溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“分布式數據庫的基本概念”,在日常操作中,相信很多人在分布式數據庫的基本概念問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”分布式數據庫的基本概念”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
1.單庫,就是一個庫

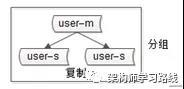
3.分組(group),分組解決可用性問題,分組通常通過主從復制(replication)的方式實現。(各種可用級別方案單獨介紹)
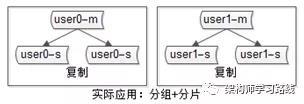
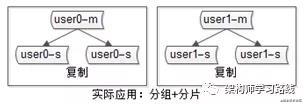
4.互聯網公司數據庫實際軟件架構是(大數據量下):又分片,又分組(如下圖)
數據分片是按照某個維度將存放在單一數據庫中的數據分散地存放至多個數據庫或表中以達到提升性能瓶頸以及可用性的效果。
數據分片的拆分方式分為垂直分片和水平分片
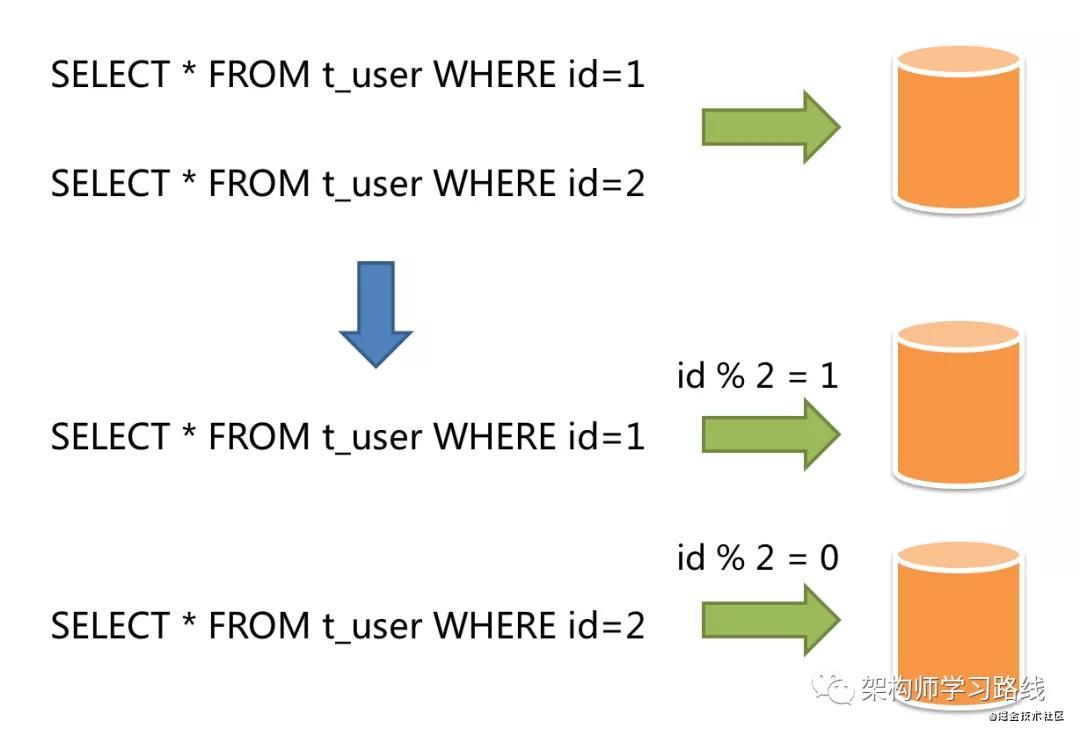
水平分片:是對于單表數據進行拆分.拆分標準也不再基于業務邏輯,而是將字段根據某種規則將數據分散到不同的表或庫中.每個分片只存儲一部分數據.常見的是根據主鍵分片.如:奇數放0庫,偶數放1庫.
優點:水平分片理論上突破了單機數據量處理的瓶頸,可以無限橫向擴展.是解決單機數據量和訪問量限制的終極方案.
缺點:
數據庫操作更繁重,數據定位繁瑣.
關聯操作(分組,聚合,分頁,排序等跨單元操作)需要特殊處理.
