溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“Python基礎語法和數據類型總結”,在日常操作中,相信很多人在Python基礎語法和數據類型總結問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”Python基礎語法和數據類型總結”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
Python最全基礎總結
集合操作
集合運算
字典類型操作方法
list
list操作函數
編寫第一個程序
Python中的注釋
Python代碼基本架構
數據類型
運算符
內置函數
字符串類型
使用%占位符格式化字符串
使用format()函數格式化字符串
使用f-string來格式化字符串
字符串操作
list和tuple
tuple
字典類型
集合類型
哈哈,入門語言,當然第一句話就是hello world,相比于C和Java,Python的語法格式非常簡單,直接print()即可
下面我們開始寫第一個程序:輸出Hello World!

它會輸出一個字符串”Hello World!“。
如果多次調用print()函數,如下:

可以看到,每條print()語句,都會占一行。如果想將上面的三句話輸出到同一行,可以這樣:

通過給print加上end="",將print()函數原來默認的輸出內容后加上換行,改成了輸出內容后加上空字符串,這樣就不會換行了。另外,print()中除了可以接收字符串參數外,也可以接收其他任何參數,還可以調用函數,將函數執行結果打印出來。還可以是一個表達式,將表達式的運行結果打印出來。

在上一端代碼中,我們在print()語句后,使用 #給代碼加入了注釋。這是很常用的一種注釋方式:單行注釋。
如果有多行的注釋,可以使用三對雙引號或者單引號將其包裹起來:

除了上面兩種注釋外,還有一種特別的注釋,那就是文檔注釋。文檔注釋主要是用于自動生成幫助文檔,它對于格式和位置有一定要求。
如果你的程序可能會被其他人用到,為了方便他們,避免它們查看你的代碼來獲得試用方法,應該提供文檔注釋,并生成文檔提供給他們。
文檔注釋必須是包、類或函數里的第一個語句。這些字符串可以通過對象的doc成員被自動提取,并且可以被pydoc使用。而且文檔注釋必須使用三對單引號或者雙引號來注釋,不能使用#

為了更好更清晰地說明函數的作用,函數的文檔應該遵循一定的規則:
Args:列出每個參數的名字,并在名字后使用一個冒號和一個空格,分隔對該參數的名稱和描述。如果描述太長超過了單行80字符,使用2或者4個空格的懸掛縮進
Returns:該函數的返回值,包括類型和具體返回值的情況。如果沒有返回值或者返回None值可以不寫
Raises:拋出的異常。不拋出異常不寫。

在前面的幾個程序中,我們基本能體會到Python程序的一些特點。
首先,Python代碼中,不使用{}或者其他明顯的標志來限制代碼的開始和結束,而是根據代碼的縮進來確定代碼的關系:連續的同一縮進的代碼為同一個代碼塊,例如函數中的定義。
一條語句的末尾,不需要使用;來結束,而直接使用換行表示語句末尾。
除此外,Python還有一些頗具特色的寫法,例如,如果一條語句太長,可以使用”\“將它分割成多行:

雖然Python中可以不使用;作為語句的分割,但如果在一行中有多條語句,那可以使用;將這些語句分隔開:

在上面這些代碼中,我們定義了變量a、b、x、y等。可以看出,在Python中,和很多其他編程語言不一樣的地方,Python的變量不需要聲明為具體的類型,而是直接給它賦值,Python會根據值設置變量的類型。雖然Python的變量不需要先聲明類型直接就可以使用,但并不是說Python沒有數據類型。Python的常用數據類型包括:
number(數字)
int(整型)
float(浮點型)
complex(復數):復數由實數部分和虛數部分構成,可以用 a + bj,或者 complex(a,b) 表示, 復數的實部 a 和虛部 b 都是浮點型
bool
string(字符串)
list(列表)
tuple(元組)
set(集合)
dict(字典)
這些類型,我們在后續課程將會一一講到。
在Python中,提供了常用的運算符。我們先來看看它的數學運算符。
/
%:取余
//:整除
**:乘方


可以看到,整數和浮點數的運算,結果都是浮點數。如果想將浮點數轉換成整數,可以這樣:

或者將整數轉換成浮點數:

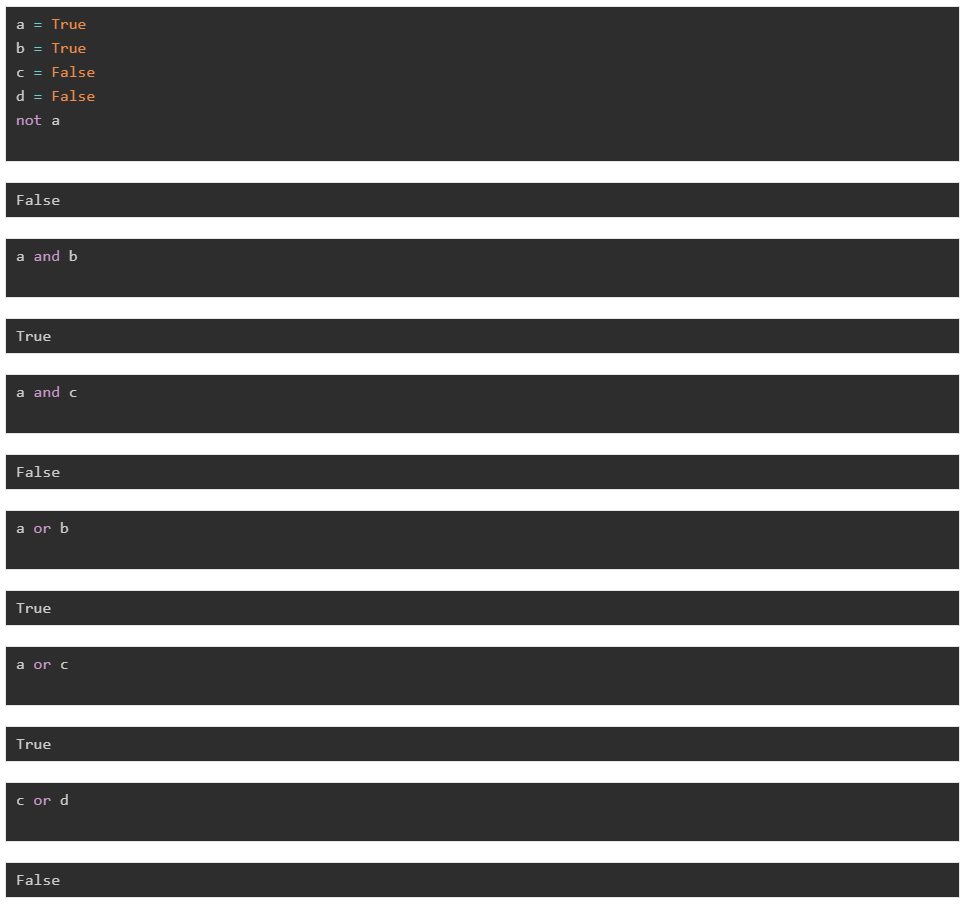
bool 類型只有兩個值:True或者False。它的運算操作有 not、and、or

所謂內置函數,就是Python語言本身已經定義好的給我們可以直接使用的函數,例如前面用到的print()、abs()、int()、float()等。這些函數后面我們都會在適當的地方講到。
前面我們講了print(),我們來看看輸入。
輸入使用input(),它接收一個字符串作為顯示給用戶的提示信息,用戶輸入后,將會以字符串形式返回給程序。

字符串是最常用的數據類型之一,它用來表示一串不可變的字符。
字符串可以使用雙引號或者單引號將字符包含起來
如果字符串中本來就含有單引號或者雙引號,可以通過下面的方法來處理:
如果字符串中包含單引號,則使用雙引號來包裹這個字符串,反之,如果字符串中包含雙引號,則使用單引號來包裹這個字符串,例如:

如果字符串中即有單引號又有雙引號,則可以對字符串內的單雙引號進行轉義,即在字符串內的單雙引號前面加上\,例如:

中文的全角單雙引號不受影響,即中文單雙引號會被當做普通字符。對于內容復雜的字符串,也可以使用""""""或者’’’’’'來包裹字符串,此時無論里面有單引號還是雙引號,均會被原封不動地正確處理。
有時候,我們可能需要在字符串中加入一些不確定的內容,例如,根據用戶的輸入,輸出語句問候語:

這種方式可以實現我們的目的,但它在可讀性和性能上都不夠優化。所以在Python中陸續提供了三種格式化字符串的方式。我們先來看第一種:使用占位符%。如果將上面的代碼改成使用%占位符,它可以修改成如下:

這種方式的好處是,%占位符可以自動將非字符串類型的數據轉換成字符串,并和字符串其他部分相連接,形成新的字符串。
它的標準格式是:%[(name)][flags][width].[precision]typecode

除了f、s、d外的其他格式字符,請見下面例子:

指定name的方式:

這種格式化數據慢慢被拋棄了,因為它的占位符和值之間必須一一對應,在占位符比較多的時候,比較容易出錯。

著這種方式下,使用{}作為占位符,但它的好處在于可以給它指定順序,例如:

還可以加入變量:

考慮下面這種情況:A喜歡B,可B不喜歡A
如果A、B待定,用前面的格式化方式定義如下:”%s喜歡%s,可%s不喜歡%s” %(“A”,“B”,“B”,“A”)
這種方式的問題在于:
都用%s來指定,看不出A、B的區別
A、B其實各重復了一次,如果重復多次,需要重復寫更多次。
如果用format()函數,可以寫成:

當然,在format()中也可以使用類似%一樣的數據類型等設置:

指定長度和精度:
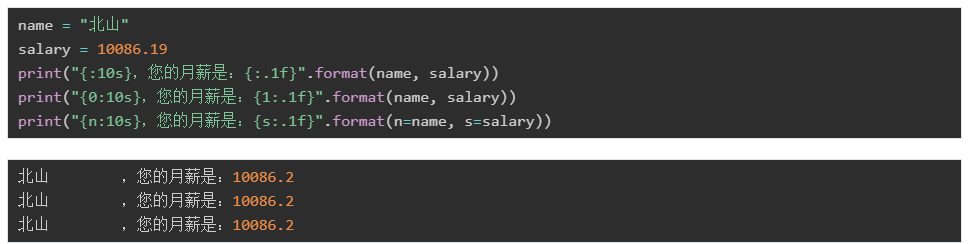
另外,在指定了長度之后,如果對應的值不足,可以指定補足的字符(默認是空格,例如上面北山啦后面的空格),此時必須配合對齊方式來使用:
“<”:左對齊
“^”:居中對齊
“>”:右對齊

format()方法相比較%來說已經有明顯的改進,但在某些復雜情況下,還是顯得不夠靈活。例如:

可以看到,一旦參數比較多,在使用format()的時候,需要做比較多的無用功。其實如果能直接在{}中,和變量直接一一對應,那就方便很多了。可以使用f-string改成

因為f-string的{}中的內容,會在運行時進行運算,因此在{}中也可以直接調用函數、使用表達式,例如:

對于多行文字,為了讓代碼更美觀易讀,應該寫成如下方式:

當然,在f-string中也可以使用上面的各種限制:

再如:
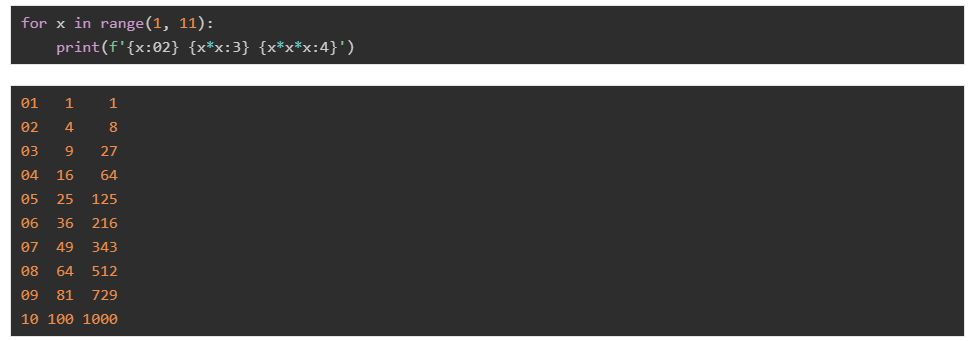
指定對齊方式:

