溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
好程序員大數據學習路線分享彈性分布式數據集RDD,RDD定義,RDD(Resilient Distributed Dataset)叫做分布式數據集,是Spark中最基本的數據抽象,它代表一個不可變(數據和元數據)、可分區、里面的元素可并行計算的集合。
RDD的特點:自動容錯,位置感知性調度和可伸縮性
RDD的屬性
1.一組分片
即數據集的基本組成單位。對于RDD來說,每個分片都會被一個計算任務處理,并決定并行計算的粒度。用戶可以在創建RDD時指定RDD的分片個數,如果沒有指定,那么就會采用默認值。默認值就是程序所分配到的CPU Core的數目。
2.一個計算每個分區的函數。
Spark中RDD的計算是以分片為單位的,每個RDD都會實現compute函數以達到這個目的。compute函數會對迭代器進行復合,不需要保存每次計算的結果。
3.RDD之間的依賴關系。
RDD的每次轉換都會生成一個新的RDD,所以RDD之間就會形成類似于流水線一樣的前后依賴關系。
容錯處理: 在部分分區數據丟失時,Spark可以通過這個依賴關系重新計算丟失的分區數據,而不是對RDD的所有分區進行重新計算。
4.一個Partitioner,分區器
即RDD的分片函數。當前Spark中實現了兩種類型的分片函數,一個是基于哈希的HashPartitioner,另外一個是基于范圍的RangePartitioner。只有對于key-value的RDD,才會有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函數不但決定了RDD本身的分片數量,也決定了parent RDD Shuffle輸出時的分片數量。
5.一個列表
存儲存取每個Partition的優先位置(preferred location)。-> 就近原則
對于一個HDFS文件來說,這個列表保存的就是每個Partition所在的塊的位置。按照“移動數據不如移動計算”的理念,Spark在進行任務調度的時候,會盡可能地將計算任務分配到其所要處理數據塊的存儲位置。
RDD類型
1.Transformation -> 記錄計算過程(記錄參數,計算方法)
轉換 | 含義 |
map(func) | 返回一個新的RDD,該RDD由每一個輸入元素經過func函數轉換后組成 |
filter(func) | 返回一個新的RDD,該RDD由經過func函數計算后返回值為true的輸入元素組成 |
flatMap(func) | 類似于map,但是每一個輸入元素可以被映射為0或多個輸出元素(所以func應該返回一個序列,而不是單一元素) |
mapPartitions(func) | 類似于map,但獨立地在RDD的每一個分片上運行,因此在類型為T的RDD上運行時,func的函數類型必須是Iterator[T] => Iterator[U] |
mapPartitionsWithIndex(func) | 類似于mapPartitions,但func帶有一個整數參數表示分片的索引值,因此在類型為T的RDD上運行時,func的函數類型必須是 (Int, Iterator[T]) => Iterator[U] |
sample(withReplacement, fraction, seed) | 根據fraction指定的比例對數據進行采樣,可以選擇是否使用隨機數進行替換,seed用于指定隨機數生成器種子 |
union(otherDataset) | 對源RDD和參數RDD求并集后返回一個新的RDD |
intersection(otherDataset) diff -> 差集 | 對源RDD和參數RDD求交集后返回一個新的RDD |
distinct([numTasks])) ?????????[改變分區數] | 對源RDD進行去重后返回一個新的RDD |
groupByKey([numTasks]) | 在一個(K,V)的RDD上調用,返回一個(K, Iterator[V])的RDD |
reduceByKey(func, [numTasks]) | 在一個(K,V)的RDD上調用,返回一個(K,V)的RDD,使用指定的reduce函數,將相同key的值聚合到一起,與groupByKey類似,reduce任務的個數可以通過第二個可選的參數來設置 |
aggregateByKey(zeroValue)(seqOp, combOp, [numTasks]) | |
sortByKey([ascending], [numTasks]) | 在一個(K,V)的RDD上調用,K必須實現Ordered接口,返回一個按照key進行排序的(K,V)的RDD |
sortBy(func,[ascending], [numTasks]) | 與sortByKey類似,但是更靈活 |
join(otherDataset, [numTasks]) | 在類型為(K,V)和(K,W)的RDD上調用,返回一個相同key對應的所有元素對在一起的(K,(V,W))的RDD |
cogroup(otherDataset, [numTasks]) | 在類型為(K,V)和(K,W)的RDD上調用,返回一個(K,(Iterable<V>,Iterable<W>))類型的RDD |
cartesian(otherDataset) | 笛卡爾積 |
pipe(command, [envVars]) | |
coalesce(numPartitions) | |
repartition(numPartitions) | ?重新分區 |
repartitionAndSortWithinPartitions(partitioner) |
2.Action ?-> 觸發生成job(一個job對應一個action算子)
