溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
在自己的掃描器開發過程中,掃描器當中自然包括了子域名收集功能,但在遇到泛解析的網站時,也增加了掃描器很多不必要的檢測,導致效率和資源的浪費。本文中主要針對掃描器遇到的問題進行解決并優化。
泛域名解析介紹 https://baike.baidu.com/item/%E6%B3%9B%E5%9F%9F%E5%90%8D%E8%A7%A3%E6%9E%90/9845966?fr=aladdin
泛解析的功能為廠商提供了便利,但為自動化掃描帶來了麻煩,什么麻煩呢?這里以一個使用了泛解析的廠商作為演示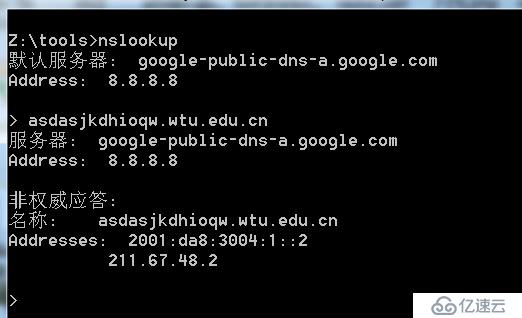
由于該網站使用了泛解析,導致原本不存在的子域名也會成功被解析,那么其實訪問這個域名,會重定向到主頁
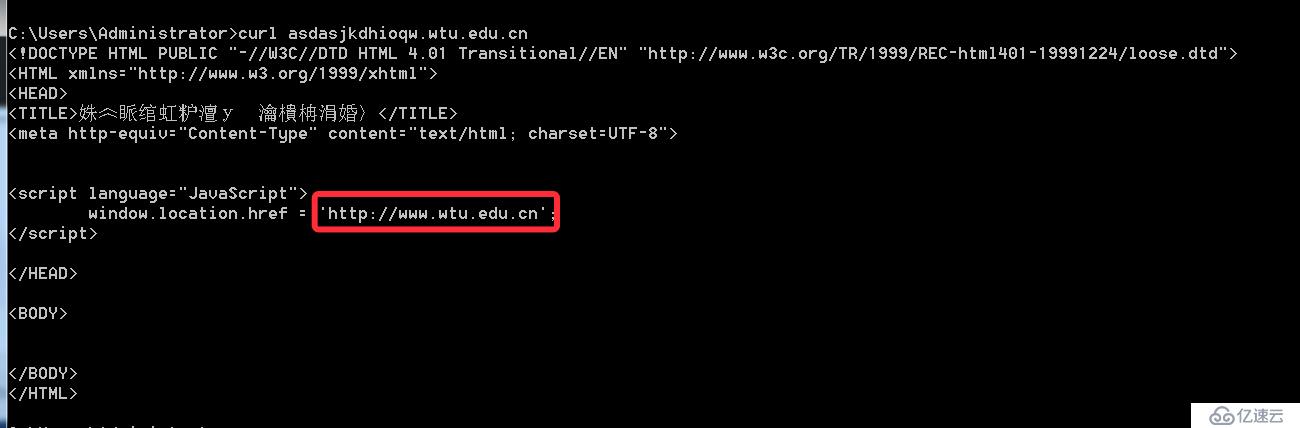
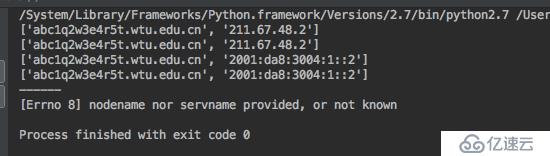
那么在自動化掃描中,通常我們會使用到一個字典組合域名的方式,然后進行dns解析,如果成功解析說明子域名存在,利用這種方式來進行子域名窮舉,但使用泛解析的話,則會導致所有的域名都能成功解析,使得子域名窮舉變得不精準。
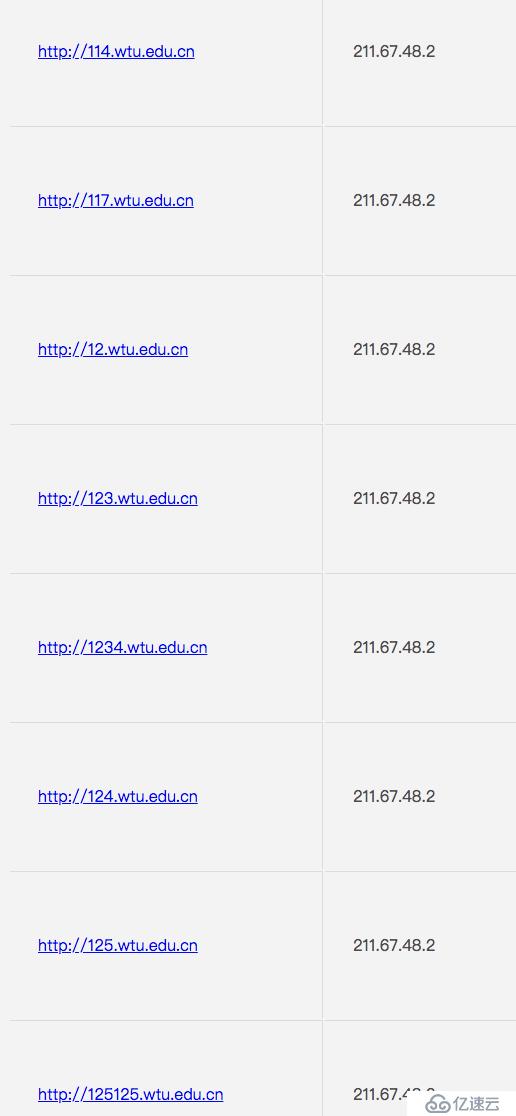
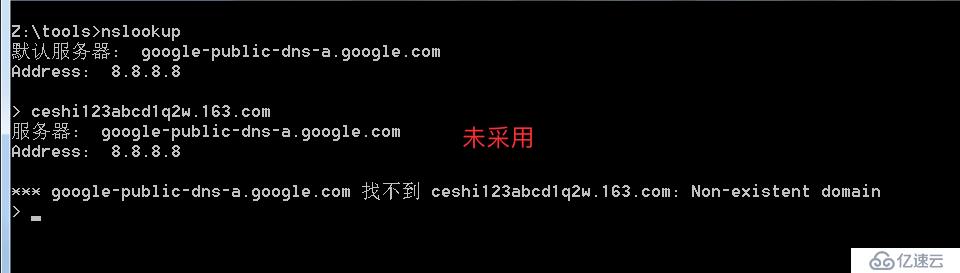
