溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
HA背景
對于HDFS、YARN的每個角色都是一個進程,
比如HDFS:NN/SNN/DN? ?老大是NN
YARN:RM/NM? ?老大是RM
對于上面,都會存在單點故障的問題,假如老大NN或者RM掛了,那么就不能提供對外服務了,會導致整個集群都不能使用。
大數據幾乎所有的組建都是主從架構(master-slave)。比如hdfs的讀寫請求都是先經過NN節點。(但是hbase的讀寫請求不是經過老大的master)。
hdfs:由NN/SNN/DN組成,SNN每小時會做一次checkpoint的操作,如果NN掛了,只能恢復到上次checkpoint的那一刻,不能實時。現在如果把SNN的角色再提升一個等級,讓它和NN一樣,如果NN掛了,SNN能立即切換過來就好了。
HDFS HA 架構 有兩個NN節點,一個是active活躍狀態,一個是standby準備狀態,Active NameNode對外提供服務,比如處理來自客戶端的RPC請求,而Standby NameNode則不對外提供服務,僅同步Active NameNode的狀態,對Active NameNode進行實時備份,以便能夠在它失敗時快速進行切換。
HA介紹
HDFS High Availability (HA)?
假定:
NN1 active? ? ? ?ip1
NN2 standby? ? ip2
假如說在我們代碼或者shell腳本里,寫了:hdfs dfs -ls hdfs://ip1:9000/? ?,那么如果NN1掛了,NN2切換到active狀態了,但是在腳本里還是ip1,這個時候不可能手動去修改。肯定有問題。那么該怎么解決?
用命名空間來解決。命名空間不是進程。比如:命名空間的名稱為:ruozeclusterg7
腳本里可以這樣寫:hdfs dfs -ls hdfs://ruozeclusterg7/
當代碼執行到這一行時,它會去core-site.xml、hdfs-site.xml里面查找。在這兩個配置文件里面,配置了ruozeclusterg7命名空間下掛了NN1和NN2。當它找到NN1,它會嘗試著連接第一個機器NN1,如果發現它不是active狀態,它會嘗試著連接第二個機器NN2,如果發現NN1是active狀態,就直接用了。
?
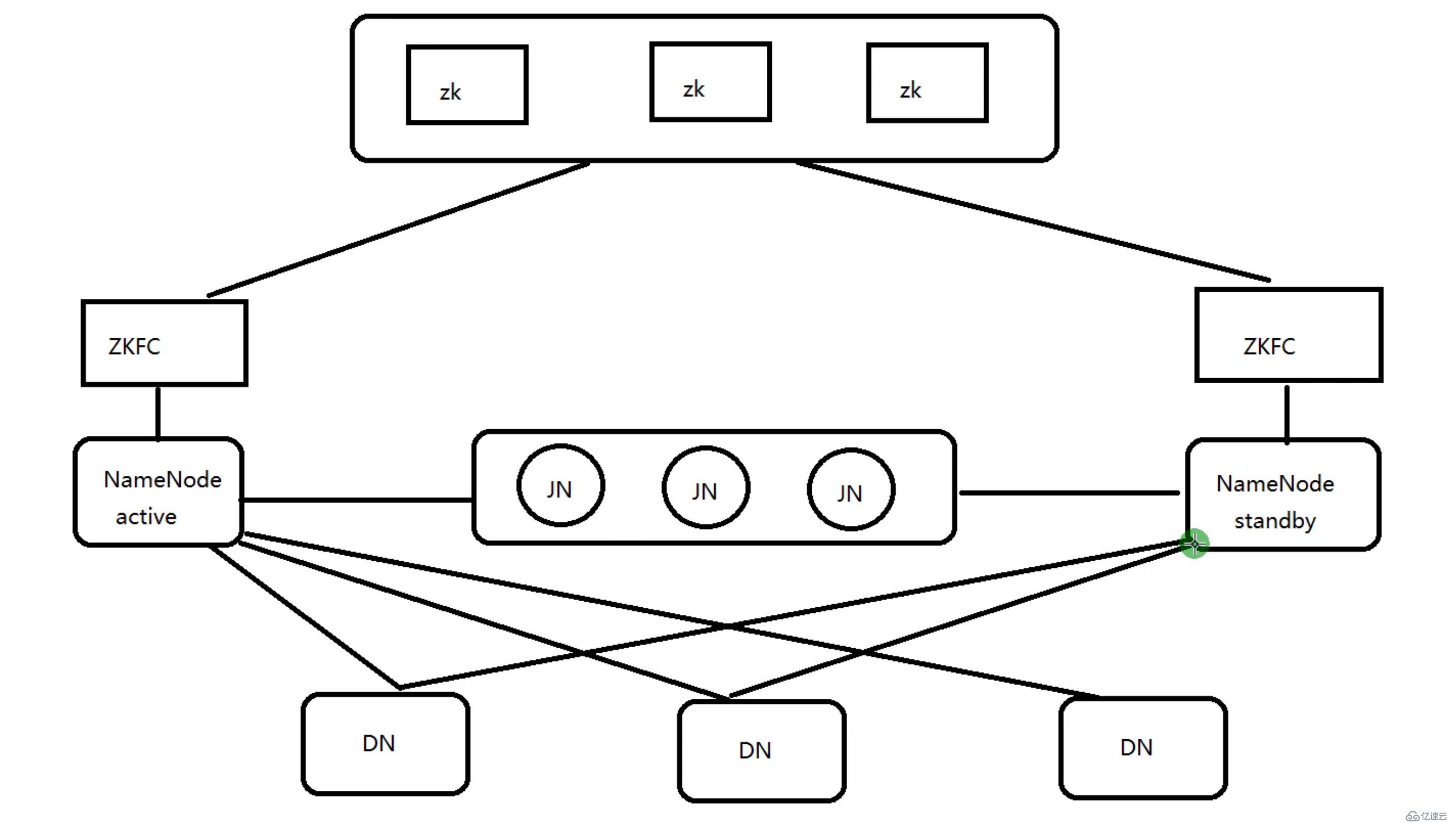
HA 進程:(假定我們現在有三臺機器)
hadoop001:ZK? ? NN? ZKFC? JN? ? DN
hadoop002:ZK? ? NN? ZKFC? JN? ? DN
hadoop003:ZK? ? ? ? ? ? ? ? ? ? ? ?JN? ? DN
NN節點有fsimage、editlog(讀和寫請求的記錄)兩個文件,有專門的進程去管理的,這個進程是JN(journalnode)日志節點,要保證NN1和NN2能實時同步,需要JN這個角色。
如果NN1掛了,需要把NN2從standby狀態切換到active狀態,那它是怎么切換的呢?需要ZKFC。
ZKFC: 是單獨的進程,它監控NN健康狀態,向zk集群定期發送心跳,使得自己可以被選舉;當自己被zk選舉為active的時候,zkfc進程通過RPC協議調用使NN節點的狀態變為active。對外提供實時服務,是無感知的。
所以在上面,需要在三臺機器上都部署一下zookeeper,作為一個集群,ZK集群,是用于做選舉的。選舉誰來做老大(active),誰做standby。集群中ZK的個數是2n+1,這樣能投票保證最后有一個勝出。
生產上zookeeper部署的個數經驗:如果集群中有20臺節點,那么可以在5臺上部署zk。如果總共有七八臺,也部署5臺zk。如果總共有20~100臺節點,可以部署7臺/9臺/11臺 zk。如果大于100臺,可以部署11臺zk。如果有很多,比如上萬臺那看情況可以多部署幾臺。但是,不是說zk節點越多越好。因為做投票選舉動作的時候,投票誰做active,誰做standby是需要時間的,時間間隔太長會影響對外服務,對外服務會很慢,對于即時性 的服務來說,這是不允許的。