動作 | 含義 |
reduce(func) | 通過func函數聚集RDD中的所有元素,這個功能必須是可交換且可并聯的 |
collect() | 在驅動程序中,以數組的形式返回數據集的所有元素 |
count() | 返回RDD的元素個數 |
first() | 返回RDD的第一個元素(類似于take(1)) |
take(n) | 取數據集的前n個元素組成的數組 |
takeSample(withReplacement,num, [seed]) | 返回一個數組,該數組由從數據集中隨機采樣的num個元素組成,可以選擇是否用隨機數替換不足的部分,seed用于指定隨機數生成器種子 |
takeOrdered(n,?[ordering]) | takeOrdered和top類似,只不過以和top相反的順序返回元素 |
saveAsTextFile(path) | 將數據集的元素以textfile的形式保存到HDFS文件系統或者其他支持的文件系統,對于每個元素,Spark將會調用toString方法,將它裝換為文件中的文本 |
saveAsSequenceFile(path)? | 將數據集中的元素以Hadoop sequencefile的格式保存到指定的目錄下,可以使HDFS或者其他Hadoop支持的文件系統。 |
saveAsObjectFile(path)? | |
countByKey() | 針對(K,V)類型的RDD,返回一個(K,Int)的map,表示每一個key對應的元素個數。 |
foreach(func) | 在數據集的每一個元素上,運行函數func進行更新。 |
創建RDD
Linux進入sparkShell:
/usr/local/spark.../bin/spark-shell \
--master spark://hadoop01:7077 \
--executor-memory 512m \
--total-executor-cores 2
或在Maven下:
object lx03 { ??def main(args: Array[String]): Unit = { ????val conf : SparkConf = new SparkConf() ??????.setAppName("SparkAPI") ??????.setMaster("local[*]") ????val sc: SparkContext = new SparkContext(conf) ????//通過并行化生成rdd ????val rdd1: RDD[Int] = sc.parallelize(List(24,56,3,2,1)) ????//對add1的每個元素乘以2然后排序 ????val rdd2: RDD[Int] = rdd1.map(_ * 2).sortBy(x => x,true) ????println(rdd2.collect().toBuffer) ????//過濾出大于等于10的元素 // ???val rdd3: RDD[Int] = rdd2.filter(_ >= 10) // ???println(rdd3.collect().toBuffer) ??} |
練習2
val rdd1 = sc.parallelize(Array("a b c", "d e f", "h i j")) //將rdd1里面的每一個元素先切分在壓平 val rdd2 = rdd1.flatMap(_.split(' ')) rdd2.collect //復雜的: val rdd1 = sc.parallelize(List(List("a b c", "a b b"), List("e f g", "a f g"), List("h i j", "a a b"))) //將rdd1里面的每一個元素先切分在壓平 val rdd2 = rdd1.flatMap(_.flatMap(_.split(" "))) |
練習3
val rdd1 = sc.parallelize(List(5, 6, 4, 3)) val rdd2 = sc.parallelize(List(1, 2, 3, 4)) //求并集 val rdd3 = rdd1.union(rdd2) //求交集 val rdd4 = rdd1.intersection(rdd2) //去重 rdd3.distinct.collect rdd4.collect |
練習4
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2))) val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2))) //求join val rdd3 = rdd1.join(rdd2) ?-> 相同的key組成新的key,value //結果: Array[(String,(Int,Int))] = Array((tom,(1,1)),(jerry,(3,2))) rdd3.collect //求左連接和右連接 val rdd3 = rdd1.leftOuterJoin(rdd2) rdd3.collect val rdd3 = rdd1.rightOuterJoin(rdd2) rdd3.collect //求并集 val rdd4 = rdd1 union rdd2 //按key進行分組 rdd4.groupByKey rdd4.collect //分別用groupByKey和reduceByKey實現單詞計數 val rdd3 = rdd1 union rdd2 rdd3.groupByKey().mapValues(_.sum).collect rdd3.reduceByKey(_+_).collect |
groupByKey和reduceByKey的區別