不同進制、不同表示方式的數字:

如果要從字符串中獲得其中的一段子字符串,可以通過str[start:end]的方法來獲得。其中start為開始索引,end為結束索引,但end對應索引的字符不包含在內。如果只取單個字符,則只需要指定start參數就可以了。

我們經常需要對字符串進行操作,所以Python提供了很多字符串操作的函數供我們使用。
capitalize():字符串首字母大寫
title():將字符串中各個單詞的首字母大寫
lstrip()、rstrip()、strip():分別用于去除字符串左邊、右邊和左右兩邊的空格
需要注意的是,上面這些方法,都不會改變原有字符串內容,而是新生成字符串
startswith(prefix, start, end):該字符串是否以某個字符串開始
endswith(suffix, start, end):該字符串是否已某個字符串結尾
find(s, start, end):從字符串中從左到右尋找是否包含字符串s,返回找到的第一個位置。如果沒找到,返回-1
rfind(s, start, end):和find()類似,只不過它從右到左尋找
index(s, start, end):和find()類似,但如果沒找到將會返回錯誤
rindex(s, start, end):和index()類似,只不過它從右到左尋找
isalnum():如果字符串中至少有一個字符,且字符串由數字和字母組成,則為true。
isalpha():如果字符串中至少有一個字符,且字符串由字母組成,則為true
isdigit():是否為數字(整數),小數點不算,只支持阿拉伯數字
isnumeric():是否為數字。支持本地語言下的數字,例如中文“一千三百”、“壹萬捌仟”等
replace(s1, s2):將字符串中的s1替換成s2

下面我們看一個綜合案例。
指定字符串中,將字符串中和第一個字母一樣的字母(除第一個字符本身外),都替換成另一個字符“@”,例如:little,替換后成為litt@e,即將little中所有的l(第一個字母是l)都替換成@(除了第一個字母本身),下面是一種實現思路:

使用列表list或者元組tuple,可以存放一系列的數據,例如,將班級所有同學的名字放在一起:
names = [“北山啦”, “李四”, “王五”]
list是一種有序的、可變的數據集合,可變的意思就是可以隨時往里添加或者刪除元素。
可以通過索引從中取出元素,例如names[1]將取出第二個數據(索引從0開始)。
如果索引超出范圍(例如索引大于等于列表個數),將會報錯
索引可以是負數,負數表示從后往前計數取數據,最后一個元素的索引此時為-1

列表中的元素,其數據類型不一定要一樣。甚至可以使用列表數據作為另一個列表的元素。如:
names = [“北山啦”,“李四”, [“Leonardo”,“Dicaprio”], “王五”],其中,第三個元素(索引為2)為另一個列表
此時,names[2]取出來的值是列表[“Leonardo”,“Dicaprio”],要取Leonardo這個值,則需要在這個列表[“Leonardo”, “Dicaprio”]上使用索引0去獲取,因此,可以通過names[2][0]取得

如果要從列表中取出一定范圍內的元素,則可以使用list[start:end]的方式來獲取,例如:names[1:3]取出從索引1開始到索引3結束(不包含索引3)的2個元素。
start如果省略,表示從0開始
end如果省略,表示到列表最后一個元素結束

如果要創建一系列數字為內容的列表,可以結合list()函數和range()函數來創建,例如,創建包含數字0-99的列表:
print(list(range(100))) [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62, 63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82, 83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99] range(0, 100)
range()的函數原型:
range(stop) :0開始計數,計數到stop結束,但不包括stop,例如:range(10),生成的數字范圍是0-9
range(start, stop[, step]):計數從 start 開始,到stop結束(不包括stop),step是步長,即每次變化的范圍,默認為1,即每次加1
start/stop/step均可以為任意整數
“start < stop”,才能生成包含元素的range,如果stop< start,則為空。

append(element):往列表最后附加一個元素
insert(index, element):往列表指定索引位置插入一個元素
可以直接給指定索引元素賦值,用新值替代舊值:names[idx]= value
pop()將最后一個元素從列表中取出來,并從列表中刪除該元素
如果要刪除列表中的一個索引對應的元素,可以使用del list[idx]的方式
extend(seq):在原來的列表后追加一個系列
remove(obj):從列表中刪除第一個匹配obj的元素
clear():清空整個列表
count(obj):計算元素obj在列表中出現次數
sort(key=…, reverse=…):給list排序,可以指定用于排序的key。reverse用于指定是否反序。