他們的集群有很多臺,比如幾百臺幾千臺,zk部署的機器上就它一個進程,不部署其它進程了。在這里是學習或者機器很少,所以一臺機器上部署多個進程。如果幾百臺節點,任務很重,如果部署zk的機器上有其它進程,那么它會消耗很多機器上的資源(無外乎cpu、內存、文件數、進程數),這都會影響zk響應的速度,所以一般都會把它獨立出來。但是如果機器是256G內存,但是zk只用到32G,那其他的就浪費了,那么買機器的時候,可以單獨給zk買32G內存的機器就可以了。
zk是最底層的,如果zk太繁忙,就可能導致standby狀態不能切換到active狀態,這個時候機器可能就會夯住。所以當機器夯住,standby不能切換到active的時候,有可能就是zk出問題了。
關于HA 架構的官方文檔https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/HDFSHighAvailabilityWithQJM.html
Architecture
翻譯:
一個典型的HA集群,NameNode會被配置在2臺或更多 獨立的機器上,在任何時間上,一個NameNode處于活動狀態,而另一個NameNode處于備份狀態,活動狀態的NameNode會響應集群中所有的客戶端,備份狀態的NameNode只是作為一個副本,保證在必要的時候提供一個快速的轉移。
為了讓Standby Node與Active Node保持同步,這兩個Node都與一組稱為JNS的互相獨立的進程保持通信(Journal Nodes)。當Active Node上更新了namespace,它將記錄修改日志發送給JNS的多數派。Standby noes將會從JNS中讀取這些edits,并持續關注它們對日志的變更。Standby Node將日志變更應用在自己的namespace中,當failover發生時,Standby將會在提升自己為Active之前,確保能夠從JNS中讀取所有的edits,即在failover發生之前Standy持有的namespace應該與Active保持完全同步。
為了支持快速failover,Standby node持有集群中blocks的最新位置是非常必要的。為了達到這一目的,DataNodes上需要同時配置這兩個Namenode的地址,同時和它們都建立心跳鏈接,并把block位置發送給它們。
任何時刻,只有一個Active NameNode是非常重要的,否則將會導致集群操作的混亂,那么兩個NameNode將會分別有兩種不同的數據狀態,可能會導致數據丟失,或者狀態異常,這種情況通常稱為“split-brain”(腦裂,三節點通訊阻斷,即集群中不同的Datanodes卻看到了兩個Active NameNodes)。對于JNS而言,任何時候只允許一個NameNode作為writer;在failover期間,原來的Standby Node將會接管Active的所有職能,并負責向JNS寫入日志記錄,這就阻止了其他NameNode基于處于Active狀態的問題。
首先要部署三臺zk,然后要兩臺NN節點,然后三臺DN節點。兩個NN節點之間的編輯日志需要jn來維護,做共享數據存儲。
journalnode(jn): 部署多少合適?取決于HDFS請求量及數據量,比如說BT級的數據量,或者小文件很多,讀寫請求很頻繁,那么journalnode就部署多一點,如果HDFS很悠閑,那就部署少一點,比如7個、9個這樣,可以大致和zk部署的保持一致(見上面)。具體要看實際情況。(也是2n+1,可以看官網上介紹)
ZKFC:zookeeperfailovercontrol
客戶端或者程序代碼在提交的時候,去namespace找,找NN節點,如果第一次找的NN節點就是active,那么就用這個節點,如果發現它是standby,就到另外一臺機器。
比如說客戶端現在執行put、get、ls、cat命令,這些操作命令的記錄,active NN節點會寫到自己的edit log日志里面。這些操作記錄,NN自己會寫一份,同時,它會把這些操作記錄,寫給journalnode的node集群。
