溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Python如何制作詞云”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Python如何制作詞云”吧!
效果如下:

(詞云--出現頻率越多的詞,字體越大 )
1、安裝可視化庫
pip3 install matplotlib

3、安裝 “結巴” 庫, 這個名字起的真接地氣, 給開發者點個贊
pip3 install jieba
這個庫用來解析中文,把一句話解析成一個個的詞,
我們中文不像英文每個詞之間有空格。需要根據語義分析拆分成詞組
我們用《劍雨》的一段對話舉例:
import jieba #引入結巴庫 str='師傅,他為何說禪機已到,\ 佛祖點化世人講究機緣,\ 禪機一過緣即滅矣,\ 而禪機未到雖點亦不中 我愿化身石橋又是何意' print(str) # 解析拆分詞組 lcut的方法 words = jieba.lcut(str) print(words)
效果如下:
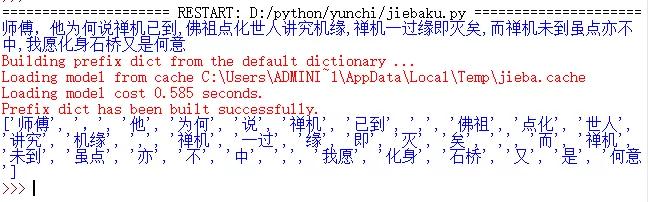
( 把完整的句子拆分成一個個的詞,看著斷斷續續,可能這就是結巴的由來吧,【拆詞】最難的這部分,結巴庫都做好了,這也是python強大的原因吧,各式各樣的庫都有了 )
網上下載txt格式的《西游記》,
下載完成后轉換成utf-8格式再保存一下。
轉化方法:記事本另存為的時候,選擇編碼格式UTF-8

format 格式化輸出:
#列標題 format
print("{0:<5}{1:<8}{2:<5}".format('序號','詞語', '頻率')){0:<5} :
0 表示序號:第一個參數,第一列,
< 左對齊, > 右對齊
5 代表寬度
任務一:統計西游記里面出現頻率最高的10個詞:
后面為了方便,我們把這個叫主代碼。
#引入結巴庫
import jieba
#open 內置函數 不需要引用 直接使用
#開打文件西游記和python 文件放到同一個目錄,可直接引用不需要路徑
f = open('西游記.txt', 'r' ,encoding='utf-8' )
# 查看文件的編碼格式
print('文件的編碼格式:'+f.encoding)
#讀取文件
txt = f.read()
#關閉文件,良好的習慣
f.close()
# 使用精確模式對文本進行分詞
# 使用結巴庫把西游拆分成一個個的詞組
words = jieba.lcut(txt)
# 通過鍵值對的形式存儲詞語及其出現的次數
# 大括號表示 python的字典類型對應,
# 鍵值對 key:value1 ,類似java的map對象和list
counts = {}
chiyun = []
for word in words:
# == 1 單個詞語不計算在內
if len(word) < 2 :
continue
else:
# 遍歷所有詞語,每出現一次其對應的值加 1
counts[word] = counts.get(word, 0) + 1
#將鍵值對轉換成列表
items = list(counts.items())
# 根據詞語出現的次數進行從大到小排序
items.sort(key=lambda x: x[1], reverse=True)
#列標題 format
print("{0:<5}{1:<8}{2:<5}".format('序號','詞語', '頻率'))
#需要顯示的范圍 10即顯示前10個,0到9
for i in range(10):
word, count = items[i]
print("{0:<5}{1:<8}{2:>5}".format(i+1,word, count))效果如下:
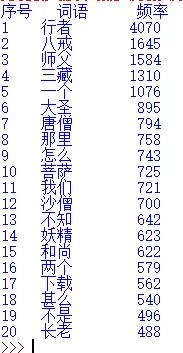
還是沒有觀音, 放出前100,200,300 到500在看:
終于出現了,在349位,重復61次,
應該是有哪里問題,直覺判斷不止61次重復