表名稱
因為數據庫切分是將整體數據,切分為多份存儲,這樣就產生了邏輯表和真實表的概念.
真實表:就是實際進行數據存儲的表.
邏輯表:就是原本數據單個數據庫中的表.即真實表的總和.如:真實表可能分為order_0,order_1,那么邏輯表就是order表,它表示了order表未被切分時的狀態.
分布式事務,跨庫join(查詢).
分表操作,如果要動態增加表時,如果采取hash的方式就存在rehash導致的數據遷移
垂直,水平分片是分布式數據庫架構方案.分庫,分表是實現方式,分庫既可以是垂直也可以是水平切分,分表也同樣可以有垂直,水平兩種切分方式.
讀寫分離
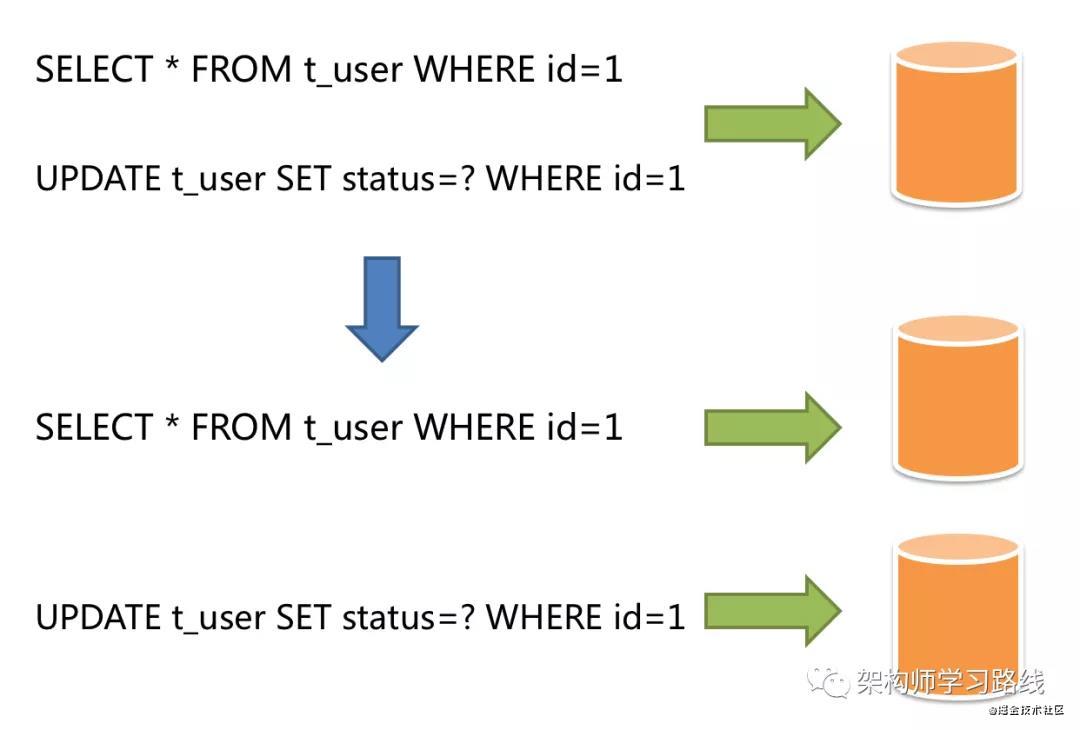
主從數據庫是解決數據庫單點問題的簡單方案,即根據讀寫操作上區分數據庫職責,以降低單一數據庫的訪問壓力.
應用場景:針對于讀多寫少的系統,通過拆分更新操作和查詢操作,來避免數據更新導致的行鎖,提高整個系統的查詢性能.
一主多從:分散查詢請求,進一步提高查詢性能.存在單點問題.
多主多從:提升系統吞吐量,可用性
存在問題:數據不一致.主庫之間,主庫和從庫之間.
如:主鍵一致性問題.為了高可用,會進行多主部署,如果表主鍵采取auto_increment,且主庫雙向同步,a庫入庫數據后,與b庫同步數據如果出現問題,b庫入庫數據后,再進行ab庫數據同步就可能存在主鍵沖突的問題.
