溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“怎么用Python數據分析員工們的工作效率和整體滿意度”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“怎么用Python數據分析員工們的工作效率和整體滿意度”吧!
項目背景
2018年,被稱為互聯網的寒冬之年。無論大小公司,紛紛走上了裁員之路,還有一些比較慘的,直接關門大吉。2019年上半年,甲骨文裁掉大量35歲左右的程序員,誰也沒想到,IT界退休年齡這么早!而內心OS:我的房貸還沒還清。。。。
假設你是人力資源總監,你該向誰開刀呢?先回答一下下面的問題。
各部門有多少名員工?
員工總體流失率是多少?
員工平均薪資是多少?
員工平均工作年限是多少?
公司任職時間最久的3名員工是誰?
員工整體滿意度如何?
import pandas as pd data = pd.read_excel(r'c:\Users\Administrator\Desktop\英雄聯盟員工信息表.xlsx',index_col = u'工號') # 訪問columns屬性,查看列字段 data.columns # 訪問index屬性,查看行標記 data.index # 訪問values屬性,查看數據集 data.values
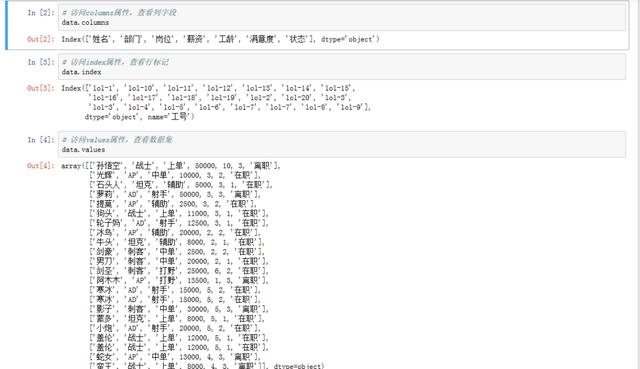
# 對元數據集增加一列獎金列,數額為薪資的20% data[u'獎金'] = data[u'薪資']*0.2 data[u'獎金'].head() # loc方法,根據索引列訪問數據集 idx = ['lol-1','lol-2','lol-3','lol-7'] data.loc[idx]
# 對元數據集增加一列獎金列,數額為薪資的20% data[u'獎金'] = data[u'薪資']*0.2 data[u'獎金'].head() # loc方法,根據索引列訪問數據集 idx = ['lol-1','lol-2','lol-3','lol-7'] data.loc[idx]
此時,我們在上述結果中發現:寒冰、蓋倫是重復數據條,在數據分析過程中,一定要注意重復數據帶來的影響,所以我們要進行去重操作。
# 查看重復數據條(bool結果為True代表重復) data.duplicated() # 查看有多少條重復數據 data.duplicated().sum() # 結果:2 # 查看重復數據 data[data.duplicated()] # 刪除重復數據條,inplace參數代表是否在元數據集進行刪除,True表示是 data.drop_duplicates(inplace=True) # 再次查看是否全部去重 data.duplicated().sum() # 結果:0,說明數據已經唯一
1.各部門有多少名員工?
# 頻數統計 data[u'部門'].value_counts() # ascending = True代表升序展示 data[u'部門'].value_counts(ascending = True)
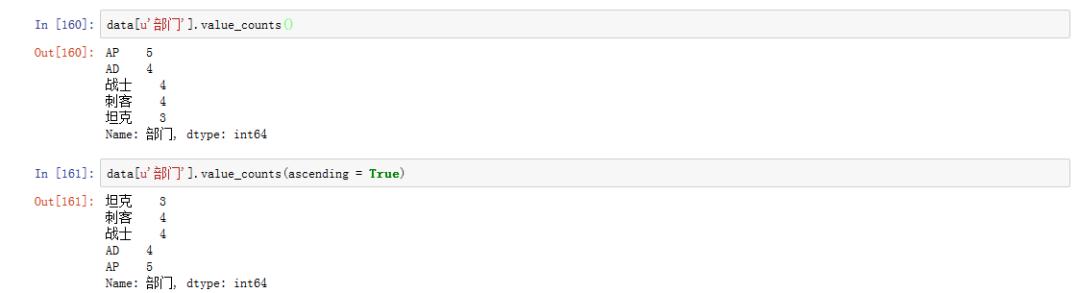
2.員工總體流失率是多少?
# 頻數統計 data[u'狀態'].value_counts() # normalize = True 獲得標準化計數結果 data[u'狀態'].value_counts(normalize = True) # 展示出員工總體流失率 rate = data[u'狀態'].value_counts(normalize = True)[u'離職'] rate
3.員工平均薪資是多少?

由上圖的結果可以看出,平均薪資在16800元,你達到了嗎?!允許你去哭一會o(╥﹏╥)o!
4.公司任職時間最久的3名員工是誰?
# describe方法也是常用的一種方法,而且結果更全面。 data[u'工齡'].describe() # 通過降序排序、切片操作,找到待的最久的三名員工 data[u'工齡'].sort_values(ascending = False)[:3] ID = data[u'工齡'].sort_values(ascending = False)[:3].index data.loc[ID]
6.員工整體滿意度如何?
data[u'滿意度'].head()
# 通過查看滿意度前五行發現,不太直觀,我們可以用map進行映射,先建立一個映射字典
JobSatisfaction_cat = {
1:'非常滿意',
2:'一般般吧',
3:'勞資不爽'
}
data[u'滿意度'].map(JobSatisfaction_cat)
# 對元數據集進行滿意度映射
data[u'滿意度'] = data[u'滿意度'].map(JobSatisfaction_cat)
data[u'滿意度'].head()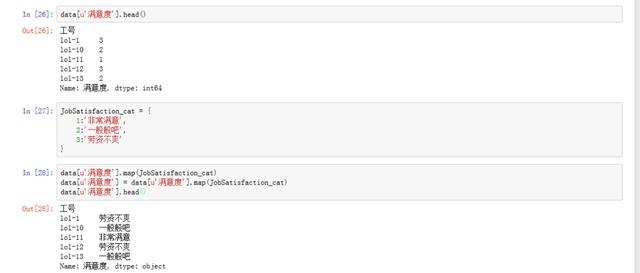
接下來,進行員工整體滿意度分析。通過計算可以得出:70%員工都比較認可公司,但仍有30%員工對公司不滿意。人力主管以及部門主管需要進一步探究清楚這30%員工的情況,因為不滿意是否已經離職?還是存在隱患?是否處于核心崗位等等問題值得我們進一步探究。
data.head() # 頻數統計 data[u'滿意度'].value_counts() # 獲得標準化計數結果,考慮到百分比更能說明滿意度情況,所以乘100展示 100*data[u'滿意度'].value_counts(normalize = True)
感謝各位的閱讀,以上就是“怎么用Python數據分析員工們的工作效率和整體滿意度”的內容了,經過本文的學習后,相信大家對怎么用Python數據分析員工們的工作效率和整體滿意度這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





