溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關MapReduce計算框架指的是什么,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
先生說:"MapReduce是hadoop的一個計算框架,說直白點就是hdfs負責存儲,那么像其他統計、計算之類的事情就會交給MapReduce來做,分為map過程和reduce過程。
Map 過程是拆解,比如說有輛紅色的小汽車,有一群工人,把它拆成零件了,這就是Map"

Reduce 過程是組合,我們有很多汽車零件,還有很多其他各種裝置零件,把他們一陣拼裝,變成變形金剛,這就是Reduce。

小白聽了:"這么聽起來,感覺挺形象的,那么具體的map過程和reduce過程是如何。"
"且聽我慢慢給你講解",喵先生咽了咽口水。
先生說:"首先我們來看下面的數據————學生的信息記錄表"

1、我們可以過濾出性別為1的數據;
2、可以將性別字段中1轉換成男且0轉換成女;
3、也可以將字段地址展開;
以上的過程就是map:以一條記錄為單位做映射(過濾/轉換/展開)
小白說:"我感覺map的原理跟mysql的語法好像啊,select * from student where sex=1,都是對數據進行1條1條的處理."
先生:"嗯,孺子可教,我們來繼續看看reduce過程:我們想統計出學習各專業共有多少名同學時,需要將python、java、c進行分組,以這樣的一組為單位進行統計計算。"

以上的過程就是reduce:以組為單位進行計算
小白說:"這不就是mysql 里面 group by的原理嘛,以組為單位進行統計"
先生補充到:"思想跟mysql的group by思想類似的"

最后喵先生繼續總結到:" 輸入數據按照以一條數據為單位進行映射(map方法),然后輸出kv鍵值對,以組為單位作為reduce的輸入進行計算,最終輸出結果。"
好學的小白繼續問到:"嗯,我了解了mapreduce的大致過程,它如何從hdfs上取數據的呢,中間又是如何交互的呢"
先生:“不錯哦小白,看來你還挺上進的,那咱們來看看mapreduce交互圖,mapreduce分為4步”
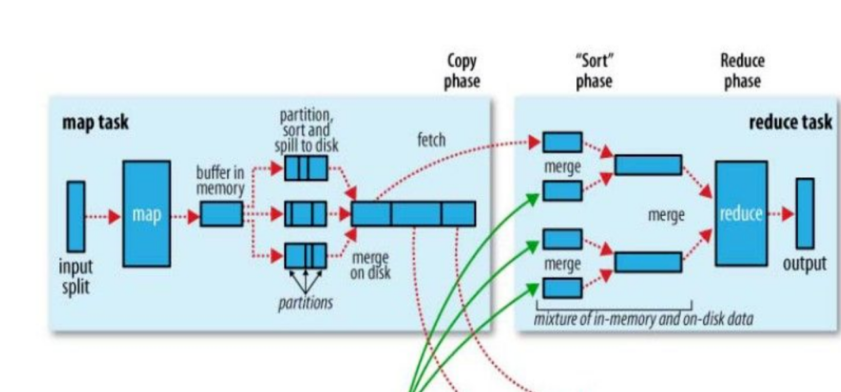
分為4步:
"為啥map不直接從hdfs上獲取數據,中間非得用split獲取呢?"小白撓撓頭望著喵先生,
先生點點頭對小白說:"這個問題非常贊,split默認大小等于hdfs上的一個block塊大約是64M,但可以通過調整split的大小來應對不同的計算類型,
當我們運行CPU-bound(計算密集型),可以將split設置小一點,多個split對應1個block塊,這樣可以提高計算速度