reduceByKey算子比較特殊,它首先會進行局部聚合,再全局聚合,我們只需要傳一個局部聚合的函數就可以了
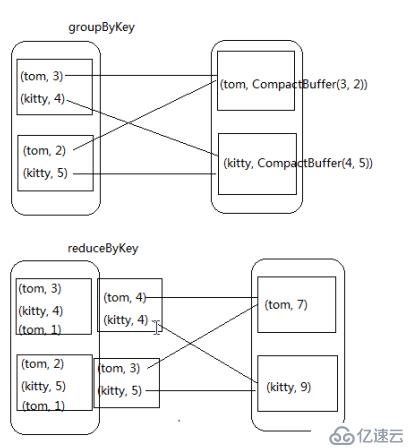
練習5
val rdd1 = sc.parallelize(List(("tom", 1), ("tom", 2), ("jerry", 3), ("kitty", 2))) val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 1), ("shuke", 2))) //cogroup val rdd3 = rdd1.cogroup(rdd2) //注意cogroup與groupByKey的區別 rdd3.collect val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5)) //reduce聚合 val rdd2 = rdd1.reduce(_ + _) //按value的降序排序 val rdd5 = rdd4.map(t => (t._2, t._1)).sortByKey(false).map(t => (t._2, t._1)) rdd5.collect //笛卡爾積 val rdd3 = rdd1.cartesian(rdd2) |
計算元素個數
scala> val rdd1 = sc.parallelize(List(2,3,1,5,7,3,4)) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at parallelize at <console>:27 scala> rdd1.count res0: Long = 7 ? |
top先升序排序在取值
scala> rdd1.top(3) res1: Array[Int] = Array(7, 5, 4) ?????????????????????????????????????????????? scala> rdd1.top(0) res2: Array[Int] = Array() scala> rdd1.top(100) res3: Array[Int] = Array(7, 5, 4, 3, 3, 2, 1) |
take原集合前N個,有幾個取幾個
scala> rdd1.take(3) res4: Array[Int] = Array(2, 3, 1) scala> rdd1.take(100) res5: Array[Int] = Array(2, 3, 1, 5, 7, 3, 4) scala> rdd1.first res6: Int = 2 |
takeordered倒序排序再取值
scala> rdd1.takeOrdered(3) res7: Array[Int] = Array(1, 2, 3) scala> rdd1.takeOrdered(30) res8: Array[Int] = Array(1, 2, 3, 3, 4, 5, 7) |
?????????????????????????????
生成RDD的兩種方式
1.并行化方式生成 (默認分區兩個)
手動指定分區
scala> val rdd1 = sc.parallelize(List(1,2,3,5)) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[5] at parallelize at <console>:27 scala> rdd1.partitions.length ?//獲取分區數 res9: Int = 2 scala> val rdd1 = sc.parallelize(List(1,2,3,5),3) rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[6] at parallelize at <console>:27 scala> rdd1.partitions.length res10: Int = 3 |
2.使用textFile讀取文件存儲系統里的數據 ?
scala> val rdd2 = sc.textFile("hdfs://hadoop01:9000/wordcount/input/a.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_) rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[11] at reduceByKey at <console>:27 scala> rdd2.collect ?//調用算子得到RDD顯示結果 res11: Array[(String, Int)] = Array((hello,6), (beijing,1), (java,1), (gp1808,1), (world,1), (good,1), (qianfeng,1)) scala> val rdd2 = ?sc.textFile("hdfs://hadoop01:9000/wordcount/input/a.txt",4).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_) rdd2: org.apache.spark.rdd.RDD[(String, Int)] = ShuffledRDD[26] at reduceByKey at <console>:27 scala> rdd2.partitions.length ???//也可以自己指定分區數 res15: Int = 4 |
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