[0, 5, 10, 15, 20, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 0, -5, -10, -15, -20, -25, -30, -35, -40, -45, -50, -55, -60, -65, -70, -75, -80, -85, -90, -95]
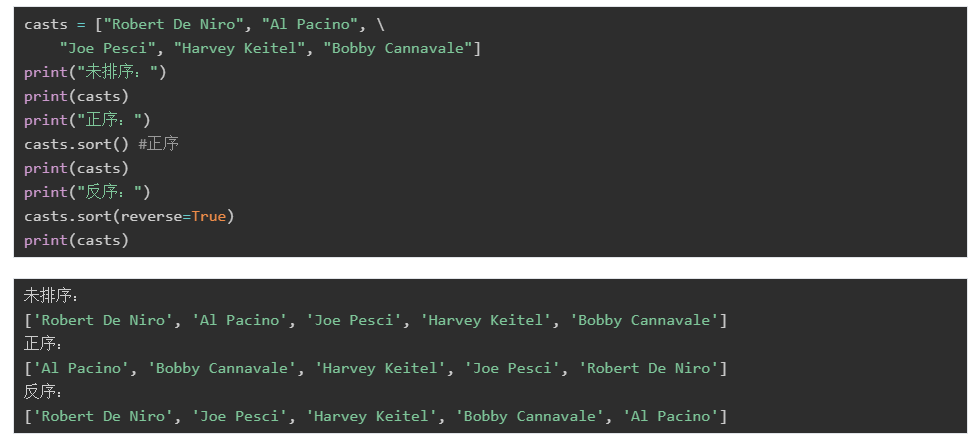
下面我們來看一個更復雜的列表:
the_irishman = [[“Robert”, “De Niro”], [“Al”, “Pacino”],
[“Joe”, “Pesci”], [“Harvey”, “Keitel”], [“Bobby”, “Cannavale”]]
假設我們現在要給它進行排序,那么應該是按照first name還是last name來排序呢?
此時就需要用到sort()函數中的key參數了。通過key可以給它指定一個函數,這個函數來限制應該按照first name還是last name來排序:
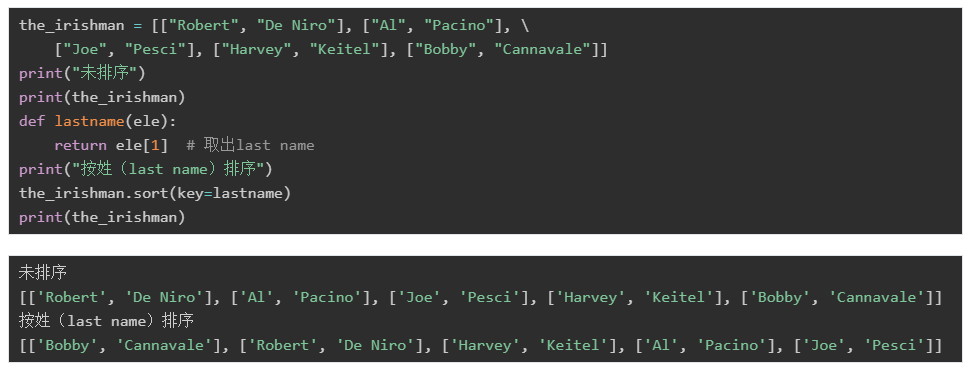
tuple和列表類似,它們的區別在于tuple是不可變的,即如果元組初始化了,則不能改變,tuple沒有pop()/insert()這些方法。
需要注意的是,這里的不可變,指的是不能直接將tuple元素改變成另一個元素,但如果tuple的元素是一個可變對象,例如list,那么,list里面的內容是可以改變的,但不能用另一個list去替換tuple中既有的list。

