溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“Reindex性能優化方法是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
5.X版本后新增Reindex。Reindex可以直接在Elasticsearch集群里面對數據進行重建,如果你的mapping因為修改而需要重建,又或者索引設置修改需要重建的時候,借助Reindex可以很方便的異步進行重建,并且支持跨集群間的數據遷移。
reindex的核心做跨索引、跨集群的數據遷移。 慢的原因及優化思路無非包括:
batch size值可能太小(默認是1000)
reindex的底層是scroll實現,借助scroll并行優化方式,提升效率
跨索引、跨集群的核心是寫入數據,考慮寫入優化角度提升效率
默認情況下,_reindex使用1000進行批量操作,您可以在source中調整batch_size。
POST _reindex
{
"source": {
"index": "source",
"size": 5000
},
"dest": {
"index": "dest",
"routing": "=cat"
}
}
批量大小設置的依據:
使用批量索引請求以獲得最佳性能。
批量大小取決于數據、分析和集群配置,但一個好的起點是每批處理5-15 MB。
注意:這是物理大小。文檔數量不是度量批量大小的好指標。例如,如果每批索引1000個文檔,:
1)每個1kb的1000個文檔是1mb。
2)每個100kb的1000個文檔是100 MB。
這些是完全不同的體積大小。逐步遞增文檔容量大小的方式調優。
從大約5-15 MB的大容量開始,慢慢增加,直到你看不到性能的提升。然后開始增加批量寫入的并發性(多線程等等)。
使用kibana、cerebro或iostat、top和ps等工具監視節點,以查看資源何時開始出現瓶頸。如果您開始接收EsRejectedExecutionException,您的集群就不能再跟上了:至少有一個資源達到了容量。要么減少并發性,或者提供更多有限的資源(例如從機械硬盤切換到ssd固態硬盤),要么添加更多節點。如果要進行大量批量導入,請考慮通過設置index.number_of_replicas來禁用副本:0。
主要原因在于:復制文檔時,將整個文檔發送到副本節點,并逐字重復索引過程。 這意味著每個副本都將執行分析,索引和潛在合并過程。 相反,如果您使用零副本進行索引,然后在提取完成時啟用副本,則恢復過程本質上是逐字節的網絡傳輸。 這比復制索引過程更有效。
PUT /my_logs/_settings
{
"number_of_replicas": 0
}
如:
PUT /regroupmembers-20.11.12-151612/_settings
{
"number_of_replicas": 0
}
說明:92萬數據測試環境正常需要85分鐘,去掉副本分片之后需要30分鐘Reindex支持Sliced Scroll以并行化重建索引過程。 這種并行化可以提高效率,并提供一種方便的方法將請求分解為更小的部分。
sliced原理(from medcl)
用過Scroll接口吧,很慢?如果你數據量很大,用Scroll遍歷數據那確實是接受不了,現在Scroll接口可以并發來進行數據遍歷了。
每個Scroll請求,可以分成多個Slice請求,可以理解為切片,各Slice獨立并行,利用Scroll重建或者遍歷要快很多倍。
slicing使用舉例
slicing的設定分為兩種方式:手動設置分片、自動設置分片。
手動設置分片參見官網
自動設置分片如下:
POST _reindex?slices=5&refresh
{
"source": {
"index": "twitter"
},
"dest": {
"index": "new_twitter"
}
}
slices大小設置注意事項:
1)slices大小的設置可以手動指定,或者設置slices設置為auto,auto的含義是:針對單索引,slices大小=分片數;針對多索引,slices=分片的最小值。
2)當slices的數量等于索引中的分片數量時,查詢性能最高效。slices大小大于分片數,非但不會提升效率,反而會增加開銷。
3)如果這個slices數字很大(例如500),建議選擇一個較低的數字,因為過大的slices 會影響性能。如果你的搜索結果不需要接近實時的準確性,考慮先不要急于索引刷新refresh。默認值是1s,在做reindex時可以將每個索引的refresh_interval到30s或禁用(-1)。
如果正在進行大量數據導入,reindex就是此場景,先將此值設置為-1來禁用刷新。完成后再重置回需要的值!
