溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
為什么程序員喜歡用大量的if else而偏不用switch,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
說來也是巧最近在看 Dubbo 源碼,然后發現了一處很奇怪的代碼,剛好和這個 switch 和 if else 有關!
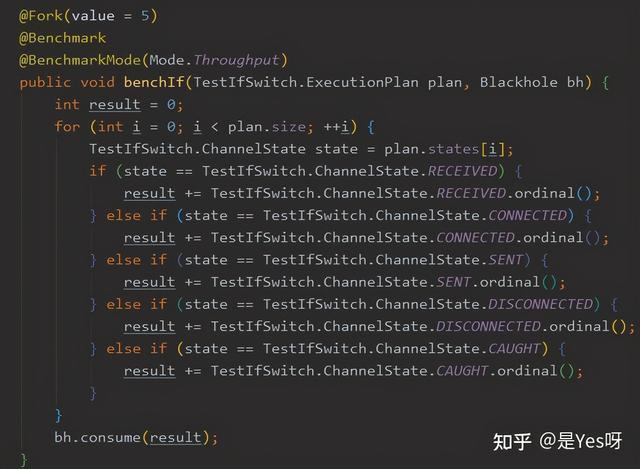
讓我們來看一下這段代碼,它屬于 ChannelEventRunnable,這個 runnable 是 Dubbo IO 線程創建,將此任務扔到業務線程池中處理.

看到沒,把 state == ChannelState.RECEIVED 拎出來獨立一個 if,而其他的 state 還是放在 switch 里面判斷。

我當時腦子里就來回掃描,想想這個到底有什么花頭,奈何知識淺薄一臉懵逼。
于是就開始了一波探險之旅!
遇到問題當然是問搜索引擎了,一般而言我會同時搜索各大引擎,咱這也不說誰比誰好,反正有些時候度娘還是不錯的,比如這次搜索度娘給的結果比較靠前,google 比較靠后。
一般搜索東西我都喜歡先在官網上搜,找不到了再放開搜,所以先這么搜 site:xxx.com key。

你看這就有了,完美啊!
我們先來看看官網的這篇博客怎么說的,然后再詳細地分析一波。
現代 CPU 都支持分支預測 (branch prediction) 和指令流水線 (instruction pipeline),這兩個結合可以極大提高 CPU 效率。對于簡單的 if 跳轉,CPU 是可以比較好地做分支預測的。但是對于 switch 跳轉,CPU 則沒有太多的辦法。 switch 本質上是根據索引,從地址數組里取地址再跳轉。
也就是說 if 是跳轉指令,如果是簡單的跳轉指令的話 CPU 可以利用分支預測來預執行指令,而 switch 是要先根據值去一個類似數組結構找到對應的地址,然后再進行跳轉,這樣的話 CPU 預測就幫不上忙了。
然后又因為一個 channel 建立了之后,超過99.9%情況它的 state 都是 ChannelState.RECEIVED,因此就把這個狀態給挑出來,這樣就能利用 CPU 分支預測機制來提高代碼的執行效率。
并且還給出了 Benchmark 的代碼,就是通過隨機生成 100W 個 state,并且 99.99% 是 ChannelState.RECEIVED,然后按照以下兩種方式來比一比(這 benchSwitch 官網的例子名字打錯了,我一開始沒發現后來校對文章才發現)。

雖然博客也給出了它的對比結果,但是我還是本地來跑一下看看結果如何,其實 JMH 不推薦在 ide 里面跑,但是我懶,直接 idea 里面跑了。

從結果來看確實通過 if 獨立出來代碼的執行效率更高(注意這里測的是吞吐),博客還提出了這種技巧可以放在性能要求嚴格的地方,也就是一般情況下沒必要這樣特殊做。
至此我們已經知道了這個結論是對的,不過我們還需要深入分析一波,首先得看看 if 和 switch 的執行方式到底差別在哪里,然后再看看 CPU 分支預測和指令流水線的到底是干啥的,為什么會有這兩個東西?
我們先簡單來個小 demo 看看 if 和 switch 的執行效率,其實就是添加一個全部是 if else 控制的代碼, switch 和 if + switch 的不動,看看它們之間對比效率如何(此時還是 RECEIVED 超過99.9%)。
來看一下執行的結果如何:

好家伙,我跑了好幾次,這全 if 的比 if + switch 強不少啊,所以是不是源碼應該全改成 if else 的方式,你看這吞吐量又高,還不會像現在一下 if 一下又 switch 有點不倫不類的樣子。
我又把 state 生成的值改成隨機的,再來跑一下看看結果如何:

我跑了多次還是 if 的吞吐量都是最高的,怎么整這個全 if 的都是最棒滴。
在我的印象里這個 switch 應該是優于 if 的,不考慮 CPU 分支預測的話,單從字節碼角度來說是這樣的,我們來看看各自生成的字節碼。
先看一下 switch 的反編譯,就截取了關鍵部分。

也就是說 switch 生成了一個 tableswitch,上面的 getstatic 拿到值之后可以根據索引直接查這個 table,然后跳轉到對應的行執行即可,也就是時間復雜度是 O(1)。
比如值是 1 那么直接跳到執行 64 行,如果是 4 就直接跳到 100 行。
關于 switch 還有一些小細節,當 swtich 內的值不連續且差距很大的時候,生成的是 lookupswitch,按網上的說法是二分法進行查詢(我沒去驗證過),時間復雜度是 O(logn),不是根據索引直接能找到了,我看生成的 lookup 的樣子應該就是二分了,因為按值大小排序了。

還有當 switch 里面的值不連續但是差距比較小的時候,還是會生成 tableswtich 不過填充了一些值,比如這個例子我 switch 里面的值就 1、3、5、7、9,它自動填充了2、4、6、8 都指到 default 所跳的行。

讓我們再來看看 if 的反編譯結果:
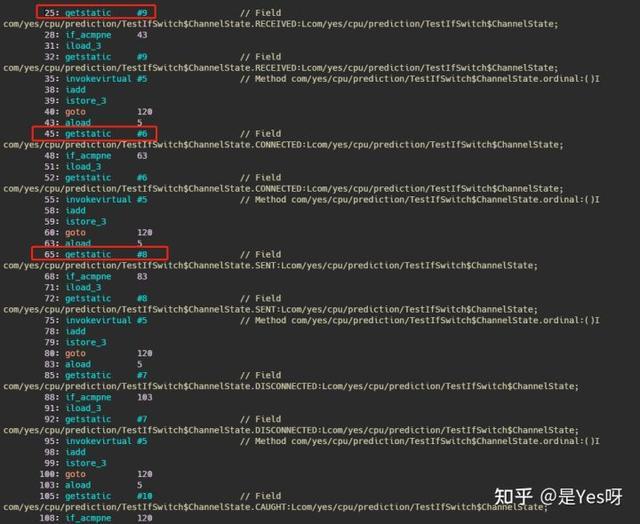
可以看到 if 是每次都會取出變量和條件進行比較,而 switch 則是取一次變量之后查表直接跳到正確的行,從這方面來看 switch 的效率應該是優于 if 的。當然如果 if 在第一次判斷就過了的話也就直接 goto 了,不會再執行下面的哪些判斷了。
所以從生成的字節碼角度來看 switch 效率應該是大于 if 的,但是從測試結果的角度來看 if 的效率又是高于 switch 的,不論是隨機生成 state,還是 99.99% 都是同一個 state 的情況下。
首先 CPU 分支預測的優化是肯定的,那關于隨機情況下 if 還是優于 switch 的話這我就有點不太確定為什么了,可能是 JIT 做了什么優化操作,或者是隨機情況下分支預測成功帶來的效益大于預測失敗的情形?
難道是我枚舉值太少了體現不出 switch 的效果?不過在隨機情況下 switch 也不應該弱于 if 啊,我又加了 7 個枚舉值,一共 12 個值又測試了一遍,結果如下:

好像距離被拉近了,我看有戲,于是我背了波 26 個字母,實不相瞞還是唱著打的字母。
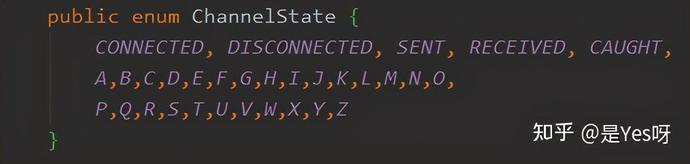
擴充了分支的數量后又進行了一波測試,這次 swtich 爭氣了,終于比 if 強了。