當我們運行IO-bound(IO密集型),可以將split設置大一點,1個split對應N個block塊,這樣可以提高IO讀寫效率,
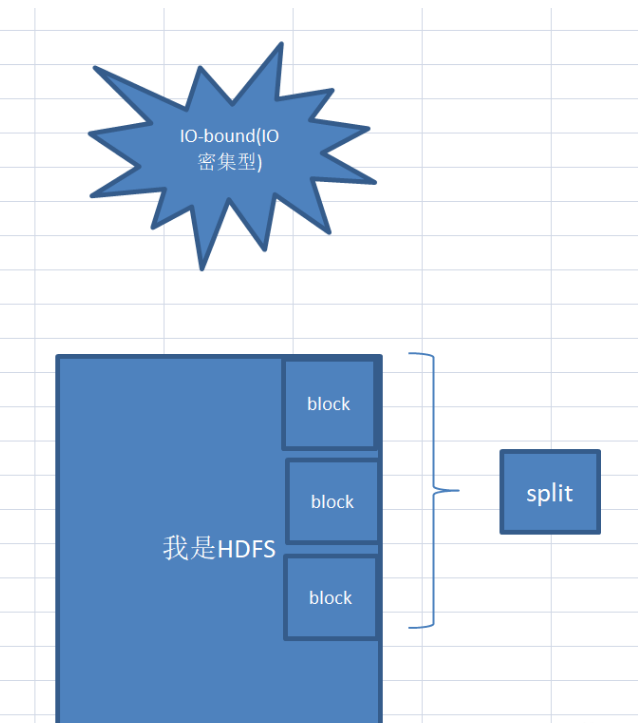
CPU-bound(計算密集型):
假設有一道數學題,題干只有一行字,
讀題花費1秒,解題需要1個月才能解出來,
這樣就是CPU-bound。(CPU利用率幾乎100%)。
IO bound(IO密集型):
假設有一道數學題,題干有史記那么厚,
讀完花費2個月,問題只是讓你回答1+1=?,
這樣就是I/O-bound。(CPU IDLE狀態)。
小白總結到:“split原來可以控制map的并行度,決定了到底啟用多少個map任務,一個split對一個map方法,輸出k,v,p鍵值對”
“這里為什么要將輸出的kv鍵值對放到內存里呢,雖然內存速度是硬盤的10萬倍,但最終數據不也會寫到磁盤上嗎,這不等于脫了褲子放屁嗎?”小白著急的問題,
“嗯,詞粗理不粗,這里放map輸出的kv鍵值對放100M的內存中,還做了一件重要的事情————那就是對k,v,p數據進行排序,將分區p下的數據放到一起,并且同一個分區下的k進行了排序,方便后面的reduce是做 歸并排序。”先生解釋道。
“你慢點呢,我都聽得懵了,舉個例子呢”
“那就看看下面的例子吧,統計java\python\mysql出現的次數”先生迅速的畫了一張圖
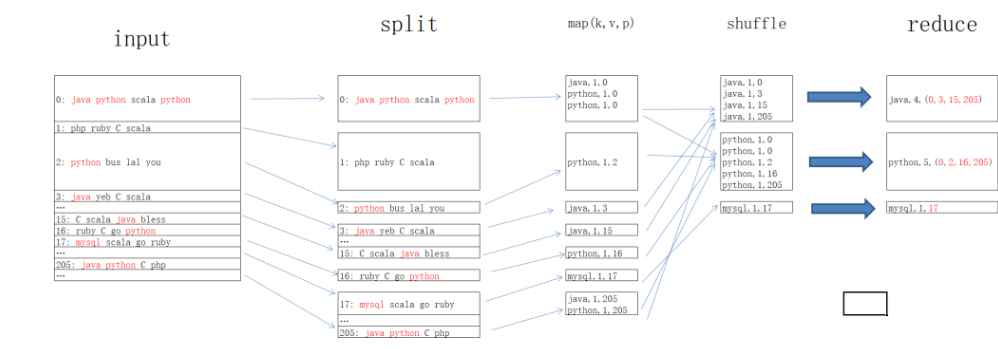
imput階段:hdfs的block塊上存有java、python、mysql的存儲文件位置
split階段:使用split對hdfs上的文件進行切塊,其中文件分區0、2、3、15、16、17、205上存有java\python\mysql的信息,
map階段:將每個分區上的含有java\python\mysql信息的數據進行kvp鍵值對輸出,例:java,1,0 代表0號分區下存有java信息1次
shuffle階段:在內存中對同一組數據進行排序,例:java出現在0、3、15、205分區上,
reduce階段:最終reduce任務根據shffle階段輸出的排序,到指定的的文件分區上獲取到對應的文件。
“真神奇,看來內存中的排序還真重要,有效減少了文件讀取的次數,一次讀取多次取數,對應的處理速度也加快了”小白恍然大悟到。
"還有個問題,我看上面的例子中key的數量是3個(java\python\mysql)對應的reduce的任務數也是3個,是不是key的數量就等于reduce的數量?"小白問道,
“觀察的挺仔細的呀,reduce的數量是由程序員代碼里面控制的,但key的數量也不完全等于reduce的數量,你想想萬一key有10萬個呢?那么reduce數量需要10萬個嗎?肯定沒那么多資源,所以一般是根據具體服務器資源中reduce執行器的數量決定的。”先生補充到。
"另外還需要注意的是,如果key的數據量分布不均勻的話,可能會出現數據傾斜的問題,假如2個key————1個男,1個女,男數據量有10T,女的數據就只有1G,這樣的話進行,系統遵循reduce處理同一個key時會將同一個key被分到同一個reduce執行器下,那么這樣的話一個reduce執行器就會處理10T的數據,另一個reduce執行器處理1G數據,這就照成了數據傾斜。"先生繼續補充到。
上述就是小編為大家分享的MapReduce計算框架指的是什么了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





