溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Python爬蟲基礎庫有哪些”,在日常操作中,相信很多人在Python爬蟲基礎庫有哪些問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Python爬蟲基礎庫有哪些”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
爬蟲有三大基礎庫Requests、BeautifulSoup和Lxml,這三大庫對于初學者使用頻率最高,現在大家一起來看看這基礎三大庫的使用。
1、Requests庫
Requests庫的作用就是請求網站獲取網頁數據。
Code:res=requests.get(url)
返回:
返回200說明請求成功
返回404、400說明請求失敗
Code:res=request.get(url,headers=headers)
添加請求頭信息偽裝為瀏覽器,可以更好的請求數據信息
Code:res.text
詳細的網頁信息文本
2、BeautifulSoup庫
BeautifulSoup庫用來將Requests提取的網頁進行解析,得到結構化的數據
Soup=BeautifulSoup(res.text,’html.parser’)
詳細數據提取:
infos=soup.select(‘路徑’)
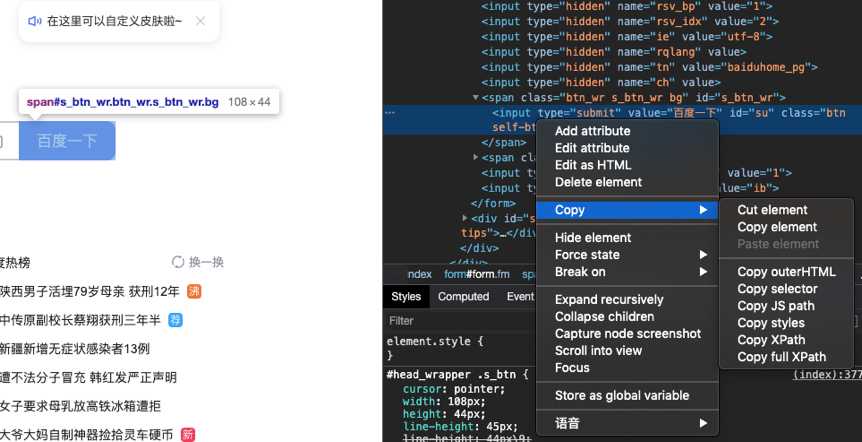
路徑提取方法:在固定數據位置右鍵-copy-copy selector
3、Lxml庫
Lxml為XML解析庫,可以修正HTML代碼,形成結構化的HTML結構

Code:
From lxml import etree
Html=etree.HTML(text)
Infos=Html.xpath(‘路徑’)
路徑提取方法:在固定數據位置右鍵-Copy-Copy Xpath
實踐案例:
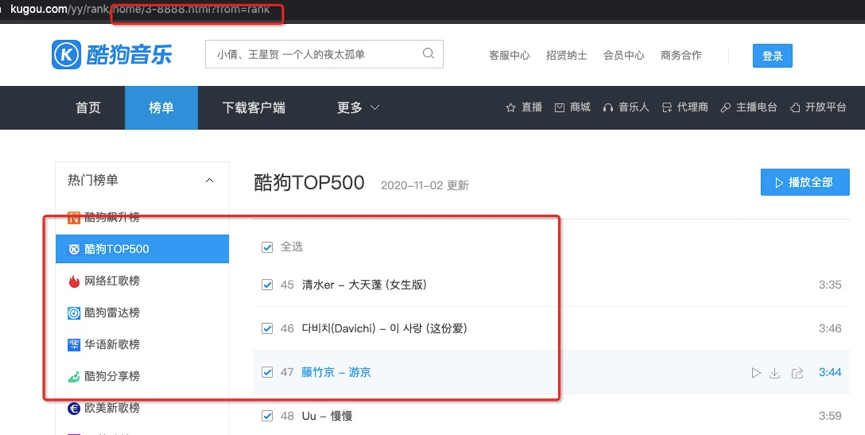
1、爬取酷狗榜單TOP500音樂信息

2、網頁無翻頁,如何尋找URL,發現第一頁URL為:
https://www.kugou.com/yy/rank/home/1-8888.html?from=rank
嘗試把1換成2,可以得到新的網頁,依次類推,得到迭代的網頁URL
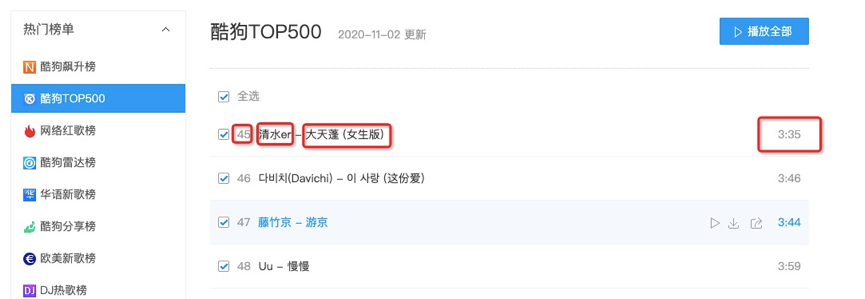
3、爬取信息為歌曲名字、歌手等
4、詳細代碼如下:
import requestsfrom bs4 import BeautifulSoupimport timeheaders={"User-Agent": "xxxx"}def get_info(url):print(url)#通過請求頭和鏈接,得到網頁頁面整體信息web_data=requests.get(url,headers=headers)#print(web_data.text)#對返回的結果進行解析soup=BeautifulSoup(web_data.text,'lxml')#找到具體的相同的數據的內容位置和內容ranks = soup.select('span.pc_temp_num')titles = soup.select('div.pc_temp_songlist > ul > li > a')times = soup.select('span.pc_temp_tips_r > span')#提取具體的文字內容for rank, title, time in zip(ranks, titles, times):data = {'rank': rank.get_text().strip(),'singer': title.get_text().split('-')[0],'song': title.get_text().split('-')[1],'time': time.get_text().strip()}print(data)if __name__=='__main__':urls = ['https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'.format(i) for i in range(1, 2)]for url in urls:get_info(url)time.sleep(1)
到此,關于“Python爬蟲基礎庫有哪些”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