預知后事如何,請聽下回分解,‘下回分解’排第二合理。
悟空每次打妖怪都要吹下牛,在洞口報個名:我是五百年前大鬧天宮的齊天大圣,這兩個詞出現在前10 合理。
我們在梳理下流程:
注意下:結巴庫不是必須,主要是用來把句子拆分成詞,如果你已經有統計好的詞組,可直接用詞云顯示。
試一個簡單的:我們手工創建個詞組,直接用詞云顯示出來。即繞開結巴庫了
from wordcloud import WordCloud
# python的可視化庫,也是二級考試推薦的可視化庫
import matplotlib.pyplot as plt
str=['齊天大圣','大圣','大圣','八戒','嫦娥']
#數組里面添加內容
str.append('玉兔')
str.append('女兒國')
str.append('牛魔王')
str.append('大圣')
str.append('土地公公')
str.append('小神仙')
str.append('八戒')
print(str)
#join 函數 用斜桿拼接詞組mask =maskph,
#這里一定要join拼接一下 轉成字符串
text_cut = '/'.join(str)
#看一下連接后的樣子
#關鍵點 text_cut 是詞云要處理的內容
print(text_cut)
wordcloud = WordCloud( background_color='white',font_path = 'msyh.ttc', width=1000, height=860, margin=2).generate(text_cut)
# 顯示圖片
plt.imshow(wordcloud)
plt.axis('off')
plt.show()可觀察下效果圖:主要join后的輸出,用/拼接成了一個字符串:

效果圖:
(大圣和八戒出現次數多,字體最大)
先把全代碼放上,后面實例在解析:
這段可先略過,下面直接看效果圖:
#引入結巴庫
import jieba
#詞云庫
from wordcloud import WordCloud
# python的可視化庫,也是二級考試推薦的可視化庫
import matplotlib.pyplot as plt
from PIL import Image #處理圖片的
#矩陣 好像也是協助處理圖片的
import numpy as np
#open 內置函數 不需要引用 直接使用
#開打文件西游記和python 文件放到同一個目錄,可直接引用不需要路徑
f = open('西游記.txt', 'r' ,encoding='utf-8' )
# 查看文件的編碼格式
print('文件的編碼格式:'+f.encoding)
#讀取文件
txt = f.read()
#關閉文件,良好的習慣
f.close()
# 使用精確模式對文本進行分詞
# 使用結巴庫把西游拆分成一個個的詞組
words = jieba.lcut(txt)
# 通過鍵值對的形式存儲詞語及其出現的次數
# 大括號表示 python的字典類型對應,
# 鍵值對 key:value1 ,類似java的map對象和list
counts = {}
#數組對象 用來接收需要傳遞給詞云的內容
chiyun = []
for word in words:
# == 1 單個詞語不計算在內
if len(word) < 2 :
continue
else:
# 遍歷所有詞語,每出現一次其對應的值加 1
counts[word] = counts.get(word, 0) + 1
#將鍵值對轉換成列表
items = list(counts.items())
# 根據詞語出現的次數進行從大到小排序
items.sort(key=lambda x: x[1], reverse=True)
#列標題 format
print("{0:<5}{1:<8}{2:<5}".format('序號','詞語', '頻率'))
#需要顯示的范圍 10即顯示前10個,0到9
for i in range(80):
word, count = items[i]
print("{0:<5}{1:<8}{2:>5}".format(i+1,word, count))
chiyun.append(word)
#print(chiyun)
#加載圖片信息
maskph = np.array(Image.open('山東艦航母.png'))
#join 函數 用斜桿拼接詞組
text_cut = '/'.join(chiyun)
wordcloud = WordCloud(mask =maskph, background_color='white',font_path = 'msyh.ttc', width=1000, height=860, margin=2).generate(text_cut)
# 顯示圖片
plt.imshow(wordcloud)
plt.axis('off')
plt.show()效果1:全部顯示
即:結巴庫處理好的詞組,不做限制,全部送給詞云顯示:

顯示二:限定內容顯示
比如改成 只輸出前20個詞:(顯示密度會稀好多)
即:結巴庫處理好后,取前20個高頻詞傳給詞云顯示:
再試一下前20的 四個字的詞:

到此,相信大家對“Python如何制作詞云”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