設置方法:
PUT /index_name/_settings
{ "refresh_interval": -1 }
還原方法:
PUT /index_name/_settings
{ "refresh_interval": "30s" }索引數據量:71460992
持續時間:55分鐘
1.設置Refresh:
PUT /regroupmembers-20.11.23-000000/_settings
{
"refresh_interval": "30s"
}
2.設置Batch_size:
POST _reindex
{
"source": {
"index": "regroupmembers-20.05.28-142940",
"size": 4000
},
"dest": {
"index": "regroupmembers-20.11.23-000000"
}
}
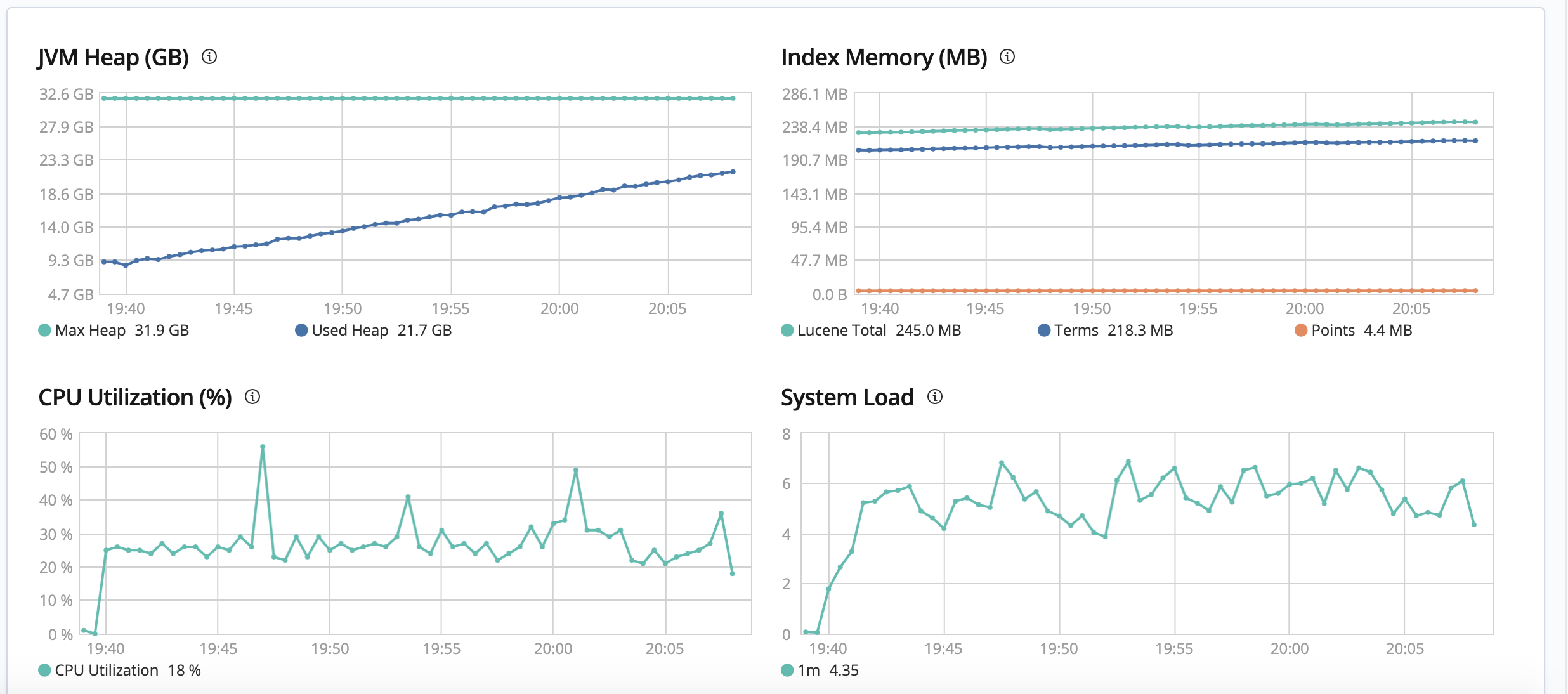
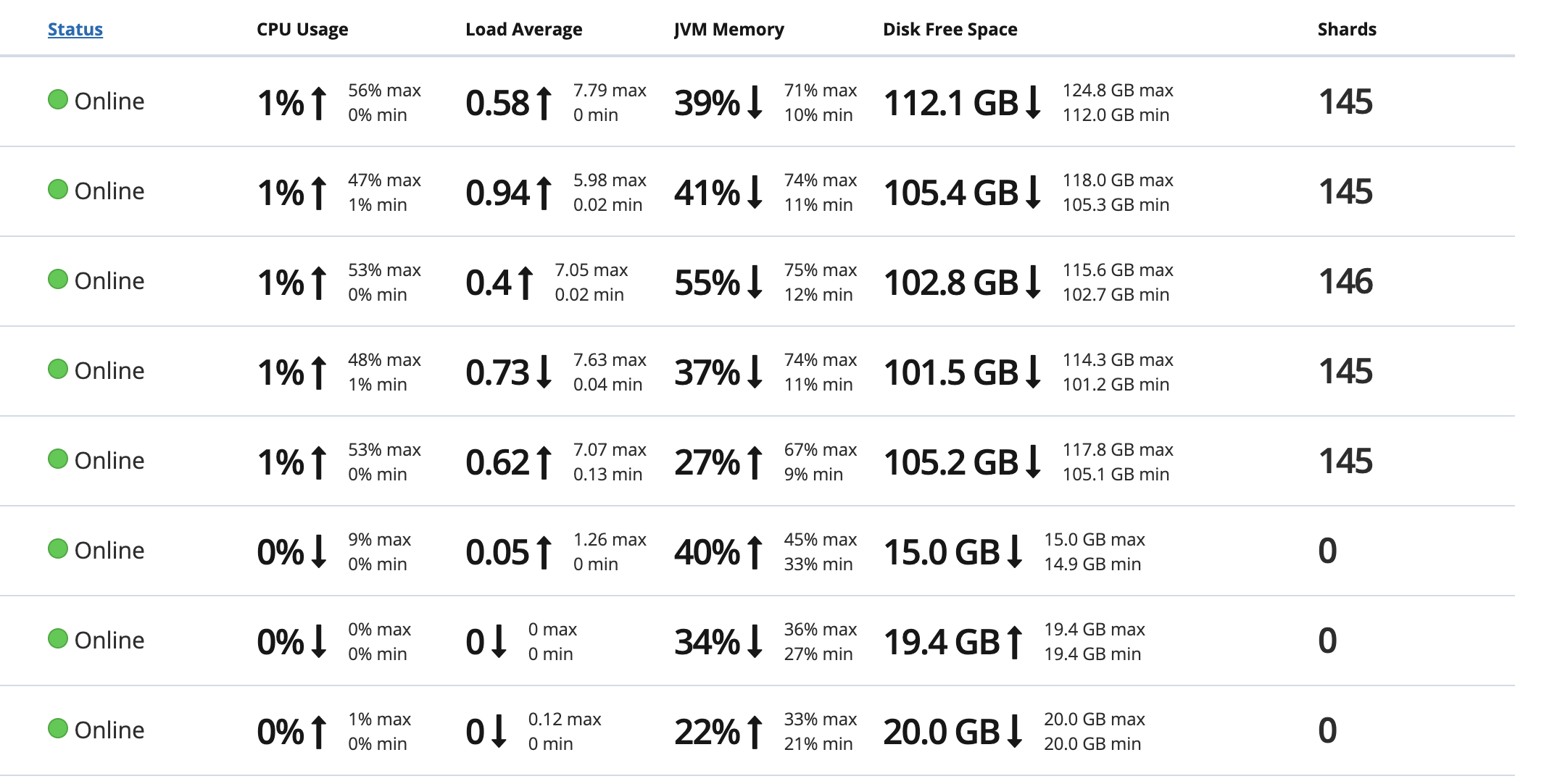