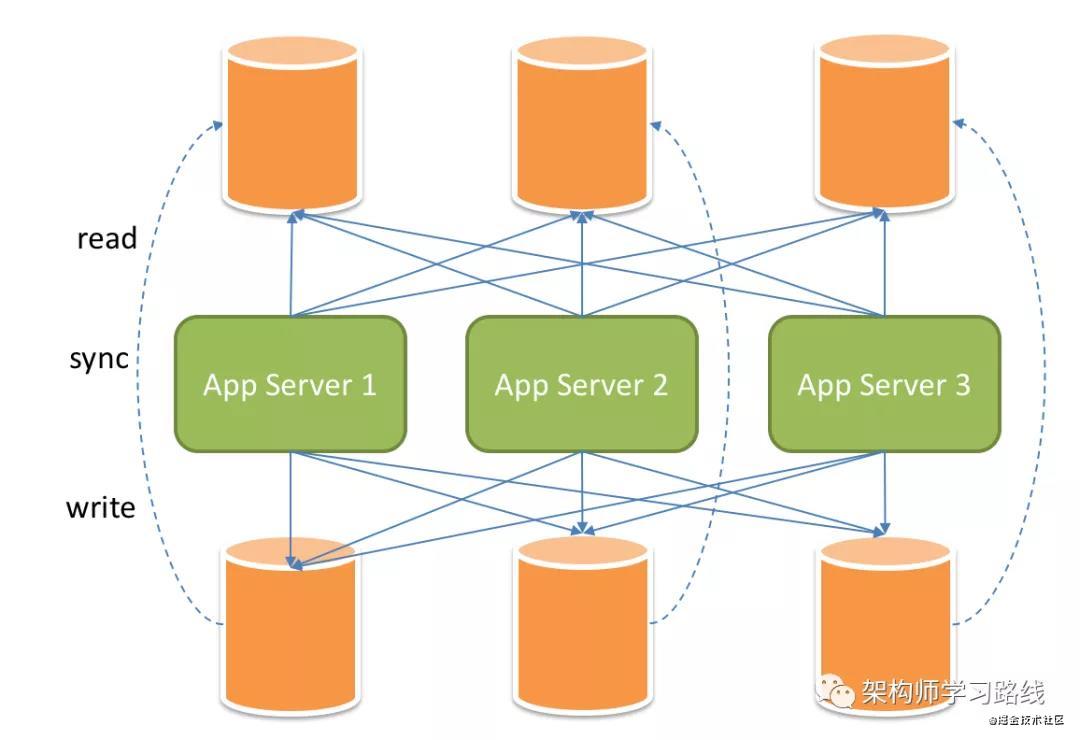
主從數據一致性原理:
主庫用于寫,更新操作;從庫用于數據讀取操作.當主從數據庫數據同步存在延遲時,就會造成主從數據庫的一致性問題.
主庫->寫->binlog->IO線程->從庫
延遲原因:從庫讀取binlog時,會串行執行sql,而主庫是并行執行sql;主庫故障造成未寫入binlog
解決方案:
1 降低從庫讀取壓力.做法:分庫,增加從庫機器配置,增加從庫機器(一主多從),增加服務緩存
2 直連主庫.會造成主存數據庫失去意義.
ShardingSphere在同一個線程且同一個數據庫連接進行寫操作時,會采取直連主庫的方式,避免數據不一致的問題.
主要處理方式如下:
忽略
實際寫少讀多的應用,看你的業務是否允許一定程度的數據不一致.感覺像招投標這種行業,對于數據沒有這么強的一致性要求.實際的技術選型總會對于準確和便捷做出一些妥協.
強制讀主庫
對于數據實時性要求較高的根本做法還是去讀主庫,因為主庫的數據才會沒有延遲的問題.從庫數據讀取
選擇性讀主
通過緩存來記錄數據庫,表,主鍵,消息有效期(主從同步時延)
增加集中式緩存
數據入庫時先將數據存入緩存.這個時候pc端存入數據,移動端登陸時去緩存中可以取到對應的訂單數據.這種做法存在熱點數據問題.
到此,關于“分布式數據庫的基本概念”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。