而另外的,standby NN節點,會實時的讀journalnode的node集群,讀了之后會把這些記錄應用到自己的本身。這個大數據的專業名詞叫做:重演。 相當于standby NN節點把active NN節點的active狀態的操作記錄在自己身上重演一遍。
journalnode:它是一個集群,就是用于active NN節點和standby NN節點之間同步數據的。它是單獨的進程。
NN和ZKFC在同一臺機器上面。
整個過程描述:當通過client端提交請求的時候,無論讀和寫,我們是通過命名空間RUOZEG6,去找誰是active狀態,找到了就在那臺機器上面,提交請求,然后就是HDFS的讀寫流程,讀和寫的操作記錄,edit log,它自己會寫一份,同時會把讀寫請求的操作記錄,寫一份到journalnode集群日志,進行同步之后,另外一個節點,standby 節點會把它拿過來實時的應用到自己的本身。專業的名稱叫重演。同時每個DataNode會向NameNode節點發送心跳的塊報告(心跳的間隔時間3600s,就是1小時,參數是什么(面試))。當active NN節點掛了,通過zk集群選舉(它存儲了NN節點的狀態),通知ZKFC,把standby NN節點切換到active狀態。ZKFC會定期的發送心跳。
ps:
HA是為了解決單點故障問題。
通過journalnode集群共享狀態,也就是共享hdfs讀和寫的操作記錄。
通過ZKFC集群選舉誰是active。
監控狀態,自動備援。
DN: 同時向NN1 NN2發送心跳和塊報告。
ACTIVE NN: 讀寫的操作記錄寫到自己的editlog
? ? ? ? ? ? ? ? ? ? ?同時寫一份到JN集群
? ? ? ? ? ? ? ? ? ? ?接收DN的心跳和塊報告
STANDBY NN: 同時接收JN集群的日志,顯示讀取執行log操作(重演),使得自己的元數據和active nn節點保持一致。
? ? ? ? ? ? ? ? ? ? ? ? 接收DN的心跳和塊報告
JounalNode: 用于active nn和 standby nn節點的數據同步, 一般部署2n+1
ZKFC: 單獨的進程
? ? ? ? ? ?監控NN監控健康狀態
? ? ? ? ? ?向zk集群定期發送心跳,使得自己可以被選舉;
? ? ? ? ? ?當自己被zk選舉為active的時候,zkfc進程通過RPC協議調用使NN節點的狀態變為active,只有是
active狀態才能對外提供服務。
? ? ? ? ? ?對外提供實時服務,是無感知的,用戶是感覺不到的。
總結
HDFS HA架構圖 以三臺機器 為例
HA使用active NN,standby NN兩個節點解決單點問題。
兩個NN節點通過JN集群,共享狀態,
通過ZKFC選舉active,監控狀態,自動備援。
DN會同時向兩個NN節點發送心跳
active nn:
接收client的rpc請求并處理,同時自己editlog寫一份,也向JN的共享存儲上的editlog寫一份。
也同時接收DN的block report,block location updates 和 heartbeat
standby nn:
同樣會接受到從JN的editlog上讀取并執行這些log操作,使自己的NN的元數據和activenn的元數據是同步的,
使用說standby是active nn的一個熱備。一旦切換為active狀態,就能夠立即馬上對外提供NN角色的服務。
也同時接收DN的block report,block location updates 和 heartbeat
jn:
用于active nn,standby nn 的同步數據,本身由一組JN節點組成的集群,奇數,CDH3臺起步,是支持Paxos協議。
保證高可用
ZKFC作用:
1.監控NameNode狀態,ZKFC會定期向ZK發送心跳,使自己被選舉,當自己被ZK選舉為主時,我們的ZKFC進程通過rpc調用,讓nn轉換為active狀態。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





