溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
靜態數據:為了支持決策分析而構建的數據倉庫系統,其中存放的大量歷史數據就是靜態數據。
流數據:以大量、快速、時變的流形式持續到達的數據。(例如:實時產生的日志、用戶實時交易信息)
流數據具有以下特點:
(1)、數據快速持續到達,潛在大小也許是無窮無盡的。 (2)、數據來源眾多,格式復雜。 (3)、數據量大,但是不十分關注存儲,一旦經過處理,要么被丟棄,要么被歸檔存儲(存儲于數據倉庫)。 (4)、注重數據的整體價值,不過分關注個別數據。 (5)、數據順序顛倒,或者不完整,系統無法控制將要處理的新到達的數據元素的順序。
在傳統的數據處理流程中,總是先收集數據,然后將數據放到DB中。然后對DB中的數據進行處理。
流計算:為了實現數據的時效性,實時消費獲取的數據。
批量計算:充裕時間處理靜態數據,如Hadoop。實時性要求不高。
流計算:實時獲取來自不同數據源的海量數據,經過實時分析處理,獲得有價值的信息(實時、多數據結構、海量)。
流計算秉承一個基本理念,即數據的價值隨著時間的流逝而降低,如用戶點擊流。因此,當事件出現時就應該立即進行處理,而不是緩存起來進行批量處理。流數據數據格式復雜、來源眾多、數據量巨大,不適合采用批量計算,必須采用實時計算,響應時間為秒級,實時性要求高。批量計算關注吞吐量,流計算關注實時性。
流計算的特點:
1、實時(realtime)且***(unbounded)的數據流。流計算面對計算的 是實時且流式的,流數據是按照時間發生順序地被流計算訂閱和消費。且由于數據發生的持續性,數據流將長久且持續地集成進入流計算系統。例如,對于網站的訪問點擊日志流,只要網站不關閉其點擊日志流將一直不停產生并進入流計算系統。因此,對于流系統而言,數據是實時且不終止(***)的。
2、持續(continuos)且高效的計算。流計算是一種”事件觸發”的計算模式,觸發源就是上述的***流式數據。一旦有新的流數據進入流計算,流計算立刻發起并進行一次計算任務,因此整個流計算是持續進行的計算。
3、流式(streaming)且實時的數據集成。流數據觸發一次流計算的計算結果,可以被直接寫入目的數據存儲,例如將計算后的報表數據直接寫入RDS進行報表展示。因此流數據的計算結果可以類似流式數據一樣持續寫入目的數據存儲。
為了及時處理流數據,就需要一個低延遲、可擴展、高可靠的處理引擎。對于一個流計算系統來說,它應達到如下需求:
高性能:處理大數據的基本要求,如每秒處理幾十萬條數據。
海量式:支持TB級甚至是PB級的數據規模。
實時性:保證較低的延遲時間,達到秒級別,甚至是毫秒級別。
分布式:支持大數據的基本架構,必須能夠平滑擴展。
易用性:能夠快速進行開發和部署。
可靠性:能可靠地處理流數據。
目前有三類常見的流計算框架和平臺:商業級的流計算平臺、開源流計算框架、公司為支持自身業務開發的流計算框架。
(1)商業級: InfoSphere Streams(IBM)和StreamBase(IBM)。
(2)開源流計算框架,代表如下:Storm(Twitter)、 S4(Yahoo)。
(3)公司為支持自身業務開發的流計算框架:Puma(Facebook)、Dstream(百度)、銀河流數據處理平臺(淘寶)。
Storm是Twitter開源的分布式實時大數據處理框架,隨著流計算的應用日趨廣泛, Storm的知名度和作用日益提高。接下來介紹Storm的核心組件以及性能對比。
Storm的核心組件
Nimbus:即Storm的Master,負責資源分配和任務調度。一個Storm集群只有一個Nimbus。
Supervisor:即Storm的Slave,負責接收Nimbus分配的任務,管理所有Worker,一個Supervisor節點中包含多個Worker進程。
Worker:工作進程,每個工作進程中都有多個Task。
Task:任務,在 Storm 集群中每個 Spout 和 Bolt 都由若干個任務(tasks)來執行。每個任務都與一個執行線程相對應。
Topology:計算拓撲,Storm 的拓撲是對實時計算應用邏輯的封裝,它的作用與 MapReduce 的任務(Job)很相似,區別在于 MapReduce 的一個 Job 在得到結果之后總會結束,而拓撲會一直在集群中運行,直到你手動去終止它。拓撲還可以理解成由一系列通過數據流(Stream Grouping)相互關聯的 Spout 和 Bolt 組成的的拓撲結構。
Stream:數據流(Streams)是 Storm 中最核心的抽象概念。一個數據流指的是在分布式環境中并行創建、處理的一組元組(tuple)的***序列。數據流可以由一種能夠表述數據流中元組的域(fields)的模式來定義。
Spout:數據源(Spout)是拓撲中數據流的來源。一般 Spout 會從一個外部的數據源讀取元組然后將他們發送到拓撲中。根據需求的不同,Spout 既可以定義為可靠的數據源,也可以定義為不可靠的數據源。一個可靠的 Spout能夠在它發送的元組處理失敗時重新發送該元組,以確保所有的元組都能得到正確的處理;相對應的,不可靠的 Spout 就不會在元組發送之后對元組進行任何其他的處理。一個 Spout可以發送多個數據流。
Bolt:拓撲中所有的數據處理均是由 Bolt 完成的。通過數據過濾(filtering)、函數處理(functions)、聚合(aggregations)、聯結(joins)、數據庫交互等功能,Bolt 幾乎能夠完成任何一種數據處理需求。一個 Bolt 可以實現簡單的數據流轉換,而更復雜的數據流變換通常需要使用多個 Bolt 并通過多個步驟完成。
Stream grouping:為拓撲中的每個 Bolt 的確定輸入數據流是定義一個拓撲的重要環節。數據流分組定義了在 Bolt 的不同任務(tasks)中劃分數據流的方式。在 Storm 中有八種內置的數據流分組方式。
Reliability:可靠性。Storm 可以通過拓撲來確保每個發送的元組都能得到正確處理。通過跟蹤由 Spout 發出的每個元組構成的元組樹可以確定元組是否已經完成處理。每個拓撲都有一個“消息延時”參數,如果 Storm 在延時時間內沒有檢測到元組是否處理完成,就會將該元組標記為處理失敗,并會在稍后重新發送該元組。??
