溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Driver端
Executor端
Driver端初始化
??Driver端主要經過以下步驟,完成初始化操作:
val accum = sparkContext.accumulator(0, “AccumulatorTest”)
val acc = new Accumulator(initialValue, param, Some(name))
Accumulators.register(this)Executor端反序列化得到Accumulator
??反序列化是在調用ResultTask的runTask方式時候做的操作:
// 會反序列化出來RDD和自己定義的function
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)??在反序列化的過程中,會調用Accumulable中的readObject方法:
private def readObject(in: ObjectInputStream): Unit = Utils.tryOrIOException {
in.defaultReadObject()
// value的初始值為zero;該值是會被序列化的
value_ = zero
deserialized = true
// Automatically register the accumulator when it is deserialized with the task closure.
//
// Note internal accumulators sent with task are deserialized before the TaskContext is created
// and are registered in the TaskContext constructor. Other internal accumulators, such SQL
// metrics, still need to register here.
val taskContext = TaskContext.get()
if (taskContext != null) {
// 當前反序列化所得到的對象會被注冊到TaskContext中
// 這樣TaskContext就可以獲取到累加器
// 任務運行結束之后,就可以通過context.collectAccumulators()返回給executor
taskContext.registerAccumulator(this)
}
}注意
Accumulable.scala中的value_,是不會被序列化的,@transient關鍵詞修飾了
@volatile @transient private var value_ : R = initialValue // Current value on master針對傳入function中不同的操作,對應有不同的調用方法,以下列舉幾種(在Accumulator.scala中):
def += (term: T) { value_ = param.addAccumulator(value_, term) }
def add(term: T) { value_ = param.addAccumulator(value_, term) }
def ++= (term: R) { value_ = param.addInPlace(value_, term)}根據不同的累加器參數,有不同實現的AccumulableParam(在Accumulator.scala中):