ps:只是一個泛解析測試
那么怎么去判斷域名使用了泛解析和如何解決掃描器中遇到這種情況呢?
泛解析的域名會自動匹配所有*.域名的解析,利用這點我們可以故意去解析一個根本不可能存在的域名,如果能成功解析代表使用泛解析,否之未采用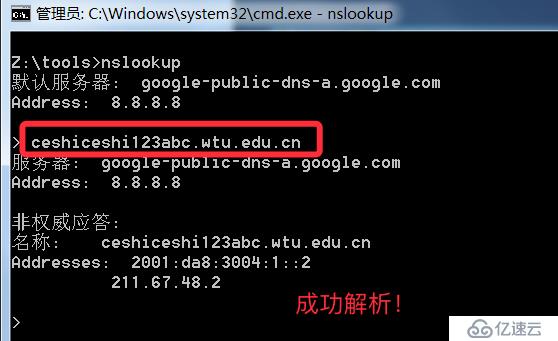
import socket
import sys
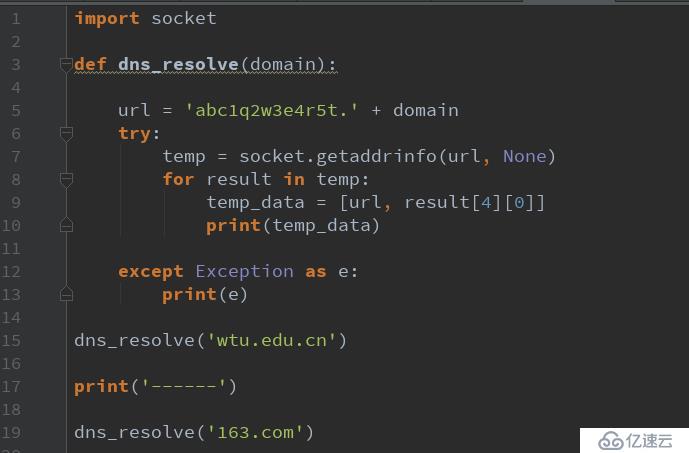
def dns_resolve(domain):
url = 'abc1q2w3e4r5t.' + domain
flag = False
#拋出異常說明使用了泛解析
try:
socket.getaddrinfo(url, None)
flag = True
except:
pass
if not flag:
print('[+] %s 未采用泛解析'%domain)
else:
print('[-] %s 采用泛解析'%domain)
if __name__ == '__main__':
if len(sys.argv) < 2:
print('python3 %s <domain>'%sys.argv[0])
exit(1)
dns_resolve(sys.argv[1])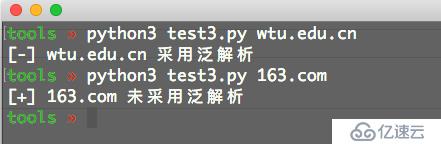
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