元組還有一個需要特別注意的地方是只有一個元素的元組數據的定義。因為()還是表達式中使用的符號(用來改變操作符順序),因此如果只有一個元素,定義成 names = (“北山啦”),此時()會被當做表達式符號,這里就會被忽略掉,因此names的值此時為字符串”北山啦”,而不是元組類型。為避免這種情況,可以這樣定義單個元素的元組數據:names = (“北山啦”,)

另外還可以使用下面的方法創建元組:

列表和元組均可以乘以一個整數n,表示將原來列表或者元組中的數據復制n份生成新列表或者元組:

列表和列表之間、元組和元組之間,可以使用“+”將兩個列表或者元組中的數據合并成新的列表或者元組

注意,tuple和list是不能合并的。
如果想逐個取出列表或者元組中的元素,可以通過for…in…的方式逐個取出元素:

字典(dict)是用于保存鍵-值(key-value)對的可變容器數據。
字典的每個鍵值(key-value)對用冒號(:)分割,每個鍵值對之間用逗號(,)分割,整個字典包括在花括號({})中 ,格式如下所示:
d = {key1 : value1, key2 : value2 }
注意,字典中的key必須唯一,即不能有兩對key一樣的元素。
可以通過d[key]的方式,獲得對應key的value。如果不存在對應的key,則會報錯。

{'Phoenix': 'Suns', 'Atlanta': 'Hawks', 'Boston': 'Celtics', 'Chicago': 'Bulls', 'Denver': 'Nuggets', 'Detroit': 'Pistons', 'Los Angels': 'Clippers'}
Suns給字典增加數據,可以通過
d[new_key] = new_value
修改某個key對應的值
-d[key] = new_value
刪除某個key對應的元素
del d[key],將會刪除key對應的鍵值對,不僅僅是刪除值
del d,將會刪除整個字典數據

