溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“如何優化批量處理接口”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“如何優化批量處理接口”吧!
同批量導入一樣,在我們的系統中,存在著大量的批量處理的接口,比如批量獲取運單,批量出庫,批量打印,等等,像這樣的接口大概有10幾個。
這些請求往往具有以下幾個特點:
單條數據處理耗時較長,一般來說都在200ms及以上
數據批量較大,像我們系統最大一頁是1000條數據,用戶可選擇的最大批量也就是1000
總體耗時較長,比如按200ms和1000條數據算,總共就需要耗時200s,這個時間太長了
這些單條的數據無法合并在一起進行處理
所以,我們有必要對批量處理的接口進行統一的性能優化。
但是,要如何進行優化呢?
我們知道單臺機器的性能是有上限的,像這種批量請求,一方面會占用大量的內存,同時也會占用很高的CPU,全部放在同一個進程里面處理勢必導致整體處理時間更進一步上升,所以,針對這種批量的請求,最好的辦法就是分而治之。
什么是分而治之呢?
分而治之,在很多場景中都有用到,比如上一篇我們說的批量導入,它一般分成四個部分:
接收請求
分發請求
處理請求
匯總請求
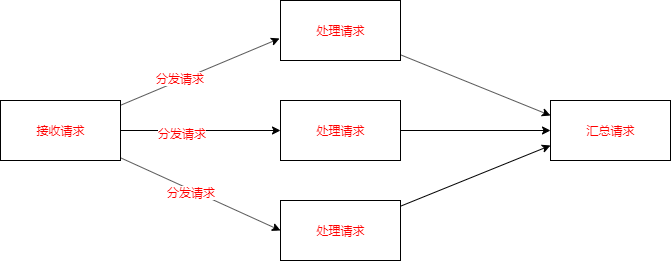
那么,在我們這個批量處理的過程中如何應用分而治之的思想呢?
首先,我們要把大批量請求改成一個一個的小請求,這里的“改”是指我們后端來改,而不是前端調用來修改,前端還是調用大批量的請求。
然后,通過某種機制把這些小請求分發到多臺機器上進行處理,比如,使用Kafka來做分發器。
最后,再統計每個小請求的完成情況,當所有的小請求都完成了之后,就通知前端整個請求已完成。
這里的通知可以走消息模塊,同時,上面的完成小請求的改造后就可以返回前端了,等到這里全部完成再異步通知。
好了,我們直接來看我的架構設計圖:
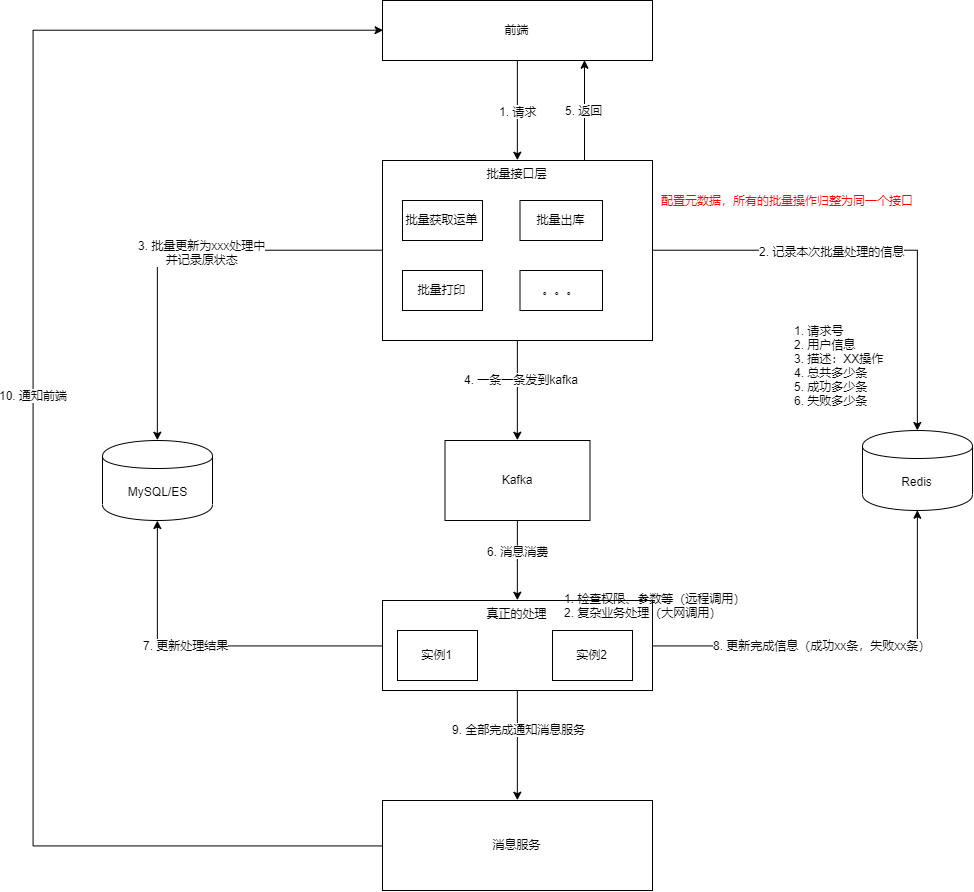
整體來說,還是蠻復雜的,讓我們每個步驟來過一遍:
接收請求,前端請求后端的大批量接口
記錄本次批量處理請求的信息,比如分配請求號、哪個用戶、哪個操作、總共多少條、成功0條、失敗0條,等等
批量更新數據庫中這些數據的狀態為xxx處理中,并記錄原來的狀態,這里使用mysql的批量更新,速度很快
把大批量的數據一條一條的發到Kafka中,Kafka承擔了分發器的作用
給前端返回響應,說明本次請求收到了,并且在處理中了,這樣界面上查詢的結果就是這些單據正在xxx處理中
多個服務實例從Kafka拉取消息來消費
針對每一條數據進行處理,比如檢查權限、參數,處理復雜的業務邏輯,等等,并寫入mysql處理的結果
記錄每一條數據的處理結果到redis中,比如成功條數+1,失敗條數+1,等等
當檢測到所有數據都處理完了,即總共條數=成功條數+失敗條數,就發個消息到消息服務
消息服務發送一個新的通知給前端:您剛才進行的XXX操作已完成,成功X條,失敗X條
前端收到這個通知后,檢查如果還在這個界面,就自動刷新下頁面,等等,可以做一些很友好的交互
這就是整體批量請求的處理過程,怎么樣,還可以接受不?
另外,因為我們系統中的批量處理接口實在是太多了,如果每個接口都這樣實現一遍,有很多重復的代碼。
所以,我們可以做一個通用的批量接口,通過配置元數據的形式實現,元數據的格式為:{action: xx操作,targetStatus: xx處理中},這樣除了中間的處理消息的過程無法復用外,其他的部分都是可以復用的。
好了,接著我們再來回顧下這種騷操作可以運用到哪些場景呢?
單條數據處理耗時較長,如果單條數據處理耗時非常短則沒必要
數據批量較大,如果一次批量不大則沒必要
總體耗時較長,上面兩個因素的疊加,如果總體耗時不長則沒必要
無法進行批量更新數據庫的場景,如果可以批量更新數據庫則沒必要
最后,我們再看看還有哪些改進措施呢?
我認為主要有以下兩種改進措施:
不一定每次請求都是大批量,比如說,如果一次請求的數據量小于10條,是不是本機直接處理更快呢?
不是每個批量場景都需要優化,見上面運用場景分析的沒必要場景
到此,相信大家對“如何優化批量處理接口”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