trait AccumulableParam[R, T] extends Serializable {
/**
def addAccumulator(r: R, t: T): R
def addInPlace(r1: R, r2: R): R
def zero(initialValue: R): R
}不同的實現如下圖所示: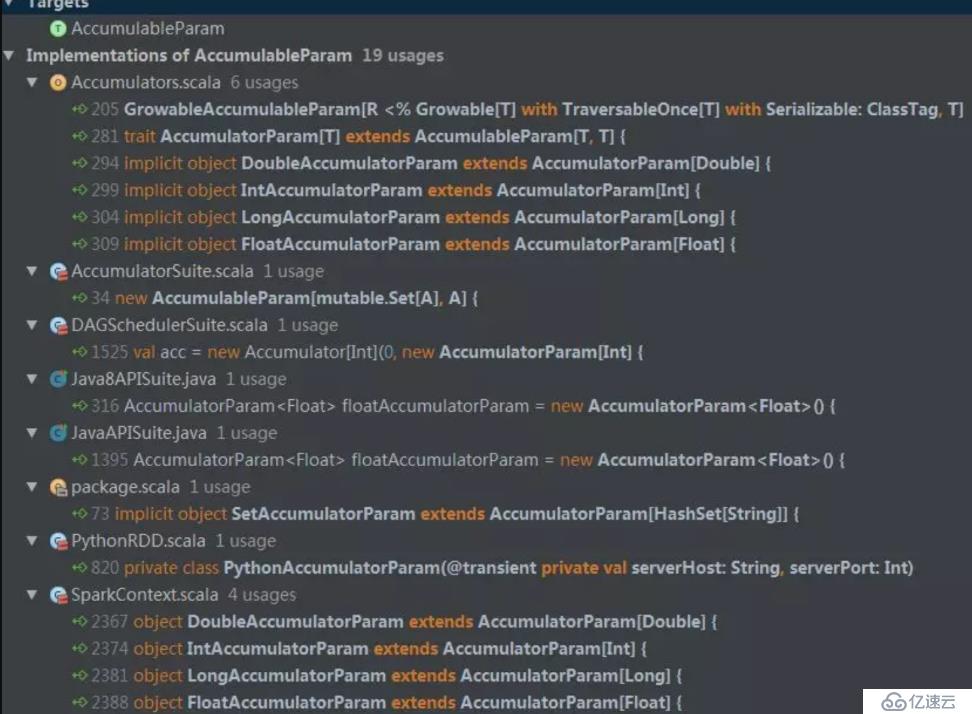
以IntAccumulatorParam為例:
implicit object IntAccumulatorParam extends AccumulatorParam[Int] {
def addInPlace(t1: Int, t2: Int): Int = t1 + t2
def zero(initialValue: Int): Int = 0
}我們發現IntAccumulatorParam實現的是trait AccumulatorParam[T]:
trait AccumulatorParam[T] extends AccumulableParam[T, T] {
def addAccumulator(t1: T, t2: T): T = {
addInPlace(t1, t2)
}
}在各個節點上的累加操作完成之后,就會緊跟著返回更新之后的Accumulators的value_值
在Task.scala中的run方法,會執行如下:
// 返回累加器,并運行task
// 調用TaskContextImpl的collectAccumulators,返回值的類型為一個Map
(runTask(context), context.collectAccumulators())在Executor端已經完成了一系列操作,需要將它們的值返回到Driver端進行聚合匯總,整個順序如圖累加器執行流程: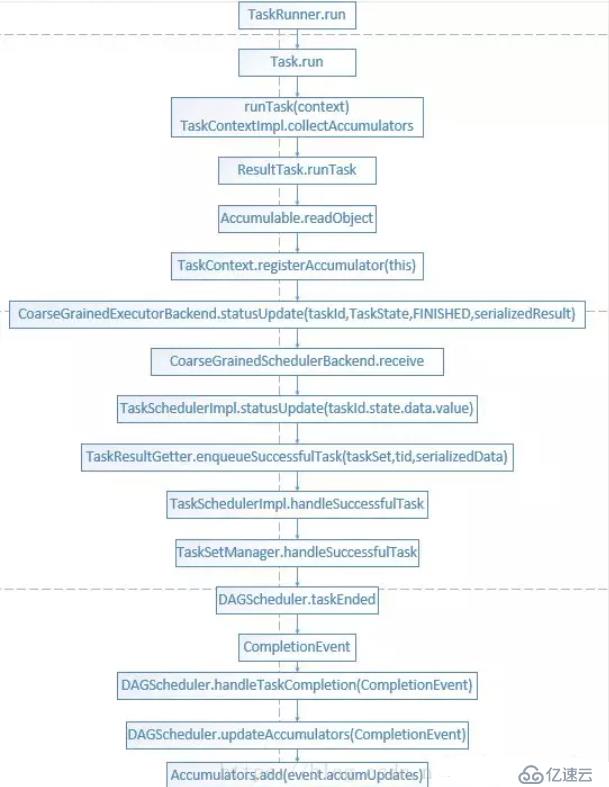
根據執行流程,我們可以發現,在執行完collectAccumulators方法之后,最終會在DAGScheduler中調用updateAccumulators(event),而在該方法中會調用Accumulators的add方法,從而完成聚合操作:
def add(values: Map[Long, Any]): Unit = synchronized {
// 遍歷傳進來的值
for ((id, value) <- values) {
if (originals.contains(id)) {
// Since we are now storing weak references, we must check whether the underlying data
// is valid.
// 根據id從注冊的Map中取出對應的累加器
originals(id).get match {
// 將值給累加起來,最終將結果加到value里面
// ++=是被重載了
case Some(accum) => accum.asInstanceOf[Accumulable[Any, Any]] ++= value
case None =>
throw new IllegalAccessError("Attempted to access garbage collected Accumulator.")
}
} else {
logWarning(s"Ignoring accumulator update for unknown accumulator id $id")
}
}
}通過accum.value方法可以獲取到累加器的值
至此,累加器執行完畢。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





