溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
Python中怎么利用正則抓取數據,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
1、正則表達式基礎
(1)一般字符

(2)預定義字符集
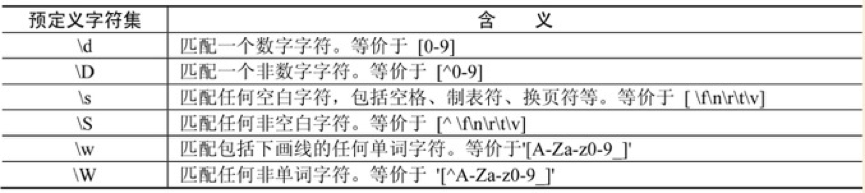
(3)數量詞

(4)邊界匹配

備注:最常用的一種匹配方式(.*?)代表匹配任意字符
2、re模塊使用方法
re模塊使得Python擁有全部的正則表達式功能。
常用函數1:search()函數匹配并提取第一個符合規律的內容,返回一個正則表達對象
常用函數2:findall()函數匹配所有符合規律的內容,并以列表的形式返回結果
備注:一般在爬取數據時候還是以findall使用居多
re模塊修飾符
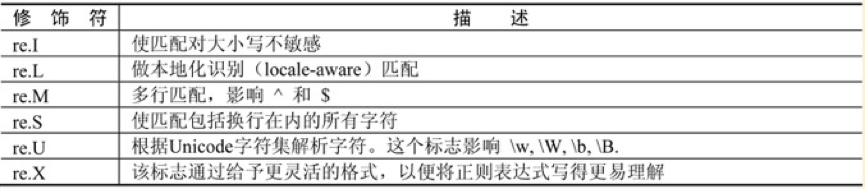
3、案例實踐
案例名稱:爬取《斗破蒼穹》全文小說
網絡鏈接:http://www.doupoxs.com/doupocangqiong/
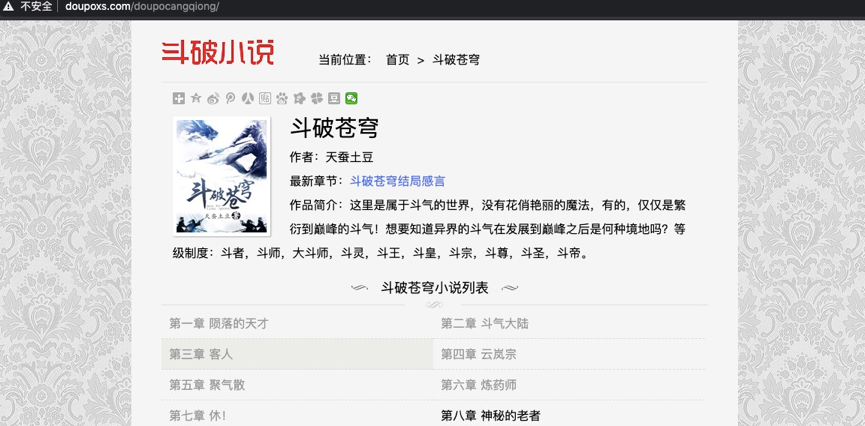
爬取思路:
(1)打開網頁,了解網頁URL信息,通過打開第一章和第二章發現鏈接如下
http://www.doupoxs.com/doupocangqiong/1.html
http://www.doupoxs.com/doupocangqiong/2.html
http://www.doupoxs.com/doupocangqiong/3.html
明顯鏈接通過數字遞加來對每一章節進行分頁。
(2)爬取全文信息,查找對應的位置如下
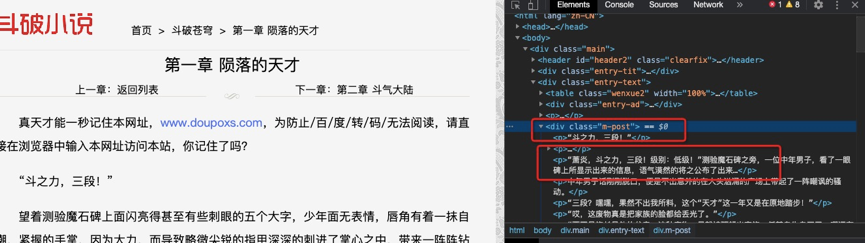
(3)數據存儲到TXT文本中
4、詳細代碼如下:
import requestsimport reimport timeheaders={"User-Agent":請求頭}f=open('doupo.txt','a+')def get_info(url):res=requests.get(url,headers=headers)if res.status_code==200:contents = re.findall('<p>(.*?)<p>',res.content.decode('utf-8'),re.S)for content in contents:f.write(content+'\n')print(content)else:passif __name__=='__main__':urls=['http://www.doupoxs.com/doupocangqiong/{}.html'.format(i) for i in range(2,10)]for url in urls:get_info(url)time.sleep(1)f.close()
運行結果如下:

關于Python中怎么利用正則抓取數據問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