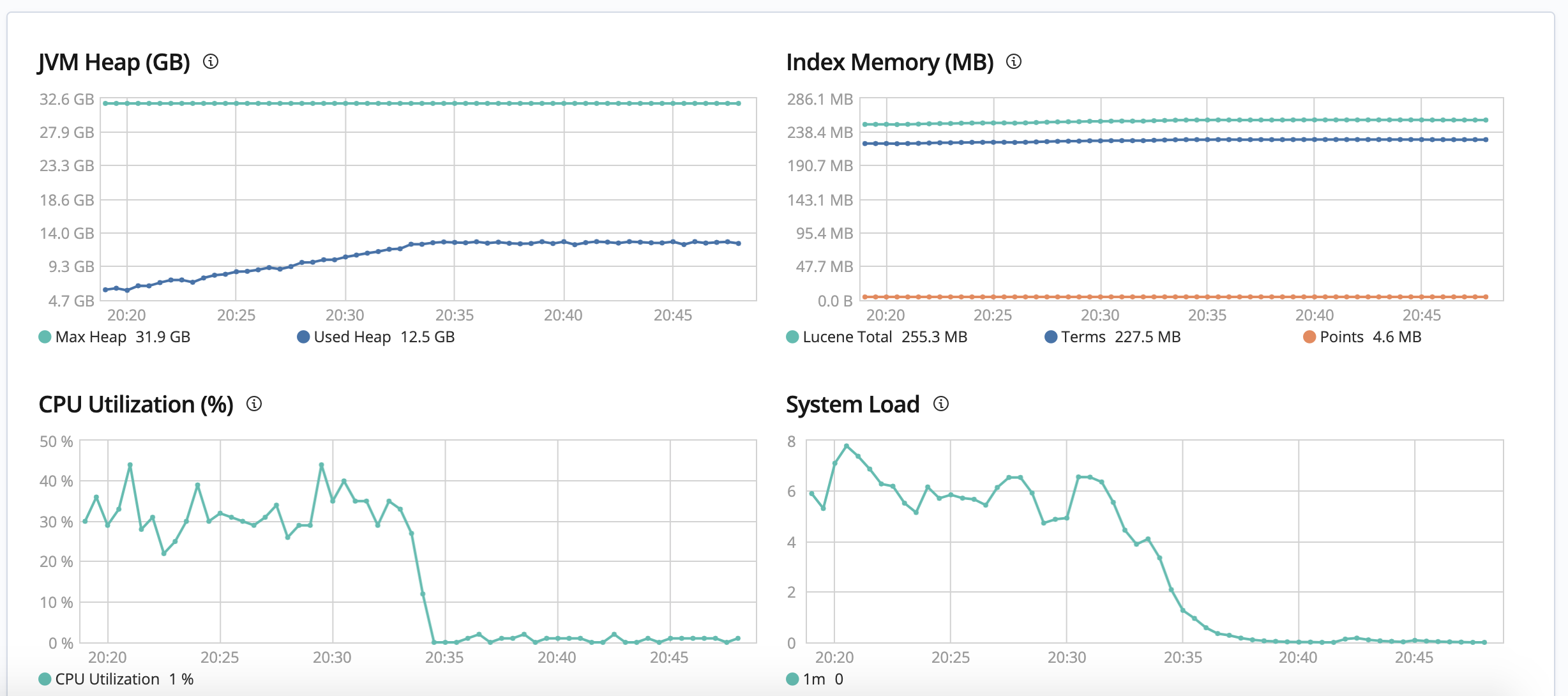
3.設置副本分片:0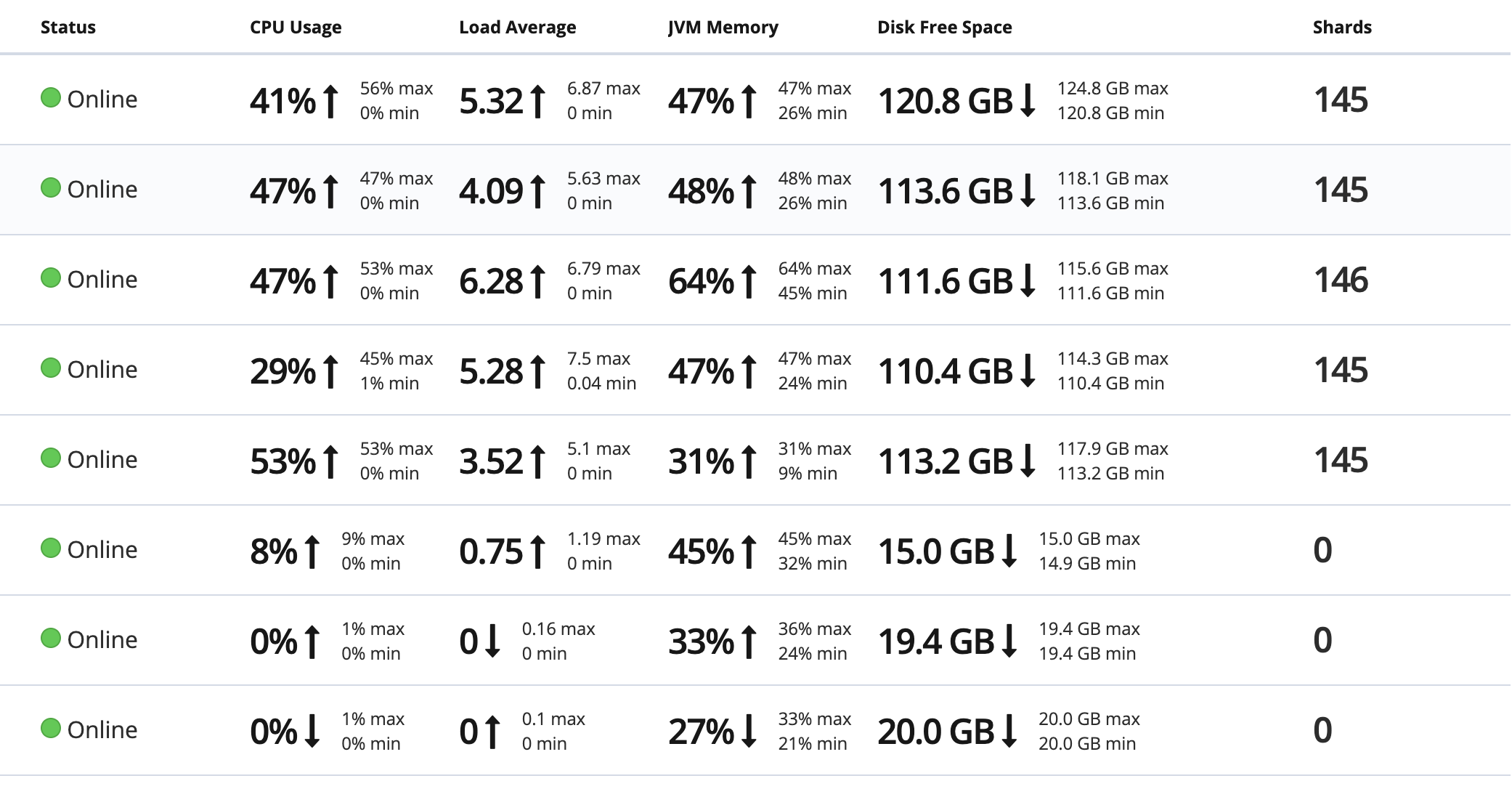
“Reindex性能優化方法是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