題外話: 我看網上也有對比 if 和 switch 的,它們對比出來的結果是 switch 優于 if,首先 jmh 就沒寫對,定義一個常量來測試 if 和 switch,并且測試方法的 result 寫了沒有消費,這代碼也不知道會被 JIT 優化成啥樣了,寫了幾十行,可能直接優化成 return 某個值了。
對比了這么多我們來小結一下。
首先對于熱點分支將其從 switch 提取出來用 if 獨立判斷,充分利用 CPU 分支預測帶來的便利確實優于純 swtich,從我們的代碼測試結果來看,大致吞吐量高了兩倍。
而在熱點分支的情形下改成純 if 判斷而不是 if + swtich的情形下,吞吐量提高的更多。是純 switch 的 3.3 倍,是 if + switch 的 1.6 倍。
在隨機分支的情形下,三者差別不是很大,但是還是純 if 的情況最優秀。
但是從字節碼角度來看其實 switch 的機制效率應該更高的,不論是 O(1) 還是 O(logn),但是從測試結果的角度來說不是的。
在選擇條件少的情況下 if 是優于 switch 的,這個我不太清楚為什么,可能是在值較少的情況下查表的消耗相比帶來的收益更大一些?有知道的小伙伴可以在文末留言。
在選擇條件很多的情況下 switch 是優于 if 的,再多的選擇值我就沒測了,大伙有興趣可以自己測測,不過趨勢就是這樣的。
接下來咱們再來看看這個分支預測到底是怎么弄的,為什么會有分支預測這玩意,不過在談到分支預測之前需要先介紹下指令流水線(Instruction pipelining),也就是現代微處理器的 pipeline。
CPU 本質就是取指執行,而取指執行我們來看下五大步驟,分別是獲取指令(IF)、指令解碼(ID)、執行指令(EX)、內存訪問(MEM)、寫回結果(WB),再來看下維基百科上的一個圖。
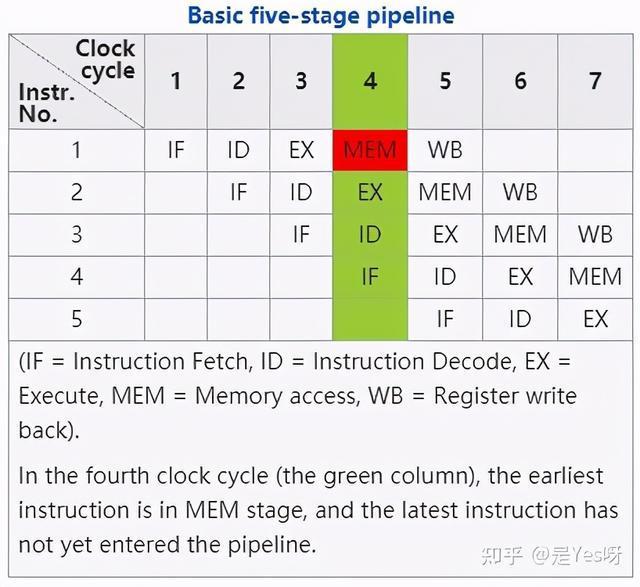
當然步驟實際可能更多,反正就是這個意思需要經歷這么多步,所以說一次執行可以分成很多步驟,那么這么多步驟就可以并行,來提升處理的效率。
所以說指令流水線就是試圖用一些指令使處理器的每一部分保持忙碌,方法是將傳入的指令分成一系列連續的步驟,由不同的處理器單元執行,不同的指令部分并行處理。
就像我們工廠的流水線一樣,我這個奧特曼的腳拼上去了馬上拼下一個奧特曼的腳,我可不會等上一個奧特曼的都組裝完了再組裝下一個奧特曼。

當然也沒有這么死板,不一定就是順序執行,有些指令在等待而后面的指令其實不依賴前面的結果,所以可以提前執行,這種叫亂序執行。
我們再說回我們的分支預測。
這代碼就像我們的人生一樣總會面臨著選擇,只有做了選擇之后才知道后面的路怎么走呀,但是事實上發現這代碼經常走的是同一個選擇,于是就想出了一個分支預測器,讓它來預測走勢,提前執行一路的指令。

那預測錯了怎么辦?這和咱們人生不一樣,它可以把之前執行的結果全拋了然后再來一遍,但是也有影響,也就是流水線越深,錯的越多浪費的也就越多,錯誤的預測延遲是10至20個時鐘周期之間,所以還是有副作用的。
簡單的說就是通過分支預測器來預測將來要跳轉執行的那些指令,然后預執行,這樣到真正需要它的時候可以直接拿到結果了,提升了效率。
分支預測又分了很多種預測方式,有靜態預測、動態預測、隨機預測等等,從維基百科上看有16種。

