。
傳統的日志分析系統提供了一種離線處理日志信息的可擴展方案,但若要進行實時處理,通常會有較大延遲。而現有的消(隊列)系統能夠很好的處理實時或者近似實時的應用,但未處理的數據通常不會寫到磁盤上,這對于Hadoop之類(一小時或者一天只處理一部分數據)的離線應用而言,可能存在問題。Kafka正是為了解決以上問題而設計的,它能夠很好地離線和在線應用。
2、 設計目標
(1)數據在磁盤上存取代價為O(1)。一般數據在磁盤上是使用BTree存儲的,存取代價為O(lgn)。
(2)高吞吐率。即使在普通的節點上每秒鐘也能處理成百上千的message。
(3)顯式分布式,即所有的producer、broker和consumer都會有多個,均為分布式的。
(4)支持數據并行加載到Hadoop中。
3、 KafKa部署結構
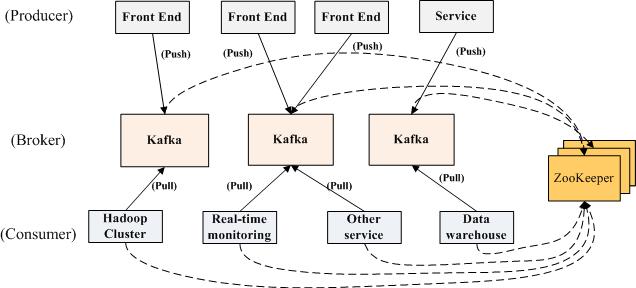
kafka是顯式分布式架構,producer、broker(Kafka)和consumer都可以有多個。Kafka的作用類似于緩存,即活躍的數據和離線處理系統之間的緩存。幾個基本概念:
(1)message(消息)是通信的基本單位,每個producer可以向一個topic(主題)發布一些消息。如果consumer訂閱了這個主題,那么新發布的消息就會廣播給這些consumer。
(2)Kafka是顯式分布式的,多個producer、consumer和broker可以運行在一個大的集群上,作為一個邏輯整體對外提供服務。對于consumer,多個consumer可以組成一個group,這個message只能傳輸給某個group中的某一個consumer.
4、 KafKa關鍵技術點
(1) zero-copy
在Kafka上,有兩個原因可能導致低效:1)太多的網絡請求 2)過多的字節拷貝。為了提高效率,Kafka把message分成一組一組的,每次請求會把一組message發給相應的consumer。 此外, 為了減少字節拷貝,采用了sendfile系統調用。為了理解sendfile原理,先說一下傳統的利用socket發送文件要進行拷貝:
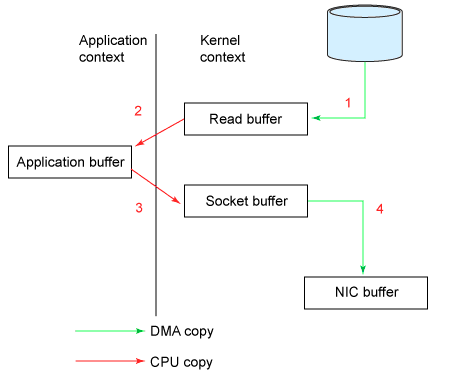
Sendfile系統調用:
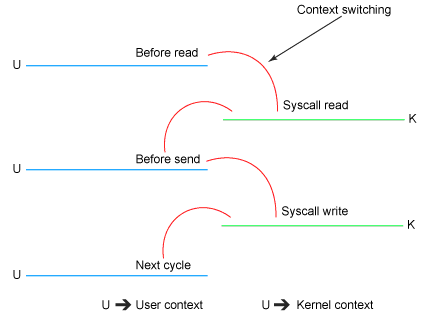
(2) Exactly once message transfer
怎樣記錄每個consumer處理的信息的狀態?在Kafka中僅保存了每個consumer已經處理數據的offset。這樣有兩個好處:1)保存的數據量少 2)當consumer出錯時,重新啟動consumer處理數據時,只需從最近的offset開始處理數據即可。
(3)Push/pull
Producer 向Kafka(push)推數據,consumer 從kafka 拉(pull)數據。
(4)負載均衡和容錯
Producer和broker之間沒有負載均衡機制。
broker和consumer之間利用zookeeper進行負載均衡。所有broker和consumer都會在zookeeper中進行注冊,且zookeeper會保存他們的一些元數據信息。如果某個broker和consumer發生了變化,所有其他的broker和consumer都會得到通知。
看完上述內容,你們掌握怎么分析消息系統Kafka的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