{'Phoenix': 'Suns', 'Atlanta': 'Hawks', 'Boston': 'Celtics', 'Chicago': 'Bulls', 'Denver': 'Nuggets', 'Detroit': 'Pistons', 'Los Angels': 'Lakers', 'Orando': 'Magics'}為了避免key的不唯一,要求key只能使用不變的數據做key,例如:數字、字符串、元組。list因為是可變數據,所以不能當做key。
items():以列表返回可遍歷的(鍵, 值) 元組數組
keys():返回一個包含所有鍵的可迭代對象,可以使用 list() 來轉換為列表
values():返回一個包含所有值的可迭代對象,可以使用 list() 來轉換為列表
pop(key[,default]):取出對應key的值,如果不存在,則使用default值
popitem():取出字典中最后一個key-value對
get(key[,default]):取出對應key的值,如果不存在這個key,則使用default值
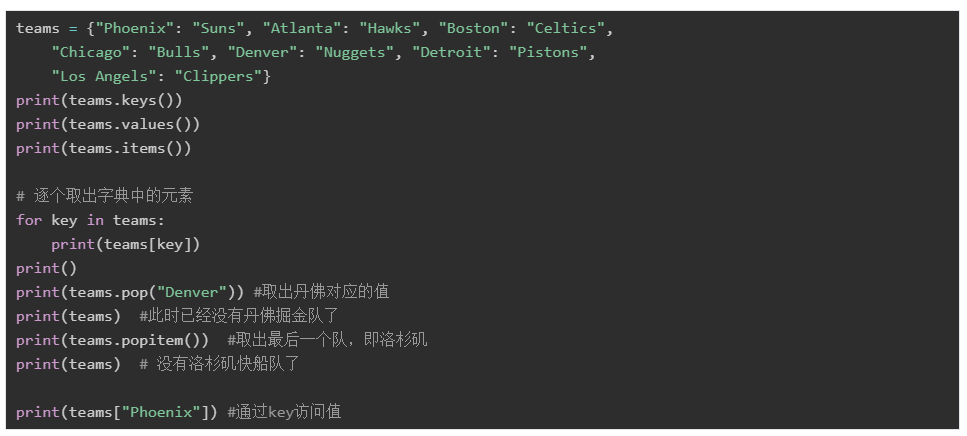
dict_keys(['Phoenix', 'Atlanta', 'Boston', 'Chicago', 'Denver', 'Detroit', 'Los Angels'])
dict_values(['Suns', 'Hawks', 'Celtics', 'Bulls', 'Nuggets', 'Pistons', 'Clippers'])
dict_items([('Phoenix', 'Suns'), ('Atlanta', 'Hawks'), ('Boston', 'Celtics'), ('Chicago', 'Bulls'), ('Denver', 'Nuggets'), ('Detroit', 'Pistons'), ('Los Angels', 'Clippers')])
Suns
Hawks
Celtics
Bulls
Nuggets
Pistons
Clippers
Nuggets
{'Phoenix': 'Suns', 'Atlanta': 'Hawks', 'Boston': 'Celtics', 'Chicago': 'Bulls', 'Detroit': 'Pistons', 'Los Angels': 'Clippers'}
('Los Angels', 'Clippers')
{'Phoenix': 'Suns', 'Atlanta': 'Hawks', 'Boston': 'Celtics', 'Chicago': 'Bulls', 'Detroit': 'Pistons'}
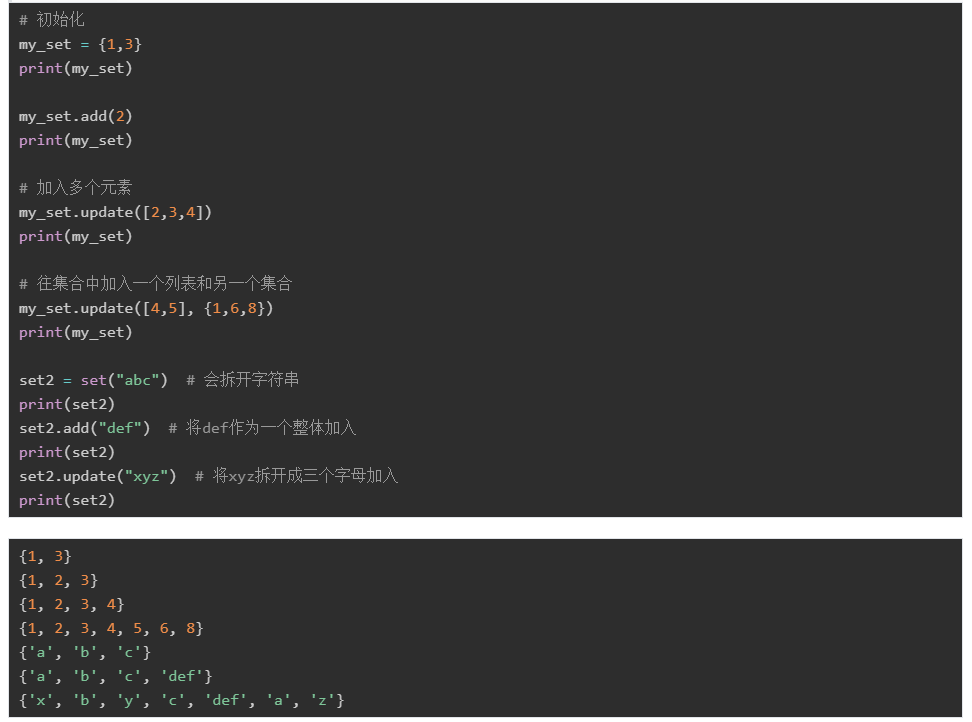
Suns集合(set)是一個無序的不重復元素序列。可以使用set()或者{}來創建一個集合:
如果使用{}創建集合,要注意和字典數據類型的區別——字典數據里是key-value對,而這里是單個的數據
如果創建空集合,不可以使用{},因為系統會首先將其當做字典數據類型來處理。所以空集合請使用set()來創建
如果往集合中放入重復元素,將只會保留一個。
從字符串創建一個集合:

從列表創建一個集合:

從元組創建一個集合:

從字典創建一個集合,此時只會取key作為集合的元素:

- add():往set中增加一個元素,如果該元素已經在set中,則不會成功。參數只能是單個元素,不能使list、tuple或者set
- update(seq):往set中添加多個元素。seq可以是字符串、tuple、list或者另一個set
- 需要注意:add()和update()都是字符串作為參數的時候,兩者的區別:add()把字符串當做一個整體加入,而update()會將字符串中的單個字符逐個加入
- discard(item):從集合中刪除指定的元素。
- remove(item):從集合中刪除指定的元素。如果該元素不存在,會報錯。
- pop():從集合中移除一個元素。因為集合是無序的,所以不能確保移除的是哪一個元素
- clear():清空整個集合
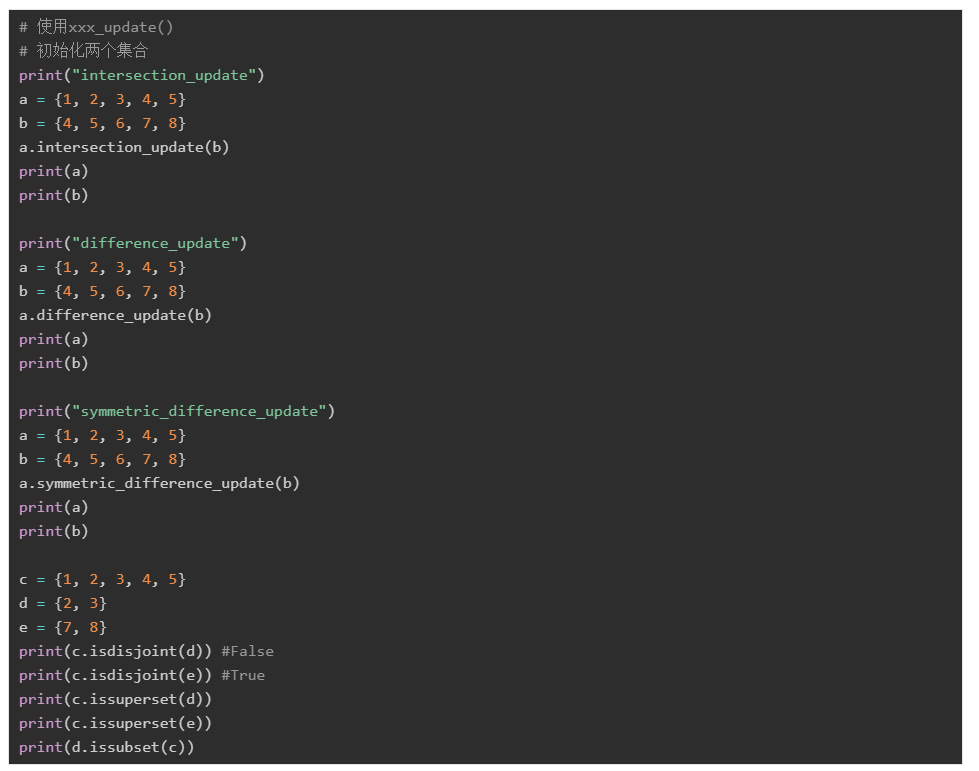
集合之間,可以進行集合操作,主要的集合操作有:
交集(intersection):兩個集合操作,生成一個新的集合:只有兩個集合中都有的元素,才會被放到新的集合中
可以使用運算符&或者函數intersection()來進行交集操作
并集(Union):兩個集合生成一個新的集合,兩個集合中的元素都會放到新的集合中
可以使用|操作符或者union()函數進行并集操作
差集(difference):兩個集合生成新的集合,在原集合基礎上,減去兩者都有的元素,生成新的集合。
可以使用-操作符或者difference()函數來進行差集操作
對稱差集( symmetric difference):兩個集合生成新的集合,新集合中的元素是兩個集合的元素減去兩者一樣的元素。
可以使用^操作符或者symmetric_difference()函數進行對稱差集操作

其他操作:
symmetric_difference_update()/ intersection_update()/ difference_update()/update():還是進行前面的對應交、并、差、對稱差操作,但將運算的結果,更新到這個集合。
isdisjoint():a.isdisjoint(b),a和b兩個集合是否沒有交集,沒有交集返回True
issubset():a.issubset(b),a是否為b的子集,是返回True
issuperset():a.issuperset(b),a是否為包含b的所有元素,包含返回True

到此,關于“Python基礎語法和數據類型總結”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