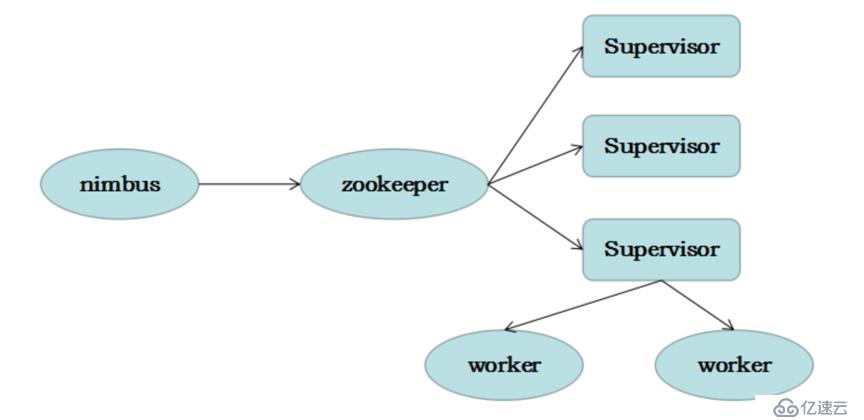
(圖1:Storm核心組件)鄭州不孕不育醫院哪好:http://wapyyk.39.net/zz3/zonghe/1d427.html
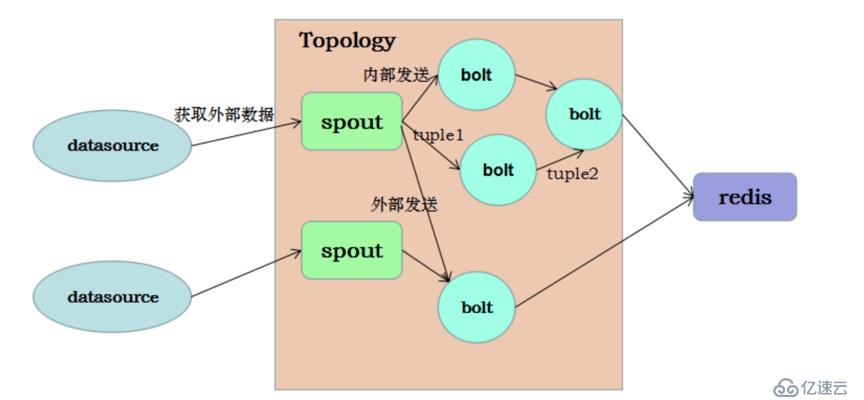
(圖2:Storm編程模型)
主流計算引擎的對比
目前比較流行的實時處理引擎有 Storm,Spark Streaming,Flink。每個引擎都有各自的特點和應用場景。 下表是對這三個引擎的簡單對比。
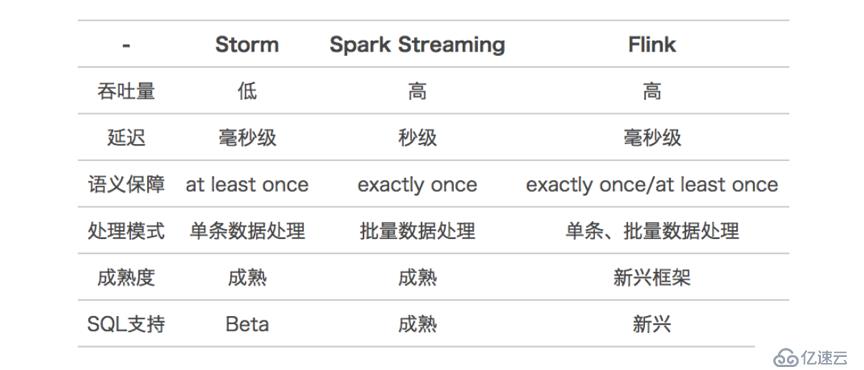
(圖3:主流引擎性能對比)
總結:流計算的出現拓寬了我們應對復雜實時計算需求能力。Storm作為流計算的利器,極大方便了我們的應用。流計算引擎還在不斷發展,基于Storm和Flink開發的JStorm,Blink等計算引擎在性能各方面都有極大的提高。流計算值得我們繼續關注。http://www.360doc.com/showweb/0/0/860282418.aspx
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