我簡單說下我提到的三種,靜態預測就是愣頭青,就和蒙英語選擇題一樣,我管你什么題我都選A,也就是說它會預測一個走勢,一往無前,簡單粗暴。
動態預測則會根據歷史記錄來決定預測的方向,比如前面幾次選擇都是 true ,那我就走 true 要執行的這些指令,如果變了最近幾次都是 false ,那我就變成 false 要執行的這些指令,其實也是利用了局部性原理。
隨機預測看名字就知道了,這是蒙英語選擇題的另一種方式,瞎猜,隨機選一個方向直接執行。
還有很多就不一一列舉了,各位有興趣自行去研究,順便提一下在 2018 年谷歌的零項目和其他研究人員公布了一個名為 Spectre 的災難性安全漏洞,其可利用 CPU 的分支預測執行泄漏敏感信息,這里就不展開了,文末會附上鏈接。
之后又有個名為 BranchScope 的攻擊,也是利用預測執行,所以說每當一個新的玩意出來總是會帶來利弊。
至此我們已經知曉了什么叫指令流水線和分支預測了,也理解了 Dubbo 為什么要這么優化了,但是文章還沒有結束,我還想提一提這個 stackoverflow 非常有名的問題,看看這數量。

這個問題在那篇博客開頭就被提出來了,很明顯這也是和分支預測有關系,既然看到了索性就再分析一波,大伙可以在腦海里先回答一下這個問題,畢竟咱們都知道答案了,看看思路清晰不。
就是下面這段代碼,數組排序了之后循環的更快。
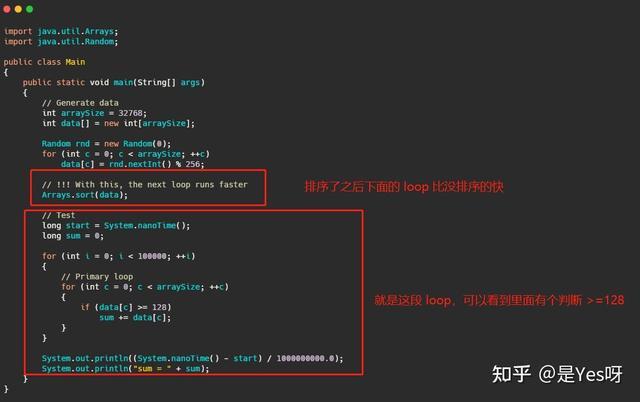
然后各路大神就蹦出來了,我們來看一下首贊的大佬怎么說的。
一開口就是,直擊要害。
You are a victim of branch prediction fail.
緊接著就上圖了,一看就是老司機。

他說讓我們回到 19世紀,一個無法遠距離交流且無線電還未普及的時候,如果是你這個鐵路交叉口的扳道工,當火車快來的時候,你如何得知該扳哪一邊?
火車停車再重啟的消耗是很大的,每次到分叉口都停車,然后你問他,哥們去哪啊,然后扳了道,再重啟就很耗時,怎么辦?猜!

猜對了火車就不用停,繼續開。猜錯了就停車然后倒車然后換道再開。
所以就看猜的準不準了!搏一搏單車變摩托。
然后大佬又指出了關鍵代碼對應的匯編代碼,也就是跳轉指令了,這對應的就是火車的岔口,該選條路了。

后面我就不分析了,大伙兒應該都知道了,排完序的數組執行到值大于 128 的之后肯定全部大于128了,所以每次分支預測的結果都是對了!所以執行的效率很高。
而沒排序的數組是亂序的,所以很多時候都會預測錯誤,而預測錯誤就得指令流水線排空啊,然后再來一遍,這速度當然就慢了。
所以大佬說這個題主你是分支預測錯誤的受害者。
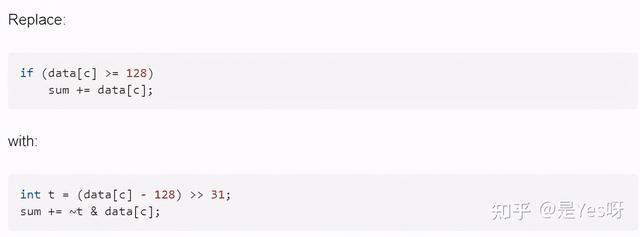
最終大佬給出的修改方案是咱不用 if 了,惹不起咱還躲不起嘛?直接利用位運算來實現這個功能,具體我就不分析了,給大家看下大佬的建議修改方案。
而 swtich 從字節碼上看是優于 if 的,但是從測試結果來看在分支很多的情況下能顯示出優勢,一般情況下還是打不過 if 。
然后也知曉了什么叫指令流水線,這其實就是結合實際了,流水線才夠快呀,然后分支預測預執行也是一個提高效率的方法,當然得猜的對,不然分支預測錯誤的副作用還是無法忽略的,所以對分支預測器的要求也是很高的。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





