溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
取出各組的前N行數據是較常見的運算,比如:每個月每種產品銷量最高的五天是哪五天,每位員工漲薪最多的一次是哪次,高爾夫會員成績最差的三次是哪三次,等等。在SQL中,這類運算要用窗口函數以及keep/top/rownumber等高級技巧來間接處理,代碼難度較大。而且許多數據庫(如MySQL)還沒有這些高級功能,就只能用更復雜的JOIN語句和嵌套的子查詢來實現了。如果還涉及多層分組,多級關聯,計算過程會更加復雜。
而在SPL中,由于top函數可以按行號、最大值、最小值等方式取分組中的前N行,因此解決此類問題更加容易、清晰。下面就用一個例子來說明。
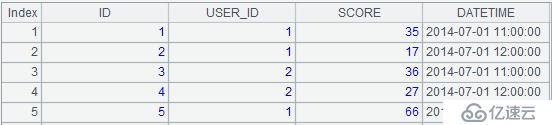
數據庫表golf存儲著多位會員的高爾夫得分情況,部分數據如下:
| ID | USER_ID | SCORE | DATETIME |
| 1 | 1 | 35 | 2014-07-01 11:00:00 |
| 2 | 1 | 17 | 2014-07-01 12:00:00 |
| 3 | 2 | 36 | 2014-07-01 11:00:00 |
| 4 | 2 | 27 | 2014-07-01 12:00:00 |
| 5 | 1 | 66 | 2014-07-02 11:00:00 |
| 6 | 1 | 77 | 2014-07-02 12:00:00 |
| 7 | 2 | 93 | 2014-07-02 12:00:00 |
| 8 | 1 | 27 | 2014-07-03 12:00:00 |
| 9 | 1 | 48 | 2014-07-03 18:00:00 |
| 10 | 1 | 36 | 2014-07-04 18:00:00 |
| 11 | 3 | 77 | 2014-07-01 12:00:00 |
| 12 | 3 | 68 | 2014-07-02 13:00:00 |
| 13 | 4 | 25 | 2014-07-02 13:00:00 |
請取出每位會員成績最好的三次得分情況。
SPL代碼:
| A | |
| 1 | =db.query("select * from golf") |
| 2 | =A1.group(USER_ID) |
| 3 | =A2.(~.top(-3;SCORE)) |
| 4 | =A3.union() |
| 5 | >file("golf.csv").export@ct(A4) |
A1:從數據庫取數。點擊該單元格,可以看到取數結果:
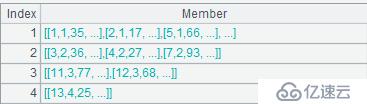
A2:=A1.group(USER_ID)。將A1的結果按照USER_ID,也就是會員分組,結果如下:
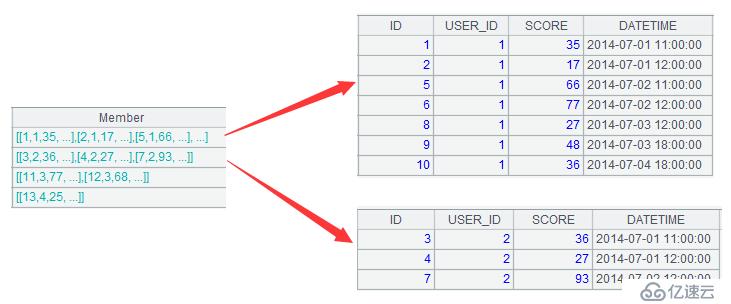
每行代表一組,其中是一個會員的所有得分記錄,雙擊淺藍色格子,可以看到組內成員,如下:
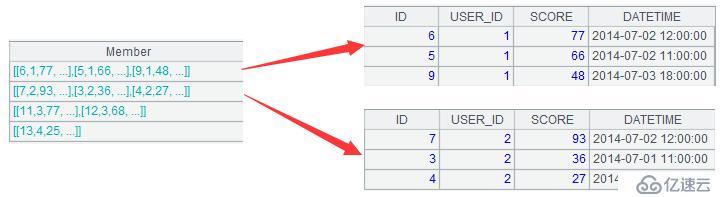
A3:= A2.(~.top(-3;SCORE))。計算出每組數據SCORE字段前三的記錄。這里的“~”表示每組數據,~.top()表示依次對每組數據應用函數top。函數top可以取得數據集的前N條記錄,比如top(3;SCORE)表示按SCORE升序排列,取前3條(即最小值);top(-3;SCORE)表示按降序排列,取前3條(即最大值,也就是這里的最好成績)。這一步的計算結果如下:
A4:=A3.union()。將各組數據合并,結果如下:
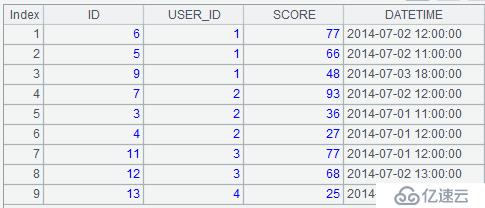
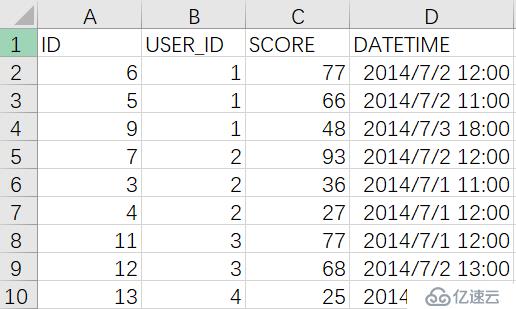
A5:>file("golf.csv").export@ct(A4)
將計算結果導出到" golf.csv "文件,以便通過excel等工具查看:
除了導出數據, SPL還可以直接被報表工具或java程序調用,調用方法和普通數據庫相似,使用它提供的JDBC接口即可向java主程序返回ResultSet形式的計算結果,具體方法可參考相關文檔。【Java如何調用SPL腳本】
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